 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Meets Large Multimodal Models for Driving Scenario Understanding
Mar 18, 2025Large Multimodal Models (LMMs) have recently gained prominence in autonomous driving research, showcasing promising capabilities across various emerging benchmarks. LMMs specifically designed for this domain have demonstrated effective perception, planning, and prediction skills. However, many of these methods underutilize 3D spatial and temporal elements, relying mainly on image data. As a result, their effectiveness in dynamic driving environments is limited. We propose to integrate tracking information as an additional input to recover 3D spatial and temporal details that are not effectively captured in the images. We introduce a novel approach for embedding this tracking information into LMMs to enhance their spatiotemporal understanding of driving scenarios. By incorporating 3D tracking data through a track encoder, we enrich visual queries with crucial spatial and temporal cues while avoiding the computational overhead associated with processing lengthy video sequences or extensive 3D inputs. Moreover, we employ a self-supervised approach to pretrain the tracking encoder to provide LMMs with additional contextual information, significantly improving their performance in perception, planning, and prediction tasks for autonomous driving. Experimental results demonstrate the effectiveness of our approach, with a gain of 9.5% in accuracy, an increase of 7.04 points in the ChatGPT score, and 9.4% increase in the overall score over baseline models on DriveLM-nuScenes benchmark, along with a 3.7% final score improvement on DriveLM-CARLA. Our code is available at https://github.com/mbzuai-oryx/TrackingMeetsLMM
DriveLMM-o1: A Step-by-Step Reasoning Dataset and Large Multimodal Model for Driving Scenario Understanding
Mar 13, 2025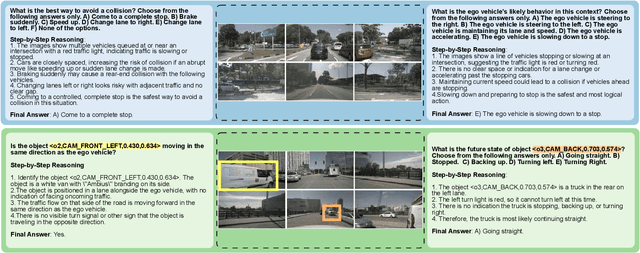
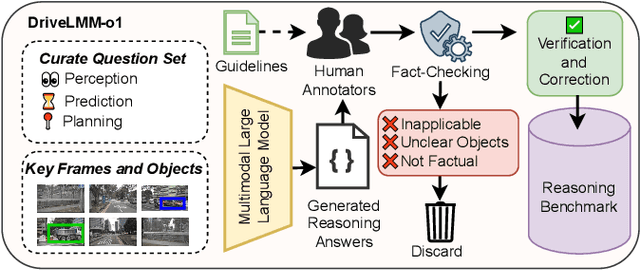
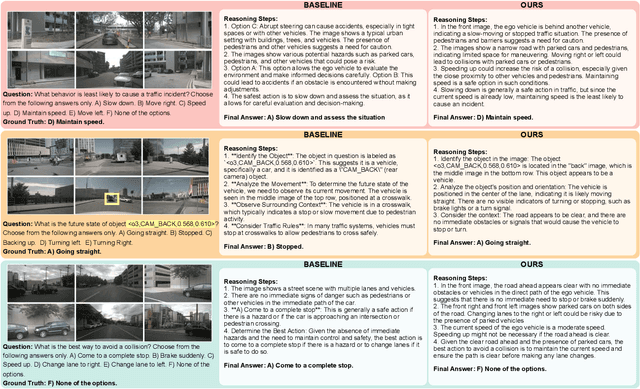
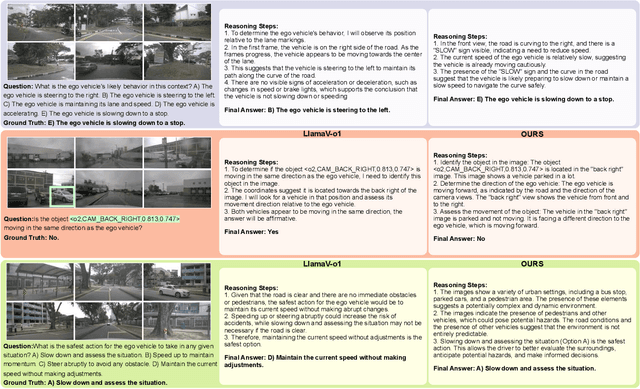
While large multimodal models (LMMs) have demonstrated strong performance across various Visual Question Answering (VQA) tasks, certain challenges require complex multi-step reasoning to reach accurate answers. One particularly challenging task is autonomous driving, which demands thorough cognitive processing before decisions can be made. In this domain, a sequential and interpretive understanding of visual cues is essential for effective perception, prediction, and planning. Nevertheless, common VQA benchmarks often focus on the accuracy of the final answer while overlooking the reasoning process that enables the generation of accurate responses. Moreover, existing methods lack a comprehensive framework for evaluating step-by-step reasoning in realistic driving scenarios. To address this gap, we propose DriveLMM-o1, a new dataset and benchmark specifically designed to advance step-wise visual reasoning for autonomous driving. Our benchmark features over 18k VQA examples in the training set and more than 4k in the test set, covering diverse questions on perception, prediction, and planning, each enriched with step-by-step reasoning to ensure logical inference in autonomous driving scenarios. We further introduce a large multimodal model that is fine-tuned on our reasoning dataset, demonstrating robust performance in complex driving scenarios. In addition, we benchmark various open-source and closed-source methods on our proposed dataset, systematically comparing their reasoning capabilities for autonomous driving tasks. Our model achieves a +7.49% gain in final answer accuracy, along with a 3.62% improvement in reasoning score over the previous best open-source model. Our framework, dataset, and model are available at https://github.com/ayesha-ishaq/DriveLMM-o1.
Open3DTrack: Towards Open-Vocabulary 3D Multi-Object Tracking
Oct 02, 20243D multi-object tracking plays a critical role in autonomous driving by enabling the real-time monitoring and prediction of multiple objects' movements. Traditional 3D tracking systems are typically constrained by predefined object categories, limiting their adaptability to novel, unseen objects in dynamic environments. To address this limitation, we introduce open-vocabulary 3D tracking, which extends the scope of 3D tracking to include objects beyond predefined categories. We formulate the problem of open-vocabulary 3D tracking and introduce dataset splits designed to represent various open-vocabulary scenarios. We propose a novel approach that integrates open-vocabulary capabilities into a 3D tracking framework, allowing for generalization to unseen object classes. Our method effectively reduces the performance gap between tracking known and novel objects through strategic adaptation. Experimental results demonstrate the robustness and adaptability of our method in diverse outdoor driving scenarios. To the best of our knowledge, this work is the first to address open-vocabulary 3D tracking, presenting a significant advancement for autonomous systems in real-world settings. Code, trained models, and dataset splits are available publicly.