 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
An Efficient Adaptive Compression Method for Human Perception and Machine Vision Tasks
Jan 08, 2025



While most existing neural image compression (NIC) and neural video compression (NVC) methodologies have achieved remarkable success, their optimization is primarily focused on human visual perception. However, with the rapid development of artificial intelligence, many images and videos will be used for various machine vision tasks. Consequently, such existing compression methodologies cannot achieve competitive performance in machine vision. In this work, we introduce an efficient adaptive compression (EAC) method tailored for both human perception and multiple machine vision tasks. Our method involves two key modules: 1), an adaptive compression mechanism, that adaptively selects several subsets from latent features to balance the optimizations for multiple machine vision tasks (e.g., segmentation, and detection) and human vision. 2), a task-specific adapter, that uses the parameter-efficient delta-tuning strategy to stimulate the comprehensive downstream analytical networks for specific machine vision tasks. By using the above two modules, we can optimize the bit-rate costs and improve machine vision performance. In general, our proposed EAC can seamlessly integrate with existing NIC (i.e., Ball\'e2018, and Cheng2020) and NVC (i.e., DVC, and FVC) methods. Extensive evaluation on various benchmark datasets (i.e., VOC2007, ILSVRC2012, VOC2012, COCO, UCF101, and DAVIS) shows that our method enhances performance for multiple machine vision tasks while maintaining the quality of human vision.
Towards Point Cloud Compression for Machine Perception: A Simple and Strong Baseline by Learning the Octree Depth Level Predictor
Jun 02, 2024



Point cloud compression has garnered significant interest in computer vision. However, existing algorithms primarily cater to human vision, while most point cloud data is utilized for machine vision tasks. To address this, we propose a point cloud compression framework that simultaneously handles both human and machine vision tasks. Our framework learns a scalable bit-stream, using only subsets for different machine vision tasks to save bit-rate, while employing the entire bit-stream for human vision tasks. Building on mainstream octree-based frameworks like VoxelContext-Net, OctAttention, and G-PCC, we introduce a new octree depth-level predictor. This predictor adaptively determines the optimal depth level for each octree constructed from a point cloud, controlling the bit-rate for machine vision tasks. For simpler tasks (\textit{e.g.}, classification) or objects/scenarios, we use fewer depth levels with fewer bits, saving bit-rate. Conversely, for more complex tasks (\textit{e.g}., segmentation) or objects/scenarios, we use deeper depth levels with more bits to enhance performance. Experimental results on various datasets (\textit{e.g}., ModelNet10, ModelNet40, ShapeNet, ScanNet, and KITTI) show that our point cloud compression approach improves performance for machine vision tasks without compromising human vision quality.
Group-aware Parameter-efficient Updating for Content-Adaptive Neural Video Compression
May 07, 2024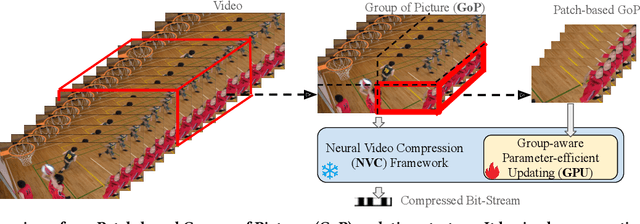

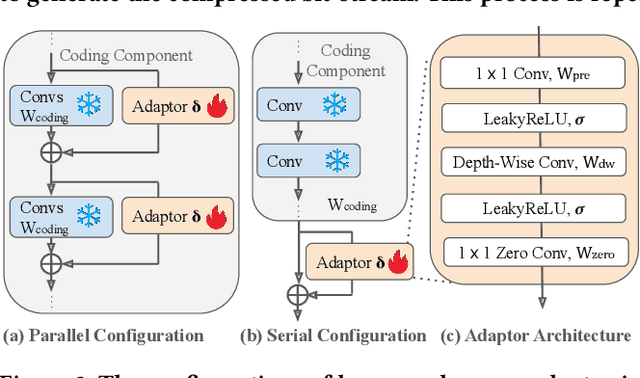
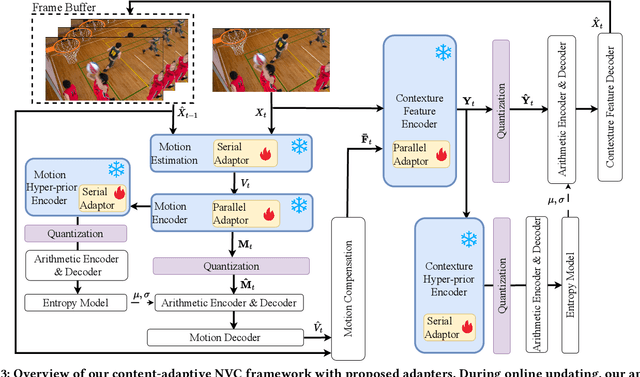
Content-adaptive compression is crucial for enhancing the adaptability of the pre-trained neural codec for various contents. Although these methods have been very practical in neural image compression (NIC), their application in neural video compression (NVC) is still limited due to two main aspects: 1), video compression relies heavily on temporal redundancy, therefore updating just one or a few frames can lead to significant errors accumulating over time; 2), NVC frameworks are generally more complex, with many large components that are not easy to update quickly during encoding. To address the previously mentioned challenges, we have developed a content-adaptive NVC technique called Group-aware Parameter-Efficient Updating (GPU). Initially, to minimize error accumulation, we adopt a group-aware approach for updating encoder parameters. This involves adopting a patch-based Group of Pictures (GoP) training strategy to segment a video into patch-based GoPs, which will be updated to facilitate a globally optimized domain-transferable solution. Subsequently, we introduce a parameter-efficient delta-tuning strategy, which is achieved by integrating several light-weight adapters into each coding component of the encoding process by both serial and parallel configuration. Such architecture-agnostic modules stimulate the components with large parameters, thereby reducing both the update cost and the encoding time. We incorporate our GPU into the latest NVC framework and conduct comprehensive experiments, whose results showcase outstanding video compression efficiency across four video benchmarks and adaptability of one medical image benchmark.
Boosting Fair Classifier Generalization through Adaptive Priority Reweighing
Sep 30, 2023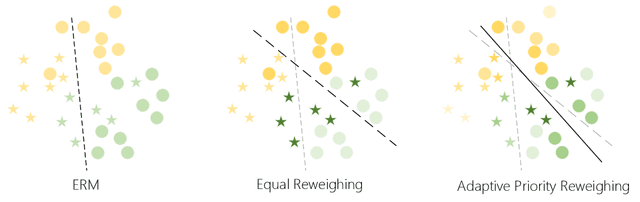
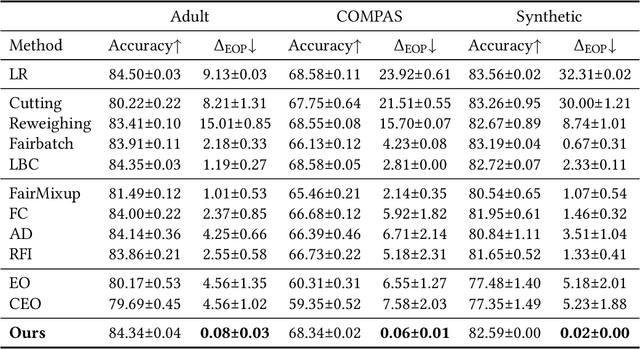
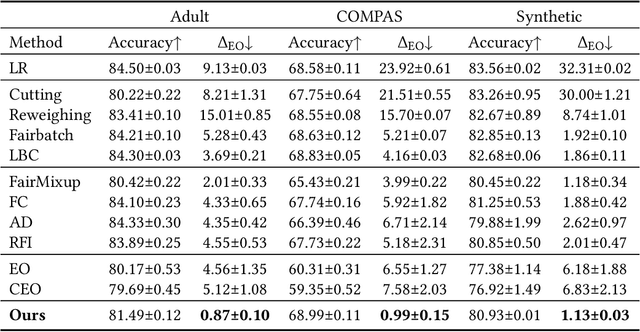
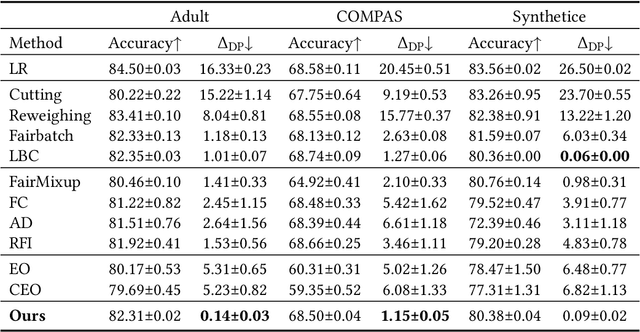
With the increasing penetration of machine learning applications in critical decision-making areas, calls for algorithmic fairness are more prominent. Although there have been various modalities to improve algorithmic fairness through learning with fairness constraints, their performance does not generalize well in the test set. A performance-promising fair algorithm with better generalizability is needed. This paper proposes a novel adaptive reweighing method to eliminate the impact of the distribution shifts between training and test data on model generalizability. Most previous reweighing methods propose to assign a unified weight for each (sub)group. Rather, our method granularly models the distance from the sample predictions to the decision boundary. Our adaptive reweighing method prioritizes samples closer to the decision boundary and assigns a higher weight to improve the generalizability of fair classifiers. Extensive experiments are performed to validate the generalizability of our adaptive priority reweighing method for accuracy and fairness measures (i.e., equal opportunity, equalized odds, and demographic parity) in tabular benchmarks. We also highlight the performance of our method in improving the fairness of language and vision models. The code is available at https://github.com/che2198/APW.
Inversion-by-Inversion: Exemplar-based Sketch-to-Photo Synthesis via Stochastic Differential Equations without Training
Aug 15, 2023



Exemplar-based sketch-to-photo synthesis allows users to generate photo-realistic images based on sketches. Recently, diffusion-based methods have achieved impressive performance on image generation tasks, enabling highly-flexible control through text-driven generation or energy functions. However, generating photo-realistic images with color and texture from sketch images remains challenging for diffusion models. Sketches typically consist of only a few strokes, with most regions left blank, making it difficult for diffusion-based methods to produce photo-realistic images. In this work, we propose a two-stage method named ``Inversion-by-Inversion" for exemplar-based sketch-to-photo synthesis. This approach includes shape-enhancing inversion and full-control inversion. During the shape-enhancing inversion process, an uncolored photo is generated with the guidance of a shape-energy function. This step is essential to ensure control over the shape of the generated photo. In the full-control inversion process, we propose an appearance-energy function to control the color and texture of the final generated photo.Importantly, our Inversion-by-Inversion pipeline is training-free and can accept different types of exemplars for color and texture control. We conducted extensive experiments to evaluate our proposed method, and the results demonstrate its effectiveness.
VideoControlNet: A Motion-Guided Video-to-Video Translation Framework by Using Diffusion Model with ControlNet
Aug 03, 2023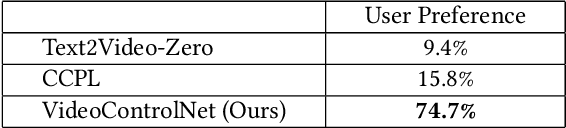
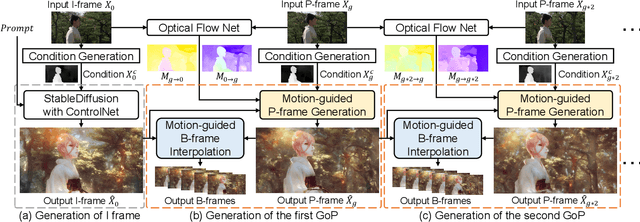


Recently, diffusion models like StableDiffusion have achieved impressive image generation results. However, the generation process of such diffusion models is uncontrollable, which makes it hard to generate videos with continuous and consistent content. In this work, by using the diffusion model with ControlNet, we proposed a new motion-guided video-to-video translation framework called VideoControlNet to generate various videos based on the given prompts and the condition from the input video. Inspired by the video codecs that use motion information for reducing temporal redundancy, our framework uses motion information to prevent the regeneration of the redundant areas for content consistency. Specifically, we generate the first frame (i.e., the I-frame) by using the diffusion model with ControlNet. Then we generate other key frames (i.e., the P-frame) based on the previous I/P-frame by using our newly proposed motion-guided P-frame generation (MgPG) method, in which the P-frames are generated based on the motion information and the occlusion areas are inpainted by using the diffusion model. Finally, the rest frames (i.e., the B-frame) are generated by using our motion-guided B-frame interpolation (MgBI) module. Our experiments demonstrate that our proposed VideoControlNet inherits the generation capability of the pre-trained large diffusion model and extends the image diffusion model to the video diffusion model by using motion information. More results are provided at our project page.
Content Adaptive Latents and Decoder for Neural Image Compression
Dec 21, 2022In recent years, neural image compression (NIC) algorithms have shown powerful coding performance. However, most of them are not adaptive to the image content. Although several content adaptive methods have been proposed by updating the encoder-side components, the adaptability of both latents and the decoder is not well exploited. In this work, we propose a new NIC framework that improves the content adaptability on both latents and the decoder. Specifically, to remove redundancy in the latents, our content adaptive channel dropping (CACD) method automatically selects the optimal quality levels for the latents spatially and drops the redundant channels. Additionally, we propose the content adaptive feature transformation (CAFT) method to improve decoder-side content adaptability by extracting the characteristic information of the image content, which is then used to transform the features in the decoder side. Experimental results demonstrate that our proposed methods with the encoder-side updating algorithm achieve the state-of-the-art performance.
Coarse-to-fine Deep Video Coding with Hyperprior-guided Mode Prediction
Jun 15, 2022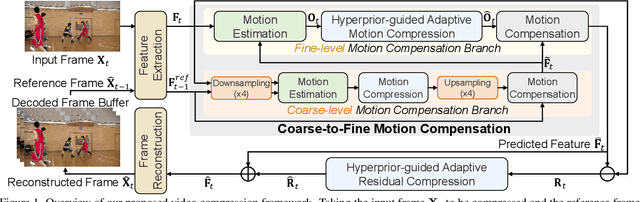
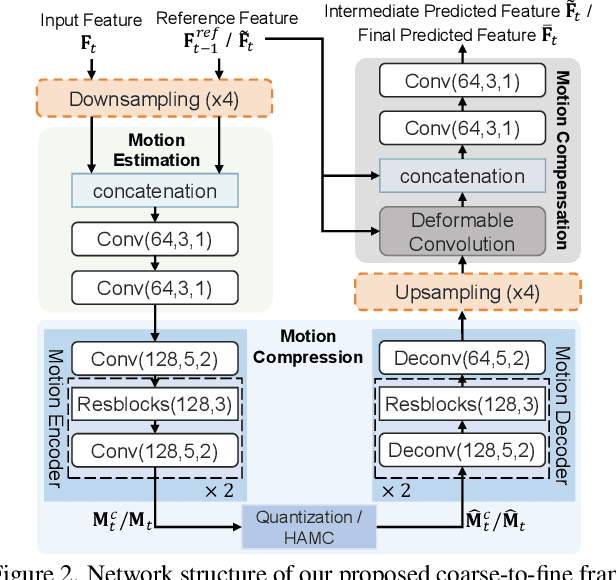
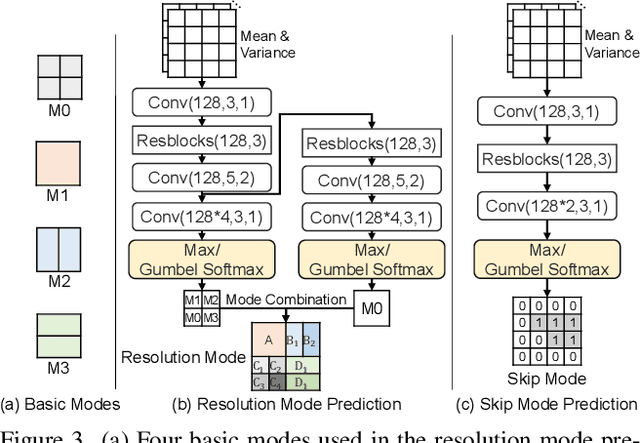
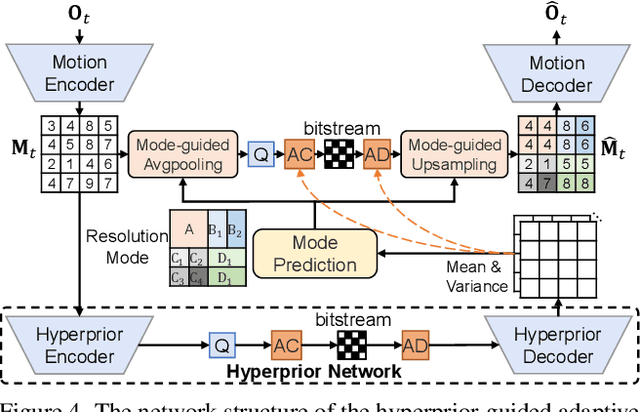
The previous deep video compression approaches only use the single scale motion compensation strategy and rarely adopt the mode prediction technique from the traditional standards like H.264/H.265 for both motion and residual compression. In this work, we first propose a coarse-to-fine (C2F) deep video compression framework for better motion compensation, in which we perform motion estimation, compression and compensation twice in a coarse to fine manner. Our C2F framework can achieve better motion compensation results without significantly increasing bit costs. Observing hyperprior information (i.e., the mean and variance values) from the hyperprior networks contains discriminant statistical information of different patches, we also propose two efficient hyperprior-guided mode prediction methods. Specifically, using hyperprior information as the input, we propose two mode prediction networks to respectively predict the optimal block resolutions for better motion coding and decide whether to skip residual information from each block for better residual coding without introducing additional bit cost while bringing negligible extra computation cost. Comprehensive experimental results demonstrate our proposed C2F video compression framework equipped with the new hyperprior-guided mode prediction methods achieves the state-of-the-art performance on HEVC, UVG and MCL-JCV datasets.
FVC: A New Framework towards Deep Video Compression in Feature Space
May 20, 2021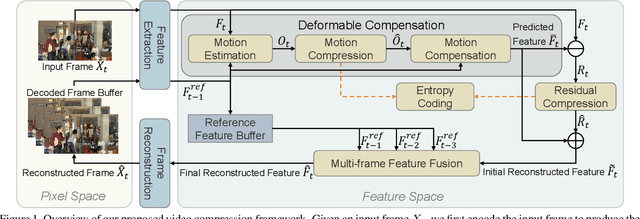
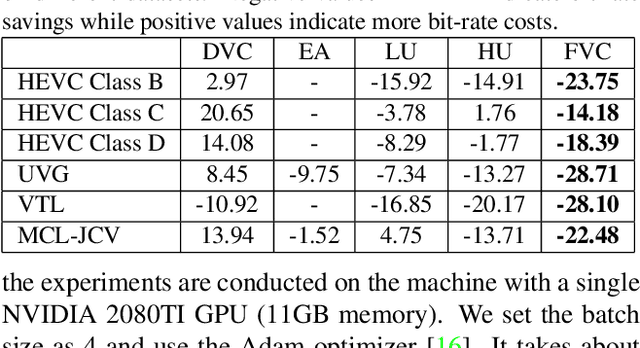
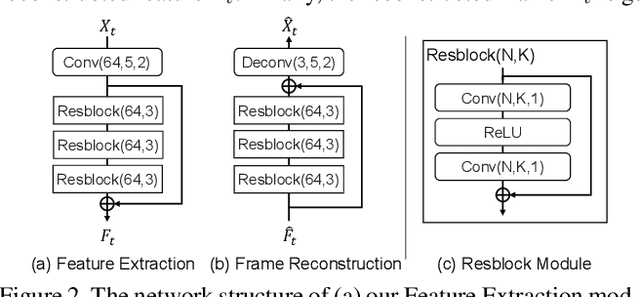
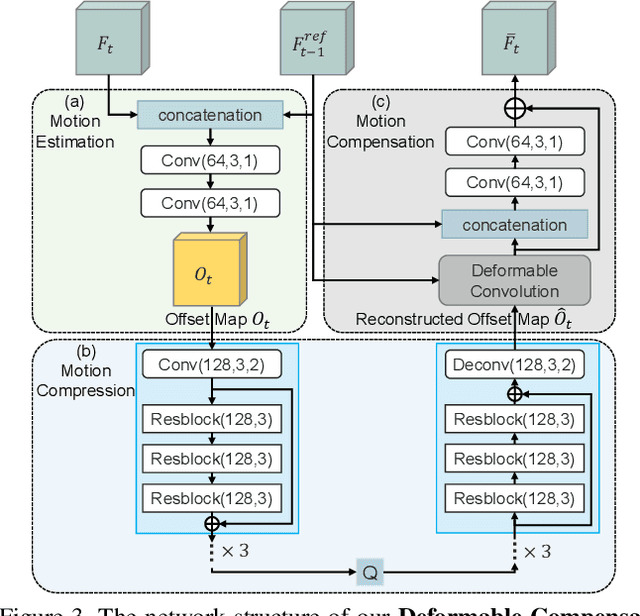
Learning based video compression attracts increasing attention in the past few years. The previous hybrid coding approaches rely on pixel space operations to reduce spatial and temporal redundancy, which may suffer from inaccurate motion estimation or less effective motion compensation. In this work, we propose a feature-space video coding network (FVC) by performing all major operations (i.e., motion estimation, motion compression, motion compensation and residual compression) in the feature space. Specifically, in the proposed deformable compensation module, we first apply motion estimation in the feature space to produce motion information (i.e., the offset maps), which will be compressed by using the auto-encoder style network. Then we perform motion compensation by using deformable convolution and generate the predicted feature. After that, we compress the residual feature between the feature from the current frame and the predicted feature from our deformable compensation module. For better frame reconstruction, the reference features from multiple previous reconstructed frames are also fused by using the non-local attention mechanism in the multi-frame feature fusion module. Comprehensive experimental results demonstrate that the proposed framework achieves the state-of-the-art performance on four benchmark datasets including HEVC, UVG, VTL and MCL-JCV.