 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaying More Attention to Visual Tokens in Self-Evolving Large Multimodal Models
Jun 25, 2026Recently, self-evolving large multimodal models (LMMs) have received attention for improving visual reasoning in a purely unsupervised setting. However, multi-role self-play and self-consistency reward schemes in existing self-evolving LMMs optimize answer agreement without ensuring the decoder attends to visual content, relying instead on statistical language priors to produce self consistent outputs. This leads to a persistent failure mode we term visual under-conditioning, where the decoder relies on language priors rather than the image during generation, manifesting as insufficient attention to visual tokens. As a result, current self-evolving LMMs struggle on vision--language understanding tasks such as image captioning and visual question answering. To address this, we propose VISE (Visual Invariance Self-Evolution), a purely unsupervised self-evolving framework that directly regularizes the model's visual conditioning policy through two complementary invariance-based rewards: a geometric invariance reward that enforces spatial consistency under known transformations, and a semantic invariance reward that penalizes evidence-agnostic generation by requiring the model to recognize the absence of evidence when predicted regions are perturbed. VISE operates within a single model without specialist roles, external reward models, or annotations, and is trained on raw unlabeled images. Experiments on 18 benchmarks demonstrate the efficacy of our approach. Using Qwen3-VL-2B as the base model, VISE achieves gains of $+16.85$ CIDEr on COCO and $+19.66$ CIDEr on TextCaps, reduces object hallucination by $5.0$ Chair-I points, and generalizes across four model families and scales. Our code and models are available at https://mbzuai-oryx.github.io/VISE
Ask, Solve, Generate: Self-Evolving Unified Multimodal Understanding and Generation via Self-Consistency Rewards
Jun 25, 2026Most unified large multimodal models (LMMs) that support both visual understanding and image generation still rely on curated post-training supervision, such as human annotations, preference labels, or external reward models. We ask whether a unified LMM can improve both abilities autonomously using only unlabeled images. We propose a self-evolving training framework with three internal roles: a Proposer that generates visual questions, a Solver that answers and evaluates them, and a Generator that synthesizes images. Training uses only self-derived consistency signals, without human annotations, preference labels, or task-trained external reward/judge models. To stabilize learning, we introduce Solver Token Entropy (STE), a continuous difficulty signal based on token-level prediction uncertainty that remains useful even when sample-level consistency becomes unreliable. For image generation, we design a multi-scale internal evaluation scheme that combines question-answer fidelity scoring with cycle-consistent captioning. This creates a solver-mediated coupling, where better visual understanding enables more reliable generation assessment and stronger internal training signals. The framework preserves the same role decomposition, reward logic, and training schedule across diffusion-based BLIP3o, rectified-flow BAGEL, and autoregressive VARGPT-v1.1 architectures, requiring only each backbone's native prompting and generation interface. Across eight understanding metrics, our method consistently improves over the corresponding base models. On BAGEL, it achieves a $+3.5\%$ absolute gain on MMMU and improves GenEval image generation performance from $82\%$ to $85\%$. Code and models are publicly released.
SafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
May 18, 2026Diffusion models have been widely studied for removing unsafe content learned during pre-training. Existing methods require expensive supervised data, either unsafe-text paired with safe-image groundtruth or negative/positive image pairs, making them impractical to scale. Furthermore, offline reinforcement learning and supervised fine-tuning approaches that generate synthetic data offline suffer from catastrophic forgetting, degrading generation quality. We propose a novel online reinforcement learning framework that addresses both data scarcity and model degradation through post-training with Group Relative Policy Optimization (GRPO) on both negative and positive text prompts. To eliminate the need for fine-tuning specialized safe/unsafe reward models, we introduce a \textit{steering reward mechanism} that exploits an inherent property of CLIP embeddings: steering text representations toward positive safety directions and away from negative ones in the embedding space. Our online-policy approach enables the model to learn from diverse prompts, including explicit unsafe content, without catastrophic forgetting. Extensive experiments demonstrate that our method reduces inappropriate content to 18.07\% (vs. 48.9\% for SD v1.4) and nudity detections to 15 (vs. 646 baseline) while improving compositional generation quality from 42.08\% to 47.83\% on GenEval. Remarkably, these safety gains generalize to out-of-domain unsafe prompts across seven harm categories, achieving state-of-the-art performance without supervised paired data or reward tuning. Github: https://github.com/MAXNORM8650/SafeDiffusion-R1.
Paper Circle: An Open-source Multi-agent Research Discovery and Analysis Framework
Apr 07, 2026The rapid growth of scientific literature has made it increasingly difficult for researchers to efficiently discover, evaluate, and synthesize relevant work. Recent advances in multi-agent large language models (LLMs) have demonstrated strong potential for understanding user intent and are being trained to utilize various tools. In this paper, we introduce Paper Circle, a multi-agent research discovery and analysis system designed to reduce the effort required to find, assess, organize, and understand academic literature. The system comprises two complementary pipelines: (1) a Discovery Pipeline that integrates offline and online retrieval from multiple sources, multi-criteria scoring, diversity-aware ranking, and structured outputs; and (2) an Analysis Pipeline that transforms individual papers into structured knowledge graphs with typed nodes such as concepts, methods, experiments, and figures, enabling graph-aware question answering and coverage verification. Both pipelines are implemented within a coder LLM-based multi-agent orchestration framework and produce fully reproducible, synchronized outputs including JSON, CSV, BibTeX, Markdown, and HTML at each agent step. This paper describes the system architecture, agent roles, retrieval and scoring methods, knowledge graph schema, and evaluation interfaces that together form the Paper Circle research workflow. We benchmark Paper Circle on both paper retrieval and paper review generation, reporting hit rate, MRR, and Recall at K. Results show consistent improvements with stronger agent models. We have publicly released the website at https://papercircle.vercel.app/ and the code at https://github.com/MAXNORM8650/papercircle.
CoME-VL: Scaling Complementary Multi-Encoder Vision-Language Learning
Apr 03, 2026Recent vision-language models (VLMs) typically rely on a single vision encoder trained with contrastive image-text objectives, such as CLIP-style pretraining. While contrastive encoders are effective for cross-modal alignment and retrieval, self-supervised visual encoders often capture richer dense semantics and exhibit stronger robustness on recognition and understanding tasks. In this work, we investigate how to scale the fusion of these complementary visual representations for vision-language modeling. We propose CoME-VL: Complementary Multi-Encoder Vision-Language, a modular fusion framework that integrates a contrastively trained vision encoder with a self-supervised DINO encoder. Our approach performs representation-level fusion by (i) entropy-guided multi-layer aggregation with orthogonality-constrained projections to reduce redundancy, and (ii) RoPE-enhanced cross-attention to align heterogeneous token grids and produce compact fused visual tokens. The fused tokens can be injected into a decoder-only LLM with minimal changes to standard VLM pipelines. Extensive experiments across diverse vision-language benchmarks demonstrate that CoME-VL consistently outperforms single-encoder baselines. In particular, we observe an average improvement of 4.9% on visual understanding tasks and 5.4% on grounding tasks. Our method achieves state-of-the-art performance on RefCOCO for detection while improving over the baseline by a large margin. Finally, we conduct ablation studies on layer merging, non-redundant feature mixing, and fusion capacity to evaluate how complementary contrastive and self-supervised signals affect VLM performance.
MediX-R1: Open Ended Medical Reinforcement Learning
Feb 26, 2026We introduce MediX-R1, an open-ended Reinforcement Learning (RL) framework for medical multimodal large language models (MLLMs) that enables clinically grounded, free-form answers beyond multiple-choice formats. MediX-R1 fine-tunes a baseline vision-language backbone with Group Based RL and a composite reward tailored for medical reasoning: an LLM-based accuracy reward that judges semantic correctness with a strict YES/NO decision, a medical embedding-based semantic reward to capture paraphrases and terminology variants, and lightweight format and modality rewards that enforce interpretable reasoning and modality recognition. This multi-signal design provides stable, informative feedback for open-ended outputs where traditional verifiable or MCQ-only rewards fall short. To measure progress, we propose a unified evaluation framework for both text-only and image+text tasks that uses a Reference-based LLM-as-judge in place of brittle string-overlap metrics, capturing semantic correctness, reasoning, and contextual alignment. Despite using only $\sim51$K instruction examples, MediX-R1 achieves excellent results across standard medical LLM (text-only) and VLM (image + text) benchmarks, outperforming strong open-source baselines and delivering particularly large gains on open-ended clinical tasks. Our results demonstrate that open-ended RL with comprehensive reward signals and LLM-based evaluation is a practical path toward reliable medical reasoning in multimodal models. Our trained models, curated datasets and source code are available at https://medix.cvmbzuai.com
Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
Feb 24, 2026Unified multimodal models can both understand and generate visual content within a single architecture. Existing models, however, remain data-hungry and too heavy for deployment on edge devices. We present Mobile-O, a compact vision-language-diffusion model that brings unified multimodal intelligence to a mobile device. Its core module, the Mobile Conditioning Projector (MCP), fuses vision-language features with a diffusion generator using depthwise-separable convolutions and layerwise alignment. This design enables efficient cross-modal conditioning with minimal computational cost. Trained on only a few million samples and post-trained in a novel quadruplet format (generation prompt, image, question, answer), Mobile-O jointly enhances both visual understanding and generation capabilities. Despite its efficiency, Mobile-O attains competitive or superior performance compared to other unified models, achieving 74% on GenEval and outperforming Show-O and JanusFlow by 5% and 11%, while running 6x and 11x faster, respectively. For visual understanding, Mobile-O surpasses them by 15.3% and 5.1% averaged across seven benchmarks. Running in only ~3s per 512x512 image on an iPhone, Mobile-O establishes the first practical framework for real-time unified multimodal understanding and generation on edge devices. We hope Mobile-O will ease future research in real-time unified multimodal intelligence running entirely on-device with no cloud dependency. Our code, models, datasets, and mobile application are publicly available at https://amshaker.github.io/Mobile-O/
Audit After Segmentation: Reference-Free Mask Quality Assessment for Language-Referred Audio-Visual Segmentation
Feb 03, 2026Language-referred audio-visual segmentation (Ref-AVS) aims to segment target objects described by natural language by jointly reasoning over video, audio, and text. Beyond generating segmentation masks, providing rich and interpretable diagnoses of mask quality remains largely underexplored. In this work, we introduce Mask Quality Assessment in the Ref-AVS context (MQA-RefAVS), a new task that evaluates the quality of candidate segmentation masks without relying on ground-truth annotations as references at inference time. Given audio-visual-language inputs and each provided segmentation mask, the task requires estimating its IoU with the unobserved ground truth, identifying the corresponding error type, and recommending an actionable quality-control decision. To support this task, we construct MQ-RAVSBench, a benchmark featuring diverse and representative mask error modes that span both geometric and semantic issues. We further propose MQ-Auditor, a multimodal large language model (MLLM)-based auditor that explicitly reasons over multimodal cues and mask information to produce quantitative and qualitative mask quality assessments. Extensive experiments demonstrate that MQ-Auditor outperforms strong open-source and commercial MLLMs and can be integrated with existing Ref-AVS systems to detect segmentation failures and support downstream segmentation improvement. Data and codes will be released at https://github.com/jasongief/MQA-RefAVS.
A Benchmark and Agentic Framework for Omni-Modal Reasoning and Tool Use in Long Videos
Dec 18, 2025Long-form multimodal video understanding requires integrating vision, speech, and ambient audio with coherent long-range reasoning. Existing benchmarks emphasize either temporal length or multimodal richness, but rarely both and while some incorporate open-ended questions and advanced metrics, they mostly rely on single-score accuracy, obscuring failure modes. We introduce LongShOTBench, a diagnostic benchmark with open-ended, intent-driven questions; single- and multi-turn dialogues; and tasks requiring multimodal reasoning and agentic tool use across video, audio, and speech. Each item includes a reference answer and graded rubric for interpretable, and traceable evaluation. LongShOTBench is produced via a scalable, human-validated pipeline to ensure coverage and reproducibility. All samples in our LongShOTBench are human-verified and corrected. Furthermore, we present LongShOTAgent, an agentic system that analyzes long videos via preprocessing, search, and iterative refinement. On LongShOTBench, state-of-the-art MLLMs show large gaps: Gemini-2.5-Flash achieves 52.95%, open-source models remain below 30%, and LongShOTAgent attains 44.66%. These results underscore the difficulty of real-world long-form video understanding. LongShOTBench provides a practical, reproducible foundation for evaluating and improving MLLMs. All resources are available on GitHub: https://github.com/mbzuai-oryx/longshot.
How Good are Foundation Models in Step-by-Step Embodied Reasoning?
Sep 18, 2025
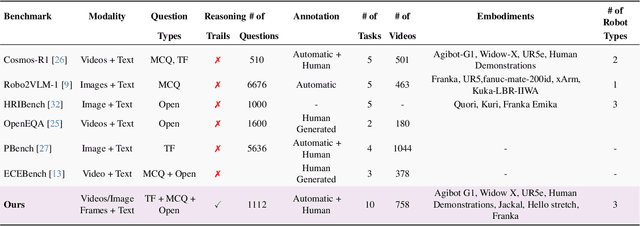
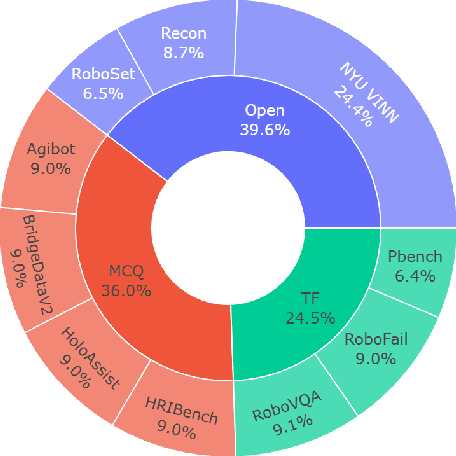

Embodied agents operating in the physical world must make decisions that are not only effective but also safe, spatially coherent, and grounded in context. While recent advances in large multimodal models (LMMs) have shown promising capabilities in visual understanding and language generation, their ability to perform structured reasoning for real-world embodied tasks remains underexplored. In this work, we aim to understand how well foundation models can perform step-by-step reasoning in embodied environments. To this end, we propose the Foundation Model Embodied Reasoning (FoMER) benchmark, designed to evaluate the reasoning capabilities of LMMs in complex embodied decision-making scenarios. Our benchmark spans a diverse set of tasks that require agents to interpret multimodal observations, reason about physical constraints and safety, and generate valid next actions in natural language. We present (i) a large-scale, curated suite of embodied reasoning tasks, (ii) a novel evaluation framework that disentangles perceptual grounding from action reasoning, and (iii) empirical analysis of several leading LMMs under this setting. Our benchmark includes over 1.1k samples with detailed step-by-step reasoning across 10 tasks and 8 embodiments, covering three different robot types. Our results highlight both the potential and current limitations of LMMs in embodied reasoning, pointing towards key challenges and opportunities for future research in robot intelligence. Our data and code will be made publicly available.