 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeSwift: Accelerating LLM Inference for Efficient Code Generation
Feb 24, 2025



Code generation is a latency-sensitive task that demands high timeliness, but the autoregressive decoding mechanism of Large Language Models (LLMs) leads to poor inference efficiency. Existing LLM inference acceleration methods mainly focus on standalone functions using only built-in components. Moreover, they treat code like natural language sequences, ignoring its unique syntax and semantic characteristics. As a result, the effectiveness of these approaches in code generation tasks remains limited and fails to align with real-world programming scenarios. To alleviate this issue, we propose CodeSwift, a simple yet highly efficient inference acceleration approach specifically designed for code generation, without comprising the quality of the output. CodeSwift constructs a multi-source datastore, providing access to both general and project-specific knowledge, facilitating the retrieval of high-quality draft sequences. Moreover, CodeSwift reduces retrieval cost by controlling retrieval timing, and enhances efficiency through parallel retrieval and a context- and LLM preference-aware cache. Experimental results show that CodeSwift can reach up to 2.53x and 2.54x speedup compared to autoregressive decoding in repository-level and standalone code generation tasks, respectively, outperforming state-of-the-art inference acceleration approaches by up to 88%.
Accelerating Diffusion Transformers with Dual Feature Caching
Dec 25, 2024



Diffusion Transformers (DiT) have become the dominant methods in image and video generation yet still suffer substantial computational costs. As an effective approach for DiT acceleration, feature caching methods are designed to cache the features of DiT in previous timesteps and reuse them in the next timesteps, allowing us to skip the computation in the next timesteps. However, on the one hand, aggressively reusing all the features cached in previous timesteps leads to a severe drop in generation quality. On the other hand, conservatively caching only the features in the redundant layers or tokens but still computing the important ones successfully preserves the generation quality but results in reductions in acceleration ratios. Observing such a tradeoff between generation quality and acceleration performance, this paper begins by quantitatively studying the accumulated error from cached features. Surprisingly, we find that aggressive caching does not introduce significantly more caching errors in the caching step, and the conservative feature caching can fix the error introduced by aggressive caching. Thereby, we propose a dual caching strategy that adopts aggressive and conservative caching iteratively, leading to significant acceleration and high generation quality at the same time. Besides, we further introduce a V-caching strategy for token-wise conservative caching, which is compatible with flash attention and requires no training and calibration data. Our codes have been released in Github: \textbf{Code: \href{https://github.com/Shenyi-Z/DuCa}{\texttt{\textcolor{cyan}{https://github.com/Shenyi-Z/DuCa}}}}
A Real2Sim2Real Method for Robust Object Grasping with Neural Surface Reconstruction
Oct 06, 2022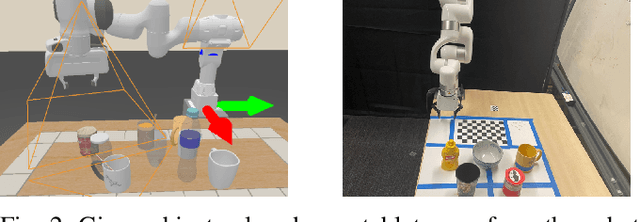
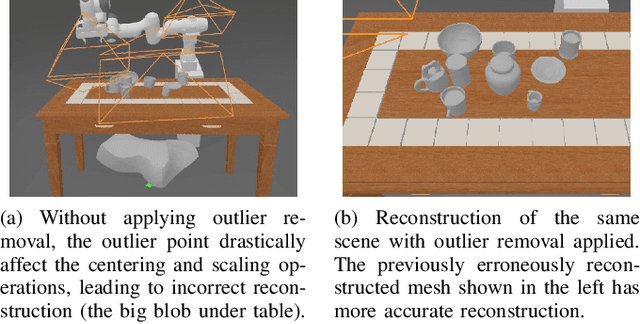


Recent 3D-based manipulation methods either directly predict the grasp pose using 3D neural networks, or solve the grasp pose using similar objects retrieved from shape databases. However, the former faces generalizability challenges when testing with new robot arms or unseen objects; and the latter assumes that similar objects exist in the databases. We hypothesize that recent 3D modeling methods provides a path towards building digital replica of the evaluation scene that affords physical simulation and supports robust manipulation algorithm learning. We propose to reconstruct high-quality meshes from real-world point clouds using state-of-the-art neural surface reconstruction method (the Real2Sim step). Because most simulators take meshes for fast simulation, the reconstructed meshes enable grasp pose labels generation without human efforts. The generated labels can train grasp network that performs robustly in the real evaluation scene (the Sim2Real step). In synthetic and real experiments, we show that the Real2Sim2Real pipeline performs better than baseline grasp networks trained with a large dataset and a grasp sampling method with retrieval-based reconstruction. The benefit of the Real2Sim2Real pipeline comes from 1) decoupling scene modeling and grasp sampling into sub-problems, and 2) both sub-problems can be solved with sufficiently high quality using recent 3D learning algorithms and mesh-based physical simulation techniques.
Single RGB-D Camera Teleoperation for General Robotic Manipulation
Jun 30, 2021

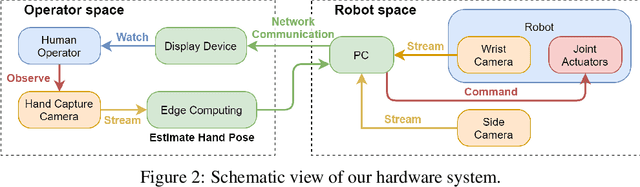

We propose a teleoperation system that uses a single RGB-D camera as the human motion capture device. Our system can perform general manipulation tasks such as cloth folding, hammering and 3mm clearance peg in hole. We propose the use of non-Cartesian oblique coordinate frame, dynamic motion scaling and reposition of operator frames to increase the flexibility of our teleoperation system. We hypothesize that lowering the barrier of entry to teleoperation will allow for wider deployment of supervised autonomy system, which will in turn generates realistic datasets that unlock the potential of machine learning for robotic manipulation.