 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Abstract Sim2Real through Approximate Information States
Apr 16, 2026In recent years, reinforcement learning (RL) has shown remarkable success in robotics when a fast and accurate simulator is available for a given task. When using RL and simulation, more simulator realism is generally beneficial but becomes harder to obtain as robots are deployed in increasingly complex and widescale domains. In such settings, simulators will likely fail to model all relevant details of a given target task and this observation motivates the study of sim2real with simulators that leave out key task details. In this paper, we formalize and study the abstract sim2real problem: given an abstract simulator that models a target task at a coarse level of abstraction, how can we train a policy with RL in the abstract simulator and successfully transfer it to the real-world? Our first contribution is to formalize this problem using the language of state abstraction from the RL literature. This framing shows that an abstract simulator can be grounded to match the target task if the grounded abstract dynamics take the history of states into account. Based on the formalism, we then introduce a method that uses real-world task data to correct the dynamics of the abstract simulator. We then show that this method enables successful policy transfer both in sim2sim and sim2real evaluation.
A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics
Apr 11, 2026Self-supervised representation learning is central to modern machine learning because it extracts structured latent features from unlabeled data and enables robust transfer across tasks and domains. However, it can suffer from representation collapse, a widely observed failure mode in which embeddings lose discriminative structure and distinct inputs become indistinguishable. To understand the mechanisms that drive collapse and the ingredients that prevent it, we introduce a minimal embedding-only model whose gradient-flow dynamics and fixed points can be analyzed in closed form, using a classification-representation setting as a concrete playground where collapse is directly quantified through the contraction of label-embedding geometry. We illustrate that the model does not collapse when the data are perfectly classifiable, while a small fraction of frustrated samples that cannot be classified consistently induces collapse through an additional slow time scale that follows the early performance gain. Within the same framework, we examine collapse prevention by adding a shared projection head and applying stop-gradient at the level of the training dynamics. We analyze the resulting fixed points and develop a dynamical mean-field style self-consistency description, showing that stop-gradient enables non-collapsed solutions and stabilizes finite class separation under frustration. We further verify empirically that the same qualitative dynamics and collapse-prevention effects appear in a linear teacher-student model, indicating that the minimal theory captures features that persist beyond the pure embedding setting.
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
Emergent Specialization in Learner Populations: Competition as the Source of Diversity
Jan 16, 2026How can populations of learners develop coordinated, diverse behaviors without explicit communication or diversity incentives? We demonstrate that competition alone is sufficient to induce emergent specialization -- learners spontaneously partition into specialists for different environmental regimes through competitive dynamics, consistent with ecological niche theory. We introduce the NichePopulation algorithm, a simple mechanism combining competitive exclusion with niche affinity tracking. Validated across six real-world domains (cryptocurrency trading, commodity prices, weather forecasting, solar irradiance, urban traffic, and air quality), our approach achieves a mean Specialization Index of 0.75 with effect sizes of Cohen's d > 20. Key findings: (1) At lambda=0 (no niche bonus), learners still achieve SI > 0.30, proving specialization is genuinely emergent; (2) Diverse populations outperform homogeneous baselines by +26.5% through method-level division of labor; (3) Our approach outperforms MARL baselines (QMIX, MAPPO, IQL) by 4.3x while being 4x faster.
Aerial-ground Cross-modal Localization: Dataset, Ground-truth, and Benchmark
Sep 09, 2025Accurate visual localization in dense urban environments poses a fundamental task in photogrammetry, geospatial information science, and robotics. While imagery is a low-cost and widely accessible sensing modality, its effectiveness on visual odometry is often limited by textureless surfaces, severe viewpoint changes, and long-term drift. The growing public availability of airborne laser scanning (ALS) data opens new avenues for scalable and precise visual localization by leveraging ALS as a prior map. However, the potential of ALS-based localization remains underexplored due to three key limitations: (1) the lack of platform-diverse datasets, (2) the absence of reliable ground-truth generation methods applicable to large-scale urban environments, and (3) limited validation of existing Image-to-Point Cloud (I2P) algorithms under aerial-ground cross-platform settings. To overcome these challenges, we introduce a new large-scale dataset that integrates ground-level imagery from mobile mapping systems with ALS point clouds collected in Wuhan, Hong Kong, and San Francisco.
Kernel Two-Sample Testing via Directional Components Analysis
Aug 12, 2025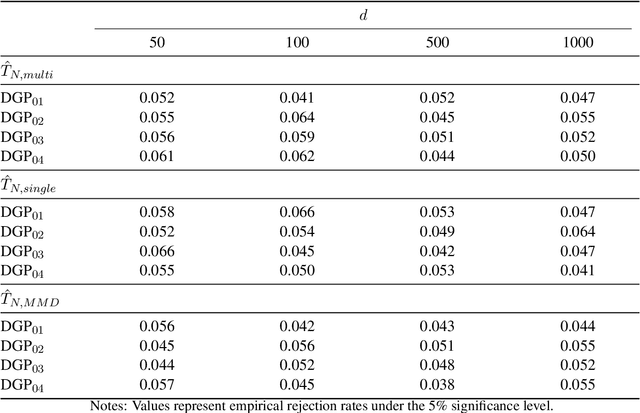
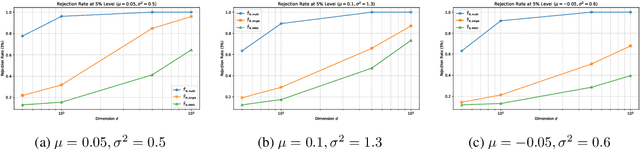
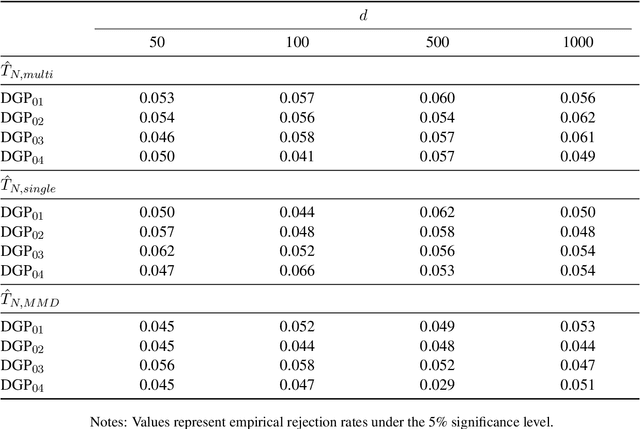
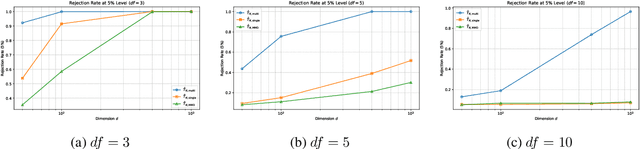
We propose a novel kernel-based two-sample test that leverages the spectral decomposition of the maximum mean discrepancy (MMD) statistic to identify and utilize well-estimated directional components in reproducing kernel Hilbert space (RKHS). Our approach is motivated by the observation that the estimation quality of these components varies significantly, with leading eigen-directions being more reliably estimated in finite samples. By focusing on these directions and aggregating information across multiple kernels, the proposed test achieves higher power and improved robustness, especially in high-dimensional and unbalanced sample settings. We further develop a computationally efficient multiplier bootstrap procedure for approximating critical values, which is theoretically justified and significantly faster than permutation-based alternatives. Extensive simulations and empirical studies on microarray datasets demonstrate that our method maintains the nominal Type I error rate and delivers superior power compared to other existing MMD-based tests.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
May 30, 2025Deep reasoning is fundamental for solving complex tasks, especially in vision-centric scenarios that demand sequential, multimodal understanding. However, existing benchmarks typically evaluate agents with fully synthetic, single-turn queries, limited visual modalities, and lack a framework to assess reasoning quality over multiple steps as required in real-world settings. To address this, we introduce Agent-X, a large-scale benchmark for evaluating vision-centric agents multi-step and deep reasoning capabilities in real-world, multimodal settings. Agent- X features 828 agentic tasks with authentic visual contexts, including images, multi-image comparisons, videos, and instructional text. These tasks span six major agentic environments: general visual reasoning, web browsing, security and surveillance, autonomous driving, sports, and math reasoning. Our benchmark requires agents to integrate tool use with explicit, stepwise decision-making in these diverse settings. In addition, we propose a fine-grained, step-level evaluation framework that assesses the correctness and logical coherence of each reasoning step and the effectiveness of tool usage throughout the task. Our results reveal that even the best-performing models, including GPT, Gemini, and Qwen families, struggle to solve multi-step vision tasks, achieving less than 50% full-chain success. These findings highlight key bottlenecks in current LMM reasoning and tool-use capabilities and identify future research directions in vision-centric agentic reasoning models. Our data and code are publicly available at https://github.com/mbzuai-oryx/Agent-X