 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRexDrug: Reliable Multi-Drug Combination Extraction through Reasoning-Enhanced LLMs
Mar 09, 2026Automated Drug Combination Extraction (DCE) from large-scale biomedical literature is crucial for advancing precision medicine and pharmacological research. However, existing relation extraction methods primarily focus on binary interactions and struggle to model variable-length n-ary drug combinations, where complex compatibility logic and distributed evidence need to be considered. To address these limitations, we propose RexDrug, an end-to-end reasoning-enhanced relation extraction framework for n-ary drug combination extraction based on large language models. RexDrug adopts a two-stage training strategy. First, a multi-agent collaborative mechanism is utilized to automatically generate high-quality expert-like reasoning traces for supervised fine-tuning. Second, reinforcement learning with a multi-dimensional reward function specifically tailored for DCE is applied to further refine reasoning quality and extraction accuracy. Extensive experiments on the DrugComb dataset show that RexDrug consistently outperforms state-of-the-art baselines for n-ary extraction. Additional evaluation on the DDI13 corpus confirms its generalizability to binary drugdrug interaction tasks. Human expert assessment and automatic reasoning metrics further indicates that RexDrug produces coherent medical reasoning while accurately identifying complex therapeutic regimens. These results establish RexDrug as a scalable and reliable solution for complex biomedical relation extraction from unstructured text. The source code and data are available at https://github.com/DUTIR-BioNLP/RexDrug
RAGNav: A Retrieval-Augmented Topological Reasoning Framework for Multi-Goal Visual-Language Navigation
Mar 04, 2026Vision-Language Navigation (VLN) is evolving from single-point pathfinding toward the more challenging Multi-Goal VLN. This task requires agents to accurately identify multiple entities while collaboratively reasoning over their spatial-physical constraints and sequential execution order. However, generic Retrieval-Augmented Generation (RAG) paradigms often suffer from spatial hallucinations and planning drift when handling multi-object associations due to the lack of explicit spatial modeling.To address these challenges, we propose RAGNav, a framework that bridges the gap between semantic reasoning and physical structure. The core of RAGNav is a Dual-Basis Memory system, which integrates a low-level topological map for maintaining physical connectivity with a high-level semantic forest for hierarchical environment abstraction. Building on this representation, the framework introduces an anchor-guided conditional retrieval and a topological neighbor score propagation mechanism. This approach facilitates the rapid screening of candidate targets and the elimination of semantic noise, while performing semantic calibration by leveraging the physical associations inherent in the topological neighborhood.This mechanism significantly enhances the capability of inter-target reachability reasoning and the efficiency of sequential planning. Experimental results demonstrate that RAGNav achieves state-of-the-art (SOTA) performance in complex multi-goal navigation tasks.
MA-CoNav: A Master-Slave Multi-Agent Framework with Hierarchical Collaboration and Dual-Level Reflection for Long-Horizon Embodied VLN
Mar 03, 2026Vision-Language Navigation (VLN) aims to empower robots with the ability to perform long-horizon navigation in unfamiliar environments based on complex linguistic instructions. Its success critically hinges on establishing an efficient ``language-understanding -- visual-perception -- embodied-execution'' closed loop. Existing methods often suffer from perceptual distortion and decision drift in complex, long-distance tasks due to the cognitive overload of a single agent. Inspired by distributed cognition theory, this paper proposes MA-CoNav, a Multi-Agent Collaborative Navigation framework. This framework adopts a ``Master-Slave'' hierarchical agent collaboration architecture, decoupling and distributing the perception, planning, execution, and memory functions required for navigation tasks to specialized agents. Specifically, the Master Agent is responsible for global orchestration, while the Subordinate Agent group collaborates through a clear division of labor: an Observation Agent generates environment descriptions, a Planning Agent performs task decomposition and dynamic verification, an Execution Agent handles simultaneous mapping and action, and a Memory Agent manages structured experiences. Furthermore, the framework introduces a ``Local-Global'' dual-stage reflection mechanism to dynamically optimize the entire navigation pipeline. Empirical experiments were conducted using a real-world indoor dataset collected by a Limo Pro robot, with no scene-specific fine-tuning performed on the models throughout the process. The results demonstrate that MA-CoNav comprehensively outperforms existing mainstream VLN methods across multiple metrics.
AFD-INSTRUCTION: A Comprehensive Antibody Instruction Dataset with Functional Annotations for LLM-Based Understanding and Design
Feb 04, 2026Large language models (LLMs) have significantly advanced protein representation learning. However, their capacity to interpret and design antibodies through natural language remains limited. To address this challenge, we present AFD-Instruction, the first large-scale instruction dataset with functional annotations tailored to antibodies. This dataset encompasses two key components: antibody understanding, which infers functional attributes directly from sequences, and antibody design, which enables de novo sequence generation under functional constraints. These components provide explicit sequence-function alignment and support antibody design guided by natural language instructions. Extensive instruction-tuning experiments on general-purpose LLMs demonstrate that AFD-Instruction consistently improves performance across diverse antibody-related tasks. By linking antibody sequences with textual descriptions of function, AFD-Instruction establishes a new foundation for advancing antibody modeling and accelerating therapeutic discovery.
Stability as a Liability:Systematic Breakdown of Linguistic Structure in LLMs
Jan 26, 2026Training stability is typically regarded as a prerequisite for reliable optimization in large language models. In this work, we analyze how stabilizing training dynamics affects the induced generation distribution. We show that under standard maximum likelihood training, stable parameter trajectories lead stationary solutions to approximately minimize the forward KL divergence to the empirical distribution, while implicitly reducing generative entropy. As a consequence, the learned model can concentrate probability mass on a limited subset of empirical modes, exhibiting systematic degeneration despite smooth loss convergence. We empirically validate this effect using a controlled feedback-based training framework that stabilizes internal generation statistics, observing consistent low-entropy outputs and repetitive behavior across architectures and random seeds. It indicates that optimization stability and generative expressivity are not inherently aligned, and that stability alone is an insufficient indicator of generative quality.
Overview of CHIP 2025 Shared Task 2: Discharge Medication Recommendation for Metabolic Diseases Based on Chinese Electronic Health Records
Nov 09, 2025Discharge medication recommendation plays a critical role in ensuring treatment continuity, preventing readmission, and improving long-term management for patients with chronic metabolic diseases. This paper present an overview of the CHIP 2025 Shared Task 2 competition, which aimed to develop state-of-the-art approaches for automatically recommending appro-priate discharge medications using real-world Chinese EHR data. For this task, we constructed CDrugRed, a high-quality dataset consisting of 5,894 de-identified hospitalization records from 3,190 patients in China. This task is challenging due to multi-label nature of medication recommendation, het-erogeneous clinical text, and patient-specific variability in treatment plans. A total of 526 teams registered, with 167 and 95 teams submitting valid results to the Phase A and Phase B leaderboards, respectively. The top-performing team achieved the highest overall performance on the final test set, with a Jaccard score of 0.5102, F1 score of 0.6267, demonstrating the potential of advanced large language model (LLM)-based ensemble systems. These re-sults highlight both the promise and remaining challenges of applying LLMs to medication recommendation in Chinese EHRs. The post-evaluation phase remains open at https://tianchi.aliyun.com/competition/entrance/532411/.
MedTrust-RAG: Evidence Verification and Trust Alignment for Biomedical Question Answering
Oct 16, 2025Biomedical question answering (QA) requires accurate interpretation of complex medical knowledge. Large language models (LLMs) have shown promising capabilities in this domain, with retrieval-augmented generation (RAG) systems enhancing performance by incorporating external medical literature. However, RAG-based approaches in biomedical QA suffer from hallucinations due to post-retrieval noise and insufficient verification of retrieved evidence, undermining response reliability. We propose MedTrust-Guided Iterative RAG, a framework designed to enhance factual consistency and mitigate hallucinations in medical QA. Our method introduces three key innovations. First, it enforces citation-aware reasoning by requiring all generated content to be explicitly grounded in retrieved medical documents, with structured Negative Knowledge Assertions used when evidence is insufficient. Second, it employs an iterative retrieval-verification process, where a verification agent assesses evidence adequacy and refines queries through Medical Gap Analysis until reliable information is obtained. Third, it integrates the MedTrust-Align Module (MTAM) that combines verified positive examples with hallucination-aware negative samples, leveraging Direct Preference Optimization to reinforce citation-grounded reasoning while penalizing hallucination-prone response patterns. Experiments on MedMCQA, MedQA, and MMLU-Med demonstrate that our approach consistently outperforms competitive baselines across multiple model architectures, achieving the best average accuracy with gains of 2.7% for LLaMA3.1-8B-Instruct and 2.4% for Qwen3-8B.
FocusMed: A Large Language Model-based Framework for Enhancing Medical Question Summarization with Focus Identification
Oct 06, 2025
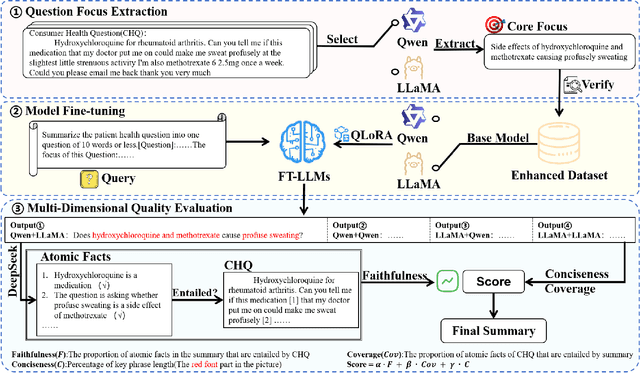

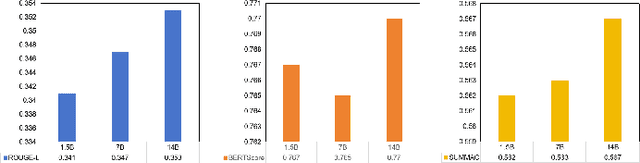
With the rapid development of online medical platforms, consumer health questions (CHQs) are inefficient in diagnosis due to redundant information and frequent non-professional terms. The medical question summary (MQS) task aims to transform CHQs into streamlined doctors' frequently asked questions (FAQs), but existing methods still face challenges such as poor identification of question focus and model hallucination. This paper explores the potential of large language models (LLMs) in the MQS task and finds that direct fine-tuning is prone to focus identification bias and generates unfaithful content. To this end, we propose an optimization framework based on core focus guidance. First, a prompt template is designed to drive the LLMs to extract the core focus from the CHQs that is faithful to the original text. Then, a fine-tuning dataset is constructed in combination with the original CHQ-FAQ pairs to improve the ability to identify the focus of the question. Finally, a multi-dimensional quality evaluation and selection mechanism is proposed to comprehensively improve the quality of the summary from multiple dimensions. We conduct comprehensive experiments on two widely-adopted MQS datasets using three established evaluation metrics. The proposed framework achieves state-of-the-art performance across all measures, demonstrating a significant boost in the model's ability to identify critical focus of questions and a notable mitigation of hallucinations. The source codes are freely available at https://github.com/DUT-LiuChao/FocusMed.
ViewCraft3D: High-Fidelity and View-Consistent 3D Vector Graphics Synthesis
May 26, 2025
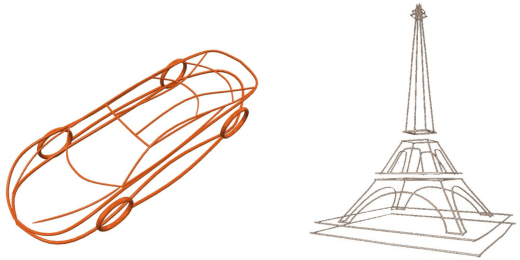
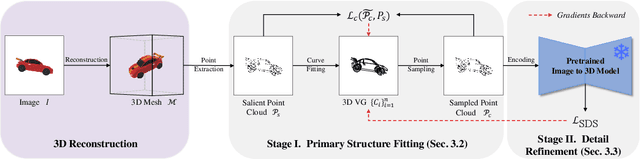
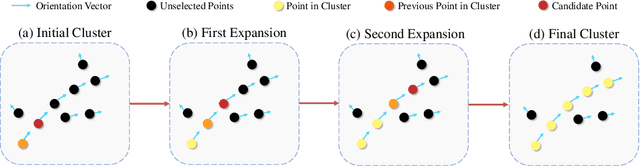
3D vector graphics play a crucial role in various applications including 3D shape retrieval, conceptual design, and virtual reality interactions due to their ability to capture essential structural information with minimal representation. While recent approaches have shown promise in generating 3D vector graphics, they often suffer from lengthy processing times and struggle to maintain view consistency. To address these limitations, we propose ViewCraft3D (VC3D), an efficient method that leverages 3D priors to generate 3D vector graphics. Specifically, our approach begins with 3D object analysis, employs a geometric extraction algorithm to fit 3D vector graphics to the underlying structure, and applies view-consistent refinement process to enhance visual quality. Our comprehensive experiments demonstrate that VC3D outperforms previous methods in both qualitative and quantitative evaluations, while significantly reducing computational overhead. The resulting 3D sketches maintain view consistency and effectively capture the essential characteristics of the original objects.
Dynamical Label Augmentation and Calibration for Noisy Electronic Health Records
May 12, 2025Medical research, particularly in predicting patient outcomes, heavily relies on medical time series data extracted from Electronic Health Records (EHR), which provide extensive information on patient histories. Despite rigorous examination, labeling errors are inevitable and can significantly impede accurate predictions of patient outcome. To address this challenge, we propose an \textbf{A}ttention-based Learning Framework with Dynamic \textbf{C}alibration and Augmentation for \textbf{T}ime series Noisy \textbf{L}abel \textbf{L}earning (ACTLL). This framework leverages a two-component Beta mixture model to identify the certain and uncertain sets of instances based on the fitness distribution of each class, and it captures global temporal dynamics while dynamically calibrating labels from the uncertain set or augmenting confident instances from the certain set. Experimental results on large-scale EHR datasets eICU and MIMIC-IV-ED, and several benchmark datasets from the UCR and UEA repositories, demonstrate that our model ACTLL has achieved state-of-the-art performance, especially under high noise levels.