 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning on the Manifold: Unlocking Standard Diffusion Transformers with Representation Encoders
Feb 10, 2026Leveraging representation encoders for generative modeling offers a path for efficient, high-fidelity synthesis. However, standard diffusion transformers fail to converge on these representations directly. While recent work attributes this to a capacity bottleneck proposing computationally expensive width scaling of diffusion transformers we demonstrate that the failure is fundamentally geometric. We identify Geometric Interference as the root cause: standard Euclidean flow matching forces probability paths through the low-density interior of the hyperspherical feature space of representation encoders, rather than following the manifold surface. To resolve this, we propose Riemannian Flow Matching with Jacobi Regularization (RJF). By constraining the generative process to the manifold geodesics and correcting for curvature-induced error propagation, RJF enables standard Diffusion Transformer architectures to converge without width scaling. Our method RJF enables the standard DiT-B architecture (131M parameters) to converge effectively, achieving an FID of 3.37 where prior methods fail to converge. Code: https://github.com/amandpkr/RJF
Scale-Wise VAR is Secretly Discrete Diffusion
Sep 26, 2025Autoregressive (AR) transformers have emerged as a powerful paradigm for visual generation, largely due to their scalability, computational efficiency and unified architecture with language and vision. Among them, next scale prediction Visual Autoregressive Generation (VAR) has recently demonstrated remarkable performance, even surpassing diffusion-based models. In this work, we revisit VAR and uncover a theoretical insight: when equipped with a Markovian attention mask, VAR is mathematically equivalent to a discrete diffusion. We term this reinterpretation as Scalable Visual Refinement with Discrete Diffusion (SRDD), establishing a principled bridge between AR transformers and diffusion models. Leveraging this new perspective, we show how one can directly import the advantages of diffusion such as iterative refinement and reduce architectural inefficiencies into VAR, yielding faster convergence, lower inference cost, and improved zero-shot reconstruction. Across multiple datasets, we show that the diffusion based perspective of VAR leads to consistent gains in efficiency and generation.
Open-Set Semi-Supervised Learning for Long-Tailed Medical Datasets
May 20, 2025Many practical medical imaging scenarios include categories that are under-represented but still crucial. The relevance of image recognition models to real-world applications lies in their ability to generalize to these rare classes as well as unseen classes. Real-world generalization requires taking into account the various complexities that can be encountered in the real-world. First, training data is highly imbalanced, which may lead to model exhibiting bias toward the more frequently represented classes. Moreover, real-world data may contain unseen classes that need to be identified, and model performance is affected by the data scarcity. While medical image recognition has been extensively addressed in the literature, current methods do not take into account all the intricacies in the real-world scenarios. To this end, we propose an open-set learning method for highly imbalanced medical datasets using a semi-supervised approach. Understanding the adverse impact of long-tail distribution at the inherent model characteristics, we implement a regularization strategy at the feature level complemented by a classifier normalization technique. We conduct extensive experiments on the publicly available datasets, ISIC2018, ISIC2019, and TissueMNIST with various numbers of labelled samples. Our analysis shows that addressing the impact of long-tail data in classification significantly improves the overall performance of the network in terms of closed-set and open-set accuracies on all datasets. Our code and trained models will be made publicly available at https://github.com/Daniyanaj/OpenLTR.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
AgroGPT: Efficient Agricultural Vision-Language Model with Expert Tuning
Oct 10, 2024Significant progress has been made in advancing large multimodal conversational models (LMMs), capitalizing on vast repositories of image-text data available online. Despite this progress, these models often encounter substantial domain gaps, hindering their ability to engage in complex conversations across new domains. Recent efforts have aimed to mitigate this issue, albeit relying on domain-specific image-text data to curate instruction-tuning data. However, many domains, such as agriculture, lack such vision-language data. In this work, we propose an approach to construct instruction-tuning data that harnesses vision-only data for the agriculture domain. We utilize diverse agricultural datasets spanning multiple domains, curate class-specific information, and employ large language models (LLMs) to construct an expert-tuning set, resulting in a 70k expert-tuning dataset called AgroInstruct. Subsequently, we expert-tuned and created AgroGPT, an efficient LMM that can hold complex agriculture-related conversations and provide useful insights. We also develop AgroEvals for evaluation and compare {AgroGPT's} performance with large open and closed-source models. {AgroGPT} excels at identifying fine-grained agricultural concepts, can act as an agriculture expert, and provides helpful information for multimodal agriculture questions. The code, datasets, and models are available at https://github.com/awaisrauf/agroGPT.
Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning
Jun 06, 2024Drawing upon StyleGAN's expressivity and disentangled latent space, existing 2D approaches employ textual prompting to edit facial images with different attributes. In contrast, 3D-aware approaches that generate faces at different target poses require attribute-specific classifiers, learning separate model weights for each attribute, and are not scalable for novel attributes. In this work, we propose an efficient, plug-and-play, 3D-aware face editing framework based on attribute-specific prompt learning, enabling the generation of facial images with controllable attributes across various target poses. To this end, we introduce a text-driven learnable style token-based latent attribute editor (LAE). The LAE harnesses a pre-trained vision-language model to find text-guided attribute-specific editing direction in the latent space of any pre-trained 3D-aware GAN. It utilizes learnable style tokens and style mappers to learn and transform this editing direction to 3D latent space. To train LAE with multiple attributes, we use directional contrastive loss and style token loss. Furthermore, to ensure view consistency and identity preservation across different poses and attributes, we employ several 3D-aware identity and pose preservation losses. Our experiments show that our proposed framework generates high-quality images with 3D awareness and view consistency while maintaining attribute-specific features. We demonstrate the effectiveness of our method on different facial attributes, including hair color and style, expression, and others. Code: https://github.com/VIROBO-15/Efficient-3D-Aware-Facial-Image-Editing.
Multi-modal Generation via Cross-Modal In-Context Learning
May 28, 2024

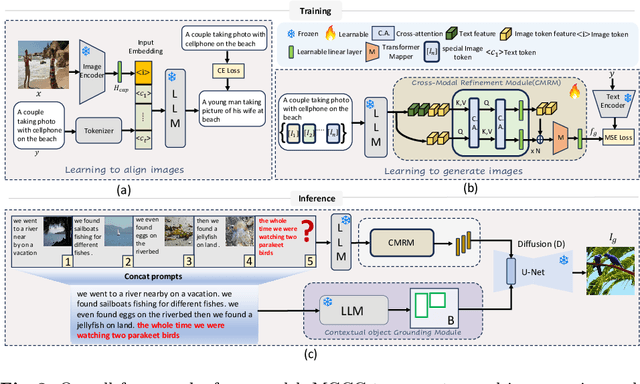

In this work, we study the problem of generating novel images from complex multimodal prompt sequences. While existing methods achieve promising results for text-to-image generation, they often struggle to capture fine-grained details from lengthy prompts and maintain contextual coherence within prompt sequences. Moreover, they often result in misaligned image generation for prompt sequences featuring multiple objects. To address this, we propose a Multi-modal Generation via Cross-Modal In-Context Learning (MGCC) method that generates novel images from complex multimodal prompt sequences by leveraging the combined capabilities of large language models (LLMs) and diffusion models. Our MGCC comprises a novel Cross-Modal Refinement module to explicitly learn cross-modal dependencies between the text and image in the LLM embedding space, and a contextual object grounding module to generate object bounding boxes specifically targeting scenes with multiple objects. Our MGCC demonstrates a diverse range of multimodal capabilities, like novel image generation, the facilitation of multimodal dialogue, and generation of texts. Experimental evaluations on two benchmark datasets, demonstrate the effectiveness of our method. On Visual Story Generation (VIST) dataset with multimodal inputs, our MGCC achieves a CLIP Similarity score of $0.652$ compared to SOTA GILL $0.641$. Similarly, on Visual Dialogue Context (VisDial) having lengthy dialogue sequences, our MGCC achieves an impressive CLIP score of $0.660$, largely outperforming existing SOTA method scoring $0.645$. Code: https://github.com/VIROBO-15/MGCC
Distilling Local Texture Features for Colorectal Tissue Classification in Low Data Regimes
Jan 02, 2024Multi-class colorectal tissue classification is a challenging problem that is typically addressed in a setting, where it is assumed that ample amounts of training data is available. However, manual annotation of fine-grained colorectal tissue samples of multiple classes, especially the rare ones like stromal tumor and anal cancer is laborious and expensive. To address this, we propose a knowledge distillation-based approach, named KD-CTCNet, that effectively captures local texture information from few tissue samples, through a distillation loss, to improve the standard CNN features. The resulting enriched feature representation achieves improved classification performance specifically in low data regimes. Extensive experiments on two public datasets of colorectal tissues reveal the merits of the proposed contributions, with a consistent gain achieved over different approaches across low data settings. The code and models are publicly available on GitHub.
Cross-modulated Few-shot Image Generation for Colorectal Tissue Classification
Apr 04, 2023In this work, we propose a few-shot colorectal tissue image generation method for addressing the scarcity of histopathological training data for rare cancer tissues. Our few-shot generation method, named XM-GAN, takes one base and a pair of reference tissue images as input and generates high-quality yet diverse images. Within our XM-GAN, a novel controllable fusion block densely aggregates local regions of reference images based on their similarity to those in the base image, resulting in locally consistent features. To the best of our knowledge, we are the first to investigate few-shot generation in colorectal tissue images. We evaluate our few-shot colorectral tissue image generation by performing extensive qualitative, quantitative and subject specialist (pathologist) based evaluations. Specifically, in specialist-based evaluation, pathologists could differentiate between our XM-GAN generated tissue images and real images only 55% time. Moreover, we utilize these generated images as data augmentation to address the few-shot tissue image classification task, achieving a gain of 4.4% in terms of mean accuracy over the vanilla few-shot classifier. Code: \url{https://github.com/VIROBO-15/XM-GAN}
Generative Multiplane Neural Radiance for 3D-Aware Image Generation
Apr 03, 2023
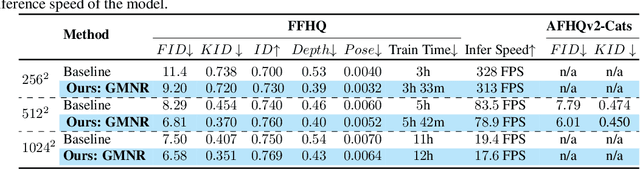


We present a method to efficiently generate 3D-aware high-resolution images that are view-consistent across multiple target views. The proposed multiplane neural radiance model, named GMNR, consists of a novel {\alpha}-guided view-dependent representation ({\alpha}-VdR) module for learning view-dependent information. The {\alpha}-VdR module, faciliated by an {\alpha}-guided pixel sampling technique, computes the view-dependent representation efficiently by learning viewing direction and position coefficients. Moreover, we propose a view-consistency loss to enforce photometric similarity across multiple views. The GMNR model can generate 3D-aware high-resolution images that are viewconsistent across multiple camera poses, while maintaining the computational efficiency in terms of both training and inference time. Experiments on three datasets demonstrate the effectiveness of the proposed modules, leading to favorable results in terms of both generation quality and inference time, compared to existing approaches. Our GMNR model generates 3D-aware images of 1024 X 1024 pixels with 17.6 FPS on a single V100. Code : https://github.com/VIROBO-15/GMNR