 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Identifier Visual Prompt and Verifiable Reinforcement Learning for Chemical Reaction Diagram Parsing
Mar 17, 2026Reaction diagram parsing (RxnDP) is critical for extracting chemical synthesis information from literature. Although recent Vision-Language Models (VLMs) have emerged as a promising paradigm to automate this complex visual reasoning task, their application is fundamentally bottlenecked by the inability to align visual chemical entities with pre-trained knowledge, alongside the inherent discrepancy between token-level training and reaction-level evaluation. To address these dual challenges, this work enhances VLM-based RxnDP from two complementary perspectives: prompting representation and learning paradigms. First, we propose Identifier as Visual Prompting (IdtVP), which leverages naturally occurring molecule identifiers (e.g., bold numerals like 1a) to activate the chemical knowledge acquired during VLM pre-training. IdtVP enables powerful zero-shot and out-of-distribution capabilities, outperforming existing prompting strategies. Second, to further optimize performance within fine-tuning paradigms, we introduce Re3-DAPO, a reinforcement learning algorithm that leverages verifiable rewards to directly optimize reaction-level metrics, thereby achieving consistent gains over standard supervised fine-tuning. Additionally, we release the ScannedRxn benchmark, comprising scanned historical reaction diagrams with real-world artifacts, to rigorously assess model robustness and out-of-distribution ability. Our contributions advance the accuracy and generalization of VLM-based reaction diagram parsing. We will release data, models, and code on GitHub.
MANSION: Multi-floor lANguage-to-3D Scene generatIOn for loNg-horizon tasks
Mar 12, 2026Real-world robotic tasks are long-horizon and often span multiple floors, demanding rich spatial reasoning. However, existing embodied benchmarks are largely confined to single-floor in-house environments, failing to reflect the complexity of real-world tasks. We introduce MANSION, the first language-driven framework for generating building-scale, multi-floor 3D environments. Being aware of vertical structural constraints, MANSION generates realistic, navigable whole-building structures with diverse, human-friendly scenes, enabling the development and evaluation of cross-floor long-horizon tasks. Building on this framework, we release MansionWorld, a dataset of over 1,000 diverse buildings ranging from hospitals to offices, alongside a Task-Semantic Scene Editing Agent that customizes these environments using open-vocabulary commands to meet specific user needs. Benchmarking reveals that state-of-the-art agents degrade sharply in our settings, establishing MANSION as a critical testbed for the next generation of spatial reasoning and planning.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control
Dec 15, 2025Humanoid robots require precise locomotion and dexterous manipulation to perform challenging loco-manipulation tasks. Yet existing approaches, modular or end-to-end, are deficient in manipulation-aware locomotion. This confines the robot to a limited workspace, preventing it from performing large-space loco-manipulation. We attribute this to: (1) the challenge of acquiring loco-manipulation knowledge due to the scarcity of humanoid teleoperation data, and (2) the difficulty of faithfully and reliably executing locomotion commands, stemming from the limited precision and stability of existing RL controllers. To acquire richer loco-manipulation knowledge, we propose a unified latent learning framework that enables Vision-Language-Action (VLA) system to learn from low-cost action-free egocentric videos. Moreover, an efficient human data collection pipeline is devised to augment the dataset and scale the benefits. To execute the desired locomotion commands more precisely, we present a loco-manipulation-oriented (LMO) RL policy specifically tailored for accurate and stable core loco-manipulation movements, such as advancing, turning, and squatting. Building on these components, we introduce WholeBodyVLA, a unified framework for humanoid loco-manipulation. To the best of our knowledge, WholeBodyVLA is one of its kind enabling large-space humanoid loco-manipulation. It is verified via comprehensive experiments on the AgiBot X2 humanoid, outperforming prior baseline by 21.3%. It also demonstrates strong generalization and high extensibility across a broad range of tasks.
ViewCraft3D: High-Fidelity and View-Consistent 3D Vector Graphics Synthesis
May 26, 2025
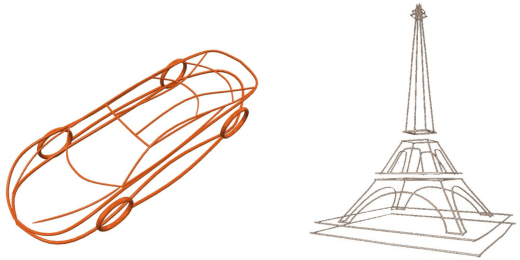
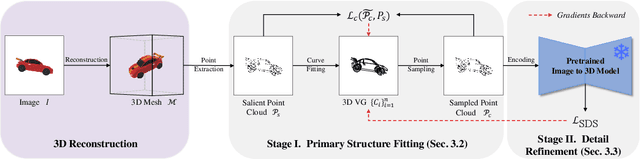
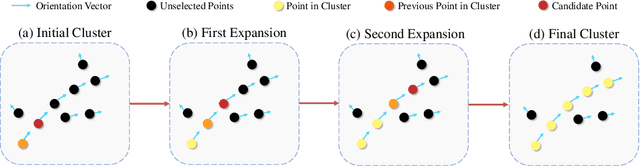
3D vector graphics play a crucial role in various applications including 3D shape retrieval, conceptual design, and virtual reality interactions due to their ability to capture essential structural information with minimal representation. While recent approaches have shown promise in generating 3D vector graphics, they often suffer from lengthy processing times and struggle to maintain view consistency. To address these limitations, we propose ViewCraft3D (VC3D), an efficient method that leverages 3D priors to generate 3D vector graphics. Specifically, our approach begins with 3D object analysis, employs a geometric extraction algorithm to fit 3D vector graphics to the underlying structure, and applies view-consistent refinement process to enhance visual quality. Our comprehensive experiments demonstrate that VC3D outperforms previous methods in both qualitative and quantitative evaluations, while significantly reducing computational overhead. The resulting 3D sketches maintain view consistency and effectively capture the essential characteristics of the original objects.
Achieving binary weight and activation for LLMs using Post-Training Quantization
Apr 07, 2025Quantizing large language models (LLMs) to 1-bit precision significantly reduces computational costs, but existing quantization techniques suffer from noticeable performance degradation when using weight and activation precisions below 4 bits (W4A4). In this paper, we propose a post-training quantization framework with W(1+1)A(1*4) configuration, where weights are quantized to 1 bit with an additional 1 bit for fine-grain grouping and activations are quantized to 1 bit with a 4-fold increase in the number of channels. For weight quantization, we propose utilizing Hessian-aware fine-grained grouping along with an EM-based quantization scheme. For activation quantization, we decompose INT4-quantized activations into a 4 * INT1 format equivalently and simultaneously smooth the scaling factors based on quantization errors, which further reduces the quantization errors in activations. Our method surpasses state-of-the-art (SOTA) LLM quantization baselines on W2A4 across multiple tasks, pushing the boundaries of existing LLM quantization methods toward fully binarized models.
SVGDreamer++: Advancing Editability and Diversity in Text-Guided SVG Generation
Nov 26, 2024



Recently, text-guided scalable vector graphics (SVG) synthesis has demonstrated significant potential in domains such as iconography and sketching. However, SVGs generated from existing Text-to-SVG methods often lack editability and exhibit deficiencies in visual quality and diversity. In this paper, we propose a novel text-guided vector graphics synthesis method to address these limitations. To improve the diversity of output SVGs, we present a Vectorized Particle-based Score Distillation (VPSD) approach. VPSD addresses over-saturation issues in existing methods and enhances sample diversity. A pre-trained reward model is incorporated to re-weight vector particles, improving aesthetic appeal and enabling faster convergence. Additionally, we design a novel adaptive vector primitives control strategy, which allows for the dynamic adjustment of the number of primitives, thereby enhancing the presentation of graphic details. Extensive experiments validate the effectiveness of the proposed method, demonstrating its superiority over baseline methods in terms of editability, visual quality, and diversity. We also show that our new method supports up to six distinct vector styles, capable of generating high-quality vector assets suitable for stylized vector design and poster design.
Latent Neural Operator Pretraining for Solving Time-Dependent PDEs
Oct 26, 2024



Pretraining methods gain increasing attraction recently for solving PDEs with neural operators. It alleviates the data scarcity problem encountered by neural operator learning when solving single PDE via training on large-scale datasets consisting of various PDEs and utilizing shared patterns among different PDEs to improve the solution precision. In this work, we propose the Latent Neural Operator Pretraining (LNOP) framework based on the Latent Neural Operator (LNO) backbone. We achieve universal transformation through pretraining on hybrid time-dependent PDE dataset to extract representations of different physical systems and solve various time-dependent PDEs in the latent space through finetuning on single PDE dataset. Our proposed LNOP framework reduces the solution error by 31.7% on four problems and can be further improved to 57.1% after finetuning. On out-of-distribution dataset, our LNOP model achieves roughly 50% lower error and 3$\times$ data efficiency on average across different dataset sizes. These results show that our method is more competitive in terms of solution precision, transfer capability and data efficiency compared to non-pretrained neural operators.
TrackGo: A Flexible and Efficient Method for Controllable Video Generation
Aug 21, 2024



Recent years have seen substantial progress in diffusion-based controllable video generation. However, achieving precise control in complex scenarios, including fine-grained object parts, sophisticated motion trajectories, and coherent background movement, remains a challenge. In this paper, we introduce TrackGo, a novel approach that leverages free-form masks and arrows for conditional video generation. This method offers users with a flexible and precise mechanism for manipulating video content. We also propose the TrackAdapter for control implementation, an efficient and lightweight adapter designed to be seamlessly integrated into the temporal self-attention layers of a pretrained video generation model. This design leverages our observation that the attention map of these layers can accurately activate regions corresponding to motion in videos. Our experimental results demonstrate that our new approach, enhanced by the TrackAdapter, achieves state-of-the-art performance on key metrics such as FVD, FID, and ObjMC scores. The project page of TrackGo can be found at: https://zhtjtcz.github.io/TrackGo-Page/
Training Dynamics of Nonlinear Contrastive Learning Model in the High Dimensional Limit
Jun 11, 2024



This letter presents a high-dimensional analysis of the training dynamics for a single-layer nonlinear contrastive learning model. The empirical distribution of the model weights converges to a deterministic measure governed by a McKean-Vlasov nonlinear partial differential equation (PDE). Under L2 regularization, this PDE reduces to a closed set of low-dimensional ordinary differential equations (ODEs), reflecting the evolution of the model performance during the training process. We analyze the fixed point locations and their stability of the ODEs unveiling several interesting findings. First, only the hidden variable's second moment affects feature learnability at the state with uninformative initialization. Second, higher moments influence the probability of feature selection by controlling the attraction region, rather than affecting local stability. Finally, independent noises added in the data argumentation degrade performance but negatively correlated noise can reduces the variance of gradient estimation yielding better performance. Despite of the simplicity of the analyzed model, it exhibits a rich phenomena of training dynamics, paving a way to understand more complex mechanism behind practical large models.