 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Vector Quantization for Rate-Distortion Optimization of Generative Image Compression
Apr 12, 2026The rapid growth of visual data under stringent storage and bandwidth constraints makes extremely low-bitrate image compression increasingly important. While Vector Quantization (VQ) offers strong structural fidelity, existing methods lack a principled mechanism for joint rate-distortion (RD) optimization due to the disconnect between representation learning and entropy modeling. We propose RDVQ, a unified framework that enables end-to-end RD optimization for VQ-based compression via a differentiable relaxation of the codebook distribution, allowing the entropy loss to directly shape the latent prior. We further develop an autoregressive entropy model that supports accurate entropy modeling and test-time rate control. Extensive experiments demonstrate that RDVQ achieves strong performance at extremely low bitrates with a lightweight architecture, attaining competitive or superior perceptual quality with significantly fewer parameters. Compared with RDEIC, RDVQ reduces bitrate by up to 75.71% on DISTS and 37.63% on LPIPS on DIV2K-val. Beyond empirical gains, RDVQ introduces an entropy-constrained formulation of VQ, highlighting the potential for a more unified view of image tokenization and compression. The code will be available at https://github.com/CVL-UESTC/RDVQ.
Device-Conditioned Neural Architecture Search for Efficient Robotic Manipulation
Apr 11, 2026The growing complexity of visuomotor policies poses significant challenges for deployment with heterogeneous robotic hardware constraints. However, most existing model-efficient approaches for robotic manipulation are device- and model-specific, lack generalizability, and require time-consuming per-device optimization during the adaptation process. In this work, we propose a unified framework named \textbf{D}evice-\textbf{C}onditioned \textbf{Q}uantization-\textbf{F}or-\textbf{A}ll (DC-QFA) which amortizes deployment effort with the device-conditioned quantization-aware training and hardware-constrained architecture search. Specifically, we introduce a single supernet that spans a rich design space over network architectures and mixed-precision bit-widths. It is optimized with latency- and memory-aware regularization, guided by per-device lookup tables. With this supernet, for each target platform, we can perform a once-for-all lightweight search to select an optimal subnet without any per-device re-optimization, which enables more generalizable deployment across heterogeneous hardware, and substantially reduces deployment time. To improve long-horizon stability under low precision, we further introduce multi-step on-policy distillation to mitigate error accumulation during closed-loop execution. Extensive experiments on three representative policy backbones, such as DiffusionPolicy-T, MDT-V, and OpenVLA-OFT, demonstrate that our DC-QFA achieves $2\text{-}3\times$ acceleration on edge devices, consumer-grade GPUs, and cloud platforms, with negligible performance drop in task success. Real-world evaluations on an Inovo robot equipped with a force/torque sensor further validates that our low-bit DC-QFA policies maintain stable, contact-rich manipulation even under severe quantization.
Generative 3D Gaussian Splatting for Arbitrary-ResolutionAtmospheric Downscaling and Forecasting
Apr 09, 2026While AI-based numerical weather prediction (NWP) enables rapid forecasting, generating high-resolution outputs remains computationally demanding due to limited multi-scale adaptability and inefficient data representations. We propose the 3D Gaussian splatting-based scale-aware vision transformer (GSSA-ViT), a novel framework for arbitrary-resolution forecasting and flexible downscaling of high-dimensional atmospheric fields. Specifically, latitude-longitude grid points are treated as centers of 3D Gaussians. A generative 3D Gaussian prediction scheme is introduced to estimate key parameters, including covariance, attributes, and opacity, for unseen samples, improving generalization and mitigating overfitting. In addition, a scale-aware attention module is designed to capture cross-scale dependencies, enabling the model to effectively integrate information across varying downscaling ratios and support continuous resolution adaptation. To our knowledge, this is the first NWP approach that combines generative 3D Gaussian modeling with scale-aware attention for unified multi-scale prediction. Experiments on ERA5 show that the proposed method accurately forecasts 87 atmospheric variables at arbitrary resolutions, while evaluations on ERA5 and CMIP6 demonstrate its superior performance in downscaling tasks. The proposed framework provides an efficient and scalable solution for high-resolution, multi-scale atmospheric prediction and downscaling. Code is available at: https://github.com/binbin2xs/weather-GS.
EgoMind: Activating Spatial Cognition through Linguistic Reasoning in MLLMs
Apr 01, 2026Multimodal large language models (MLLMs) are increasingly being applied to spatial cognition tasks, where they are expected to understand and interact with complex environments. Most existing works improve spatial reasoning by introducing 3D priors or geometric supervision, which enhances performance but incurs substantial data preparation and alignment costs. In contrast, purely 2D approaches often struggle with multi-frame spatial reasoning due to their limited ability to capture cross-frame spatial relationships. To address these limitations, we propose EgoMind, a Chain-of-Thought framework that enables geometry-free spatial reasoning through Role-Play Caption, which jointly constructs a coherent linguistic scene graph across frames, and Progressive Spatial Analysis, which progressively reasons toward task-specific questions. With only 5K auto-generated SFT samples and 20K RL samples, EgoMind achieves competitive results on VSI-Bench, SPAR-Bench, SITE-Bench, and SPBench, demonstrating its effectiveness in strengthening the spatial reasoning capabilities of MLLMs and highlighting the potential of linguistic reasoning for spatial cognition. Code and data are released at https://github.com/Hyggge/EgoMind.
Generative Video Compression with One-Dimensional Latent Representation
Mar 16, 2026Recent advancements in generative video codec (GVC) typically encode video into a 2D latent grid and employ high-capacity generative decoders for reconstruction. However, this paradigm still leaves two key challenges in fully exploiting spatial-temporal redundancy: Spatially, the 2D latent grid inevitably preserves intra-frame redundancy due to its rigid structure, where adjacent patches remain highly similar, thereby necessitating a higher bitrate. Temporally, the 2D latent grid is less effective for modeling long-term correlations in a compact and semantically coherent manner, as it hinders the aggregation of common contents across frames. To address these limitations, we introduce Generative Video Compression with One-Dimensional (1D) Latent Representation (GVC1D). GVC1D encodes the video data into extreme compact 1D latent tokens conditioned on both short- and long-term contexts. Without the rigid 2D spatial correspondence, these 1D latent tokens can adaptively attend to semantic regions and naturally facilitate token reduction, thereby reducing spatial redundancy. Furthermore, the proposed 1D memory provides semantically rich long-term context while maintaining low computational cost, thereby further reducing temporal redundancy. Experimental results indicate that GVC1D attains superior compression efficiency, where it achieves bitrate reductions of 60.4\% under LPIPS and 68.8\% under DISTS on the HEVC Class B dataset, surpassing the previous video compression methods.Project: https://gvc1d.github.io/
LoD-Structured 3D Gaussian Splatting for Streaming Video Reconstruction
Jan 26, 2026Free-Viewpoint Video (FVV) reconstruction enables photorealistic and interactive 3D scene visualization; however, real-time streaming is often bottlenecked by sparse-view inputs, prohibitive training costs, and bandwidth constraints. While recent 3D Gaussian Splatting (3DGS) has advanced FVV due to its superior rendering speed, Streaming Free-Viewpoint Video (SFVV) introduces additional demands for rapid optimization, high-fidelity reconstruction under sparse constraints, and minimal storage footprints. To bridge this gap, we propose StreamLoD-GS, an LoD-based Gaussian Splatting framework designed specifically for SFVV. Our approach integrates three core innovations: 1) an Anchor- and Octree-based LoD-structured 3DGS with a hierarchical Gaussian dropout technique to ensure efficient and stable optimization while maintaining high-quality rendering; 2) a GMM-based motion partitioning mechanism that separates dynamic and static content, refining dynamic regions while preserving background stability; and 3) a quantized residual refinement framework that significantly reduces storage requirements without compromising visual fidelity. Extensive experiments demonstrate that StreamLoD-GS achieves competitive or state-of-the-art performance in terms of quality, efficiency, and storage.
IGDMRec: Behavior Conditioned Item Graph Diffusion for Multimodal Recommendation
Dec 23, 2025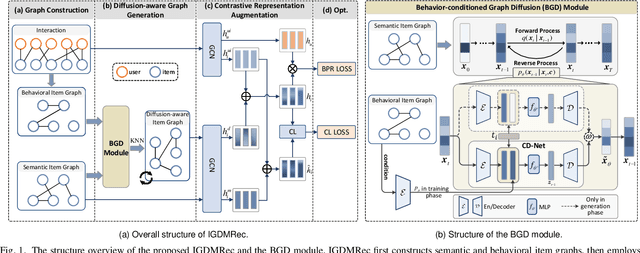
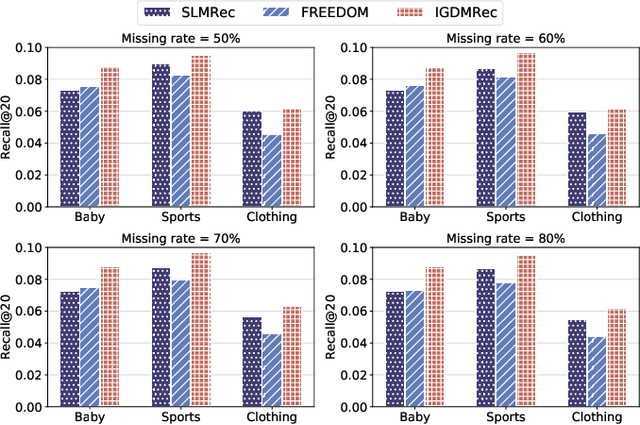
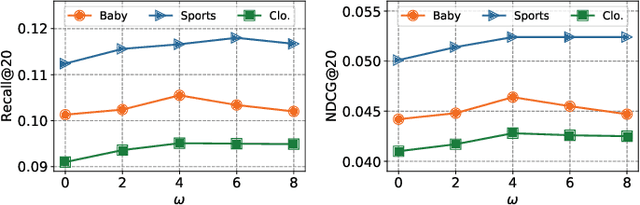
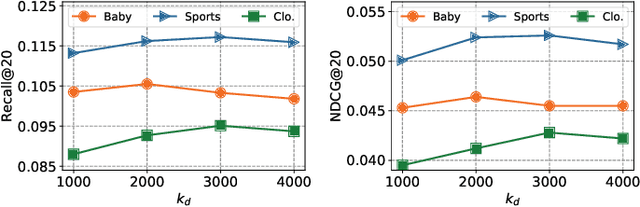
Multimodal recommender systems (MRSs) are critical for various online platforms, offering users more accurate personalized recommendations by incorporating multimodal information of items. Structure-based MRSs have achieved state-of-the-art performance by constructing semantic item graphs, which explicitly model relationships between items based on modality feature similarity. However, such semantic item graphs are often noisy due to 1) inherent noise in multimodal information and 2) misalignment between item semantics and user-item co-occurrence relationships, which introduces false links and leads to suboptimal recommendations. To address this challenge, we propose Item Graph Diffusion for Multimodal Recommendation (IGDMRec), a novel method that leverages a diffusion model with classifier-free guidance to denoise the semantic item graph by integrating user behavioral information. Specifically, IGDMRec introduces a Behavior-conditioned Graph Diffusion (BGD) module, incorporating interaction data as conditioning information to guide the denoising of the semantic item graph. Additionally, a Conditional Denoising Network (CD-Net) is designed to implement the denoising process with manageable complexity. Finally, we propose a contrastive representation augmentation scheme that leverages both the denoised item graph and the original item graph to enhance item representations. \LL{Extensive experiments on four real-world datasets demonstrate the superiority of IGDMRec over competitive baselines, with robustness analysis validating its denoising capability and ablation studies verifying the effectiveness of its key components.
Otter: Mitigating Background Distractions of Wide-Angle Few-Shot Action Recognition with Enhanced RWKV
Nov 11, 2025Wide-angle videos in few-shot action recognition (FSAR) effectively express actions within specific scenarios. However, without a global understanding of both subjects and background, recognizing actions in such samples remains challenging because of the background distractions. Receptance Weighted Key Value (RWKV), which learns interaction between various dimensions, shows promise for global modeling. While directly applying RWKV to wide-angle FSAR may fail to highlight subjects due to excessive background information. Additionally, temporal relation degraded by frames with similar backgrounds is difficult to reconstruct, further impacting performance. Therefore, we design the CompOund SegmenTation and Temporal REconstructing RWKV (Otter). Specifically, the Compound Segmentation Module~(CSM) is devised to segment and emphasize key patches in each frame, effectively highlighting subjects against background information. The Temporal Reconstruction Module (TRM) is incorporated into the temporal-enhanced prototype construction to enable bidirectional scanning, allowing better reconstruct temporal relation. Furthermore, a regular prototype is combined with the temporal-enhanced prototype to simultaneously enhance subject emphasis and temporal modeling, improving wide-angle FSAR performance. Extensive experiments on benchmarks such as SSv2, Kinetics, UCF101, and HMDB51 demonstrate that Otter achieves state-of-the-art performance. Extra evaluation on the VideoBadminton dataset further validates the superiority of Otter in wide-angle FSAR.
4DGS-Craft: Consistent and Interactive 4D Gaussian Splatting Editing
Oct 02, 2025
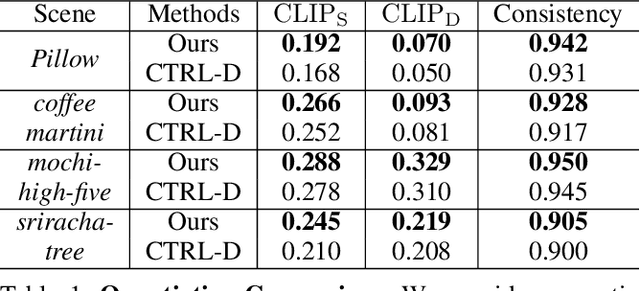

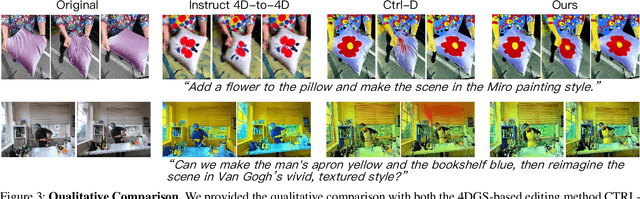
Recent advances in 4D Gaussian Splatting (4DGS) editing still face challenges with view, temporal, and non-editing region consistency, as well as with handling complex text instructions. To address these issues, we propose 4DGS-Craft, a consistent and interactive 4DGS editing framework. We first introduce a 4D-aware InstructPix2Pix model to ensure both view and temporal consistency. This model incorporates 4D VGGT geometry features extracted from the initial scene, enabling it to capture underlying 4D geometric structures during editing. We further enhance this model with a multi-view grid module that enforces consistency by iteratively refining multi-view input images while jointly optimizing the underlying 4D scene. Furthermore, we preserve the consistency of non-edited regions through a novel Gaussian selection mechanism, which identifies and optimizes only the Gaussians within the edited regions. Beyond consistency, facilitating user interaction is also crucial for effective 4DGS editing. Therefore, we design an LLM-based module for user intent understanding. This module employs a user instruction template to define atomic editing operations and leverages an LLM for reasoning. As a result, our framework can interpret user intent and decompose complex instructions into a logical sequence of atomic operations, enabling it to handle intricate user commands and further enhance editing performance. Compared to related works, our approach enables more consistent and controllable 4D scene editing. Our code will be made available upon acceptance.
On-Device Diffusion Transformer Policy for Efficient Robot Manipulation
Aug 01, 2025Diffusion Policies have significantly advanced robotic manipulation tasks via imitation learning, but their application on resource-constrained mobile platforms remains challenging due to computational inefficiency and extensive memory footprint. In this paper, we propose LightDP, a novel framework specifically designed to accelerate Diffusion Policies for real-time deployment on mobile devices. LightDP addresses the computational bottleneck through two core strategies: network compression of the denoising modules and reduction of the required sampling steps. We first conduct an extensive computational analysis on existing Diffusion Policy architectures, identifying the denoising network as the primary contributor to latency. To overcome performance degradation typically associated with conventional pruning methods, we introduce a unified pruning and retraining pipeline, optimizing the model's post-pruning recoverability explicitly. Furthermore, we combine pruning techniques with consistency distillation to effectively reduce sampling steps while maintaining action prediction accuracy. Experimental evaluations on the standard datasets, \ie, PushT, Robomimic, CALVIN, and LIBERO, demonstrate that LightDP achieves real-time action prediction on mobile devices with competitive performance, marking an important step toward practical deployment of diffusion-based policies in resource-limited environments. Extensive real-world experiments also show the proposed LightDP can achieve performance comparable to state-of-the-art Diffusion Policies.