 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Motion Generation via Diffusion Modal Coupling
Mar 04, 2025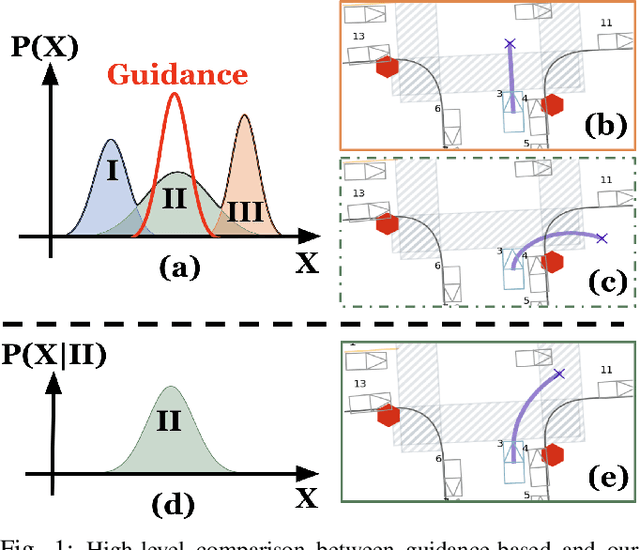
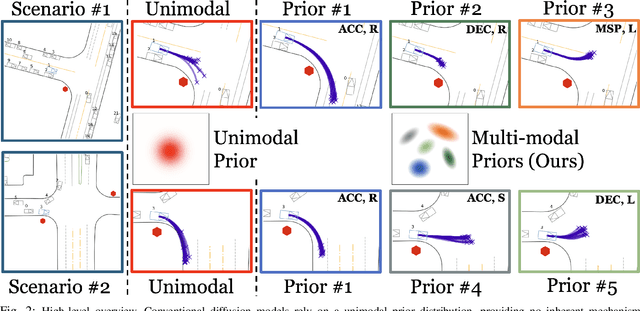
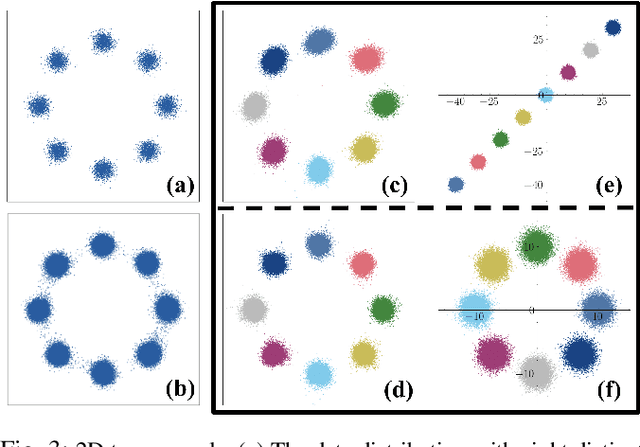
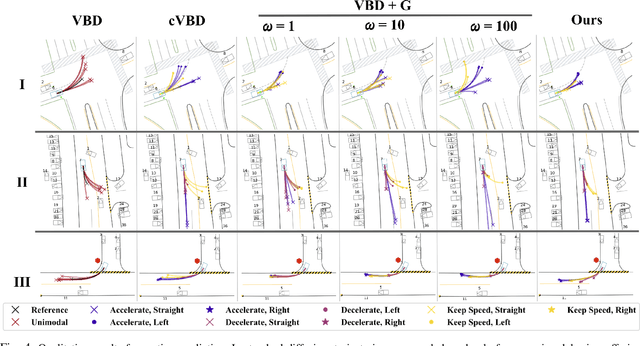
Diffusion models have recently gained significant attention in robotics due to their ability to generate multi-modal distributions of system states and behaviors. However, a key challenge remains: ensuring precise control over the generated outcomes without compromising realism. This is crucial for applications such as motion planning or trajectory forecasting, where adherence to physical constraints and task-specific objectives is essential. We propose a novel framework that enhances controllability in diffusion models by leveraging multi-modal prior distributions and enforcing strong modal coupling. This allows us to initiate the denoising process directly from distinct prior modes that correspond to different possible system behaviors, ensuring sampling to align with the training distribution. We evaluate our approach on motion prediction using the Waymo dataset and multi-task control in Maze2D environments. Experimental results show that our framework outperforms both guidance-based techniques and conditioned models with unimodal priors, achieving superior fidelity, diversity, and controllability, even in the absence of explicit conditioning. Overall, our approach provides a more reliable and scalable solution for controllable motion generation in robotics.
A Real2Sim2Real Method for Robust Object Grasping with Neural Surface Reconstruction
Oct 06, 2022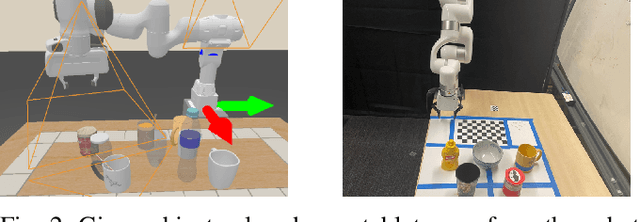
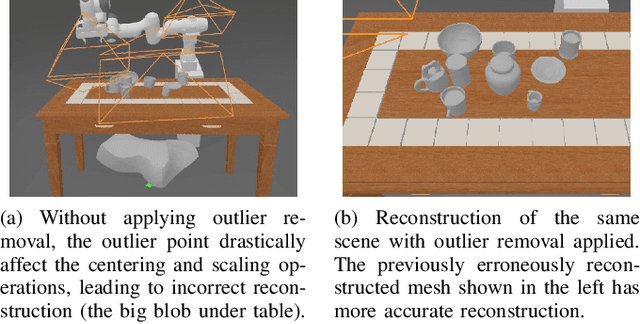


Recent 3D-based manipulation methods either directly predict the grasp pose using 3D neural networks, or solve the grasp pose using similar objects retrieved from shape databases. However, the former faces generalizability challenges when testing with new robot arms or unseen objects; and the latter assumes that similar objects exist in the databases. We hypothesize that recent 3D modeling methods provides a path towards building digital replica of the evaluation scene that affords physical simulation and supports robust manipulation algorithm learning. We propose to reconstruct high-quality meshes from real-world point clouds using state-of-the-art neural surface reconstruction method (the Real2Sim step). Because most simulators take meshes for fast simulation, the reconstructed meshes enable grasp pose labels generation without human efforts. The generated labels can train grasp network that performs robustly in the real evaluation scene (the Sim2Real step). In synthetic and real experiments, we show that the Real2Sim2Real pipeline performs better than baseline grasp networks trained with a large dataset and a grasp sampling method with retrieval-based reconstruction. The benefit of the Real2Sim2Real pipeline comes from 1) decoupling scene modeling and grasp sampling into sub-problems, and 2) both sub-problems can be solved with sufficiently high quality using recent 3D learning algorithms and mesh-based physical simulation techniques.