 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeSwift: Accelerating LLM Inference for Efficient Code Generation
Feb 24, 2025



Code generation is a latency-sensitive task that demands high timeliness, but the autoregressive decoding mechanism of Large Language Models (LLMs) leads to poor inference efficiency. Existing LLM inference acceleration methods mainly focus on standalone functions using only built-in components. Moreover, they treat code like natural language sequences, ignoring its unique syntax and semantic characteristics. As a result, the effectiveness of these approaches in code generation tasks remains limited and fails to align with real-world programming scenarios. To alleviate this issue, we propose CodeSwift, a simple yet highly efficient inference acceleration approach specifically designed for code generation, without comprising the quality of the output. CodeSwift constructs a multi-source datastore, providing access to both general and project-specific knowledge, facilitating the retrieval of high-quality draft sequences. Moreover, CodeSwift reduces retrieval cost by controlling retrieval timing, and enhances efficiency through parallel retrieval and a context- and LLM preference-aware cache. Experimental results show that CodeSwift can reach up to 2.53x and 2.54x speedup compared to autoregressive decoding in repository-level and standalone code generation tasks, respectively, outperforming state-of-the-art inference acceleration approaches by up to 88%.
Peer-aided Repairer: Empowering Large Language Models to Repair Advanced Student Assignments
Apr 02, 2024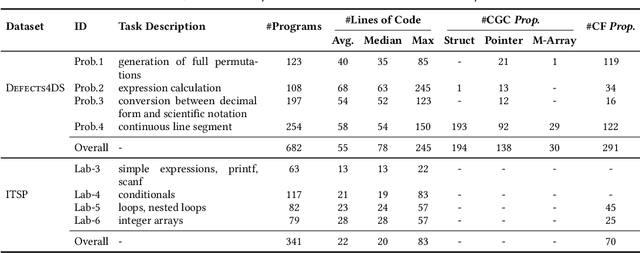
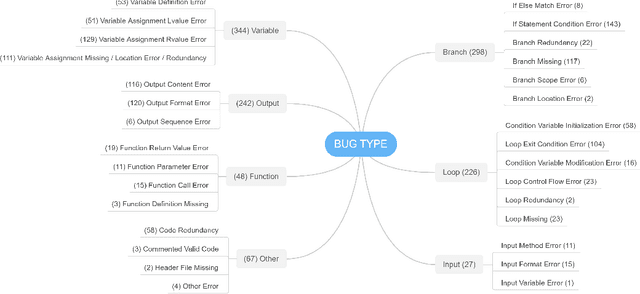
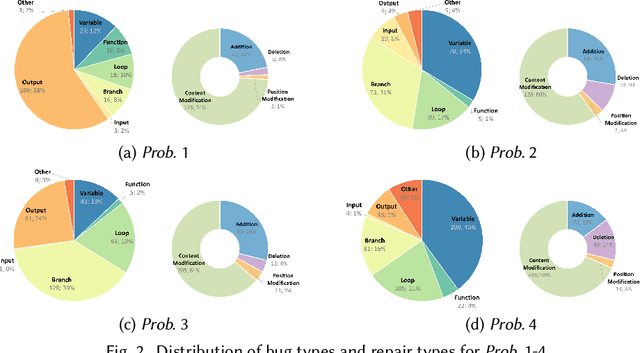
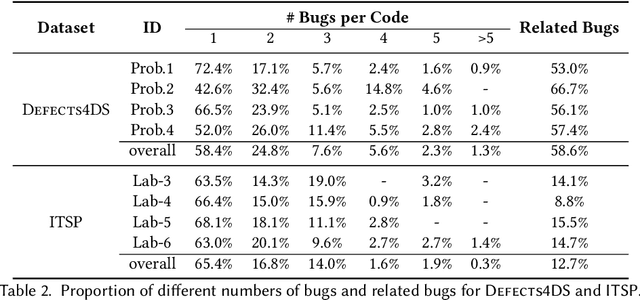
Automated generation of feedback on programming assignments holds significant benefits for programming education, especially when it comes to advanced assignments. Automated Program Repair techniques, especially Large Language Model based approaches, have gained notable recognition for their potential to fix introductory assignments. However, the programs used for evaluation are relatively simple. It remains unclear how existing approaches perform in repairing programs from higher-level programming courses. To address these limitations, we curate a new advanced student assignment dataset named Defects4DS from a higher-level programming course. Subsequently, we identify the challenges related to fixing bugs in advanced assignments. Based on the analysis, we develop a framework called PaR that is powered by the LLM. PaR works in three phases: Peer Solution Selection, Multi-Source Prompt Generation, and Program Repair. Peer Solution Selection identifies the closely related peer programs based on lexical, semantic, and syntactic criteria. Then Multi-Source Prompt Generation adeptly combines multiple sources of information to create a comprehensive and informative prompt for the last Program Repair stage. The evaluation on Defects4DS and another well-investigated ITSP dataset reveals that PaR achieves a new state-of-the-art performance, demonstrating impressive improvements of 19.94% and 15.2% in repair rate compared to prior state-of-the-art LLM- and symbolic-based approaches, respectively