 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenEarthAgent: A Unified Framework for Tool-Augmented Geospatial Agents
Feb 19, 2026Recent progress in multimodal reasoning has enabled agents that can interpret imagery, connect it with language, and perform structured analytical tasks. Extending such capabilities to the remote sensing domain remains challenging, as models must reason over spatial scale, geographic structures, and multispectral indices while maintaining coherent multi-step logic. To bridge this gap, OpenEarthAgent introduces a unified framework for developing tool-augmented geospatial agents trained on satellite imagery, natural-language queries, and detailed reasoning traces. The training pipeline relies on supervised fine-tuning over structured reasoning trajectories, aligning the model with verified multistep tool interactions across diverse analytical contexts. The accompanying corpus comprises 14,538 training and 1,169 evaluation instances, with more than 100K reasoning steps in the training split and over 7K reasoning steps in the evaluation split. It spans urban, environmental, disaster, and infrastructure domains, and incorporates GIS-based operations alongside index analyses such as NDVI, NBR, and NDBI. Grounded in explicit reasoning traces, the learned agent demonstrates structured reasoning, stable spatial understanding, and interpretable behaviour through tool-driven geospatial interactions across diverse conditions. We report consistent improvements over a strong baseline and competitive performance relative to recent open and closed-source models.
EoCD: Encoder only Remote Sensing Change Detection
Feb 05, 2026Being a cornerstone of temporal analysis, change detection has been playing a pivotal role in modern earth observation. Existing change detection methods rely on the Siamese encoder to individually extract temporal features followed by temporal fusion. Subsequently, these methods design sophisticated decoders to improve the change detection performance without taking into consideration the complexity of the model. These aforementioned issues intensify the overall computational cost as well as the network's complexity which is undesirable. Alternatively, few methods utilize the early fusion scheme to combine the temporal images. These methods prevent the extra overhead of Siamese encoder, however, they also rely on sophisticated decoders for better performance. In addition, these methods demonstrate inferior performance as compared to late fusion based methods. To bridge these gaps, we introduce encoder only change detection (EoCD) that is a simple and effective method for the change detection task. The proposed method performs the early fusion of the temporal data and replaces the decoder with a parameter-free multiscale feature fusion module thereby significantly reducing the overall complexity of the model. EoCD demonstrate the optimal balance between the change detection performance and the prediction speed across a variety of encoder architectures. Additionally, EoCD demonstrate that the performance of the model is predominantly dependent on the encoder network, making the decoder an additional component. Extensive experimentation on four challenging change detection datasets reveals the effectiveness of the proposed method.
HyRet-Change: A hybrid retentive network for remote sensing change detection
Jun 15, 2025Recently convolution and transformer-based change detection (CD) methods provide promising performance. However, it remains unclear how the local and global dependencies interact to effectively alleviate the pseudo changes. Moreover, directly utilizing standard self-attention presents intrinsic limitations including governing global feature representations limit to capture subtle changes, quadratic complexity, and restricted training parallelism. To address these limitations, we propose a Siamese-based framework, called HyRet-Change, which can seamlessly integrate the merits of convolution and retention mechanisms at multi-scale features to preserve critical information and enhance adaptability in complex scenes. Specifically, we introduce a novel feature difference module to exploit both convolutions and multi-head retention mechanisms in a parallel manner to capture complementary information. Furthermore, we propose an adaptive local-global interactive context awareness mechanism that enables mutual learning and enhances discrimination capability through information exchange. We perform experiments on three challenging CD datasets and achieve state-of-the-art performance compared to existing methods. Our source code is publicly available at https://github.com/mustansarfiaz/HyRect-Change.
* Accepted at IEEE IGARSS 2025
InceptionMamba: Efficient Multi-Stage Feature Enhancement with Selective State Space Model for Microscopic Medical Image Segmentation
Jun 13, 2025Accurate microscopic medical image segmentation plays a crucial role in diagnosing various cancerous cells and identifying tumors. Driven by advancements in deep learning, convolutional neural networks (CNNs) and transformer-based models have been extensively studied to enhance receptive fields and improve medical image segmentation task. However, they often struggle to capture complex cellular and tissue structures in challenging scenarios such as background clutter and object overlap. Moreover, their reliance on the availability of large datasets for improved performance, along with the high computational cost, limit their practicality. To address these issues, we propose an efficient framework for the segmentation task, named InceptionMamba, which encodes multi-stage rich features and offers both performance and computational efficiency. Specifically, we exploit semantic cues to capture both low-frequency and high-frequency regions to enrich the multi-stage features to handle the blurred region boundaries (e.g., cell boundaries). These enriched features are input to a hybrid model that combines an Inception depth-wise convolution with a Mamba block, to maintain high efficiency and capture inherent variations in the scales and shapes of the regions of interest. These enriched features along with low-resolution features are fused to get the final segmentation mask. Our model achieves state-of-the-art performance on two challenging microscopic segmentation datasets (SegPC21 and GlaS) and two skin lesion segmentation datasets (ISIC2017 and ISIC2018), while reducing computational cost by about 5 times compared to the previous best performing method.
Open-Set Semi-Supervised Learning for Long-Tailed Medical Datasets
May 20, 2025Many practical medical imaging scenarios include categories that are under-represented but still crucial. The relevance of image recognition models to real-world applications lies in their ability to generalize to these rare classes as well as unseen classes. Real-world generalization requires taking into account the various complexities that can be encountered in the real-world. First, training data is highly imbalanced, which may lead to model exhibiting bias toward the more frequently represented classes. Moreover, real-world data may contain unseen classes that need to be identified, and model performance is affected by the data scarcity. While medical image recognition has been extensively addressed in the literature, current methods do not take into account all the intricacies in the real-world scenarios. To this end, we propose an open-set learning method for highly imbalanced medical datasets using a semi-supervised approach. Understanding the adverse impact of long-tail distribution at the inherent model characteristics, we implement a regularization strategy at the feature level complemented by a classifier normalization technique. We conduct extensive experiments on the publicly available datasets, ISIC2018, ISIC2019, and TissueMNIST with various numbers of labelled samples. Our analysis shows that addressing the impact of long-tail data in classification significantly improves the overall performance of the network in terms of closed-set and open-set accuracies on all datasets. Our code and trained models will be made publicly available at https://github.com/Daniyanaj/OpenLTR.
EarthDial: Turning Multi-sensory Earth Observations to Interactive Dialogues
Dec 19, 2024



Automated analysis of vast Earth observation data via interactive Vision-Language Models (VLMs) can unlock new opportunities for environmental monitoring, disaster response, and resource management. Existing generic VLMs do not perform well on Remote Sensing data, while the recent Geo-spatial VLMs remain restricted to a fixed resolution and few sensor modalities. In this paper, we introduce EarthDial, a conversational assistant specifically designed for Earth Observation (EO) data, transforming complex, multi-sensory Earth observations into interactive, natural language dialogues. EarthDial supports multi-spectral, multi-temporal, and multi-resolution imagery, enabling a wide range of remote sensing tasks, including classification, detection, captioning, question answering, visual reasoning, and visual grounding. To achieve this, we introduce an extensive instruction tuning dataset comprising over 11.11M instruction pairs covering RGB, Synthetic Aperture Radar (SAR), and multispectral modalities such as Near-Infrared (NIR) and infrared. Furthermore, EarthDial handles bi-temporal and multi-temporal sequence analysis for applications like change detection. Our extensive experimental results on 37 downstream applications demonstrate that EarthDial outperforms existing generic and domain-specific models, achieving better generalization across various EO tasks.
CLIP meets DINO for Tuning Zero-Shot Classifier using Unlabeled Image Collections
Nov 28, 2024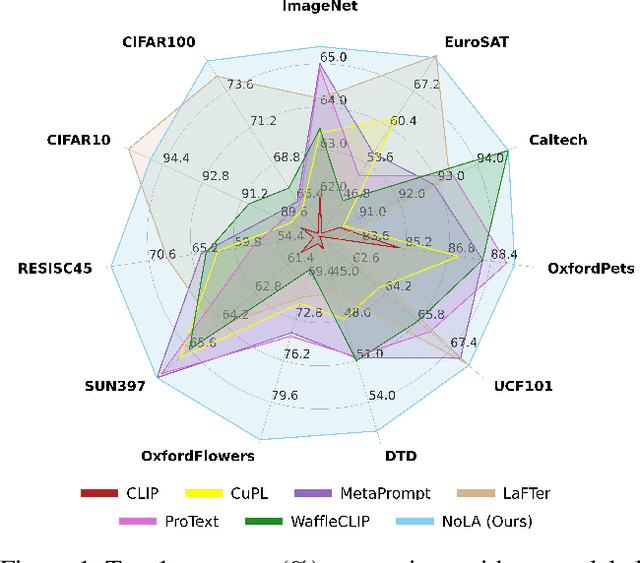
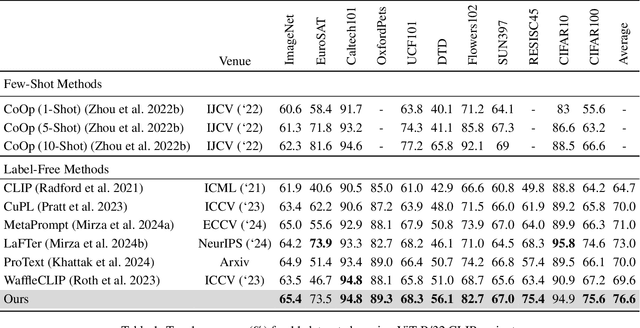
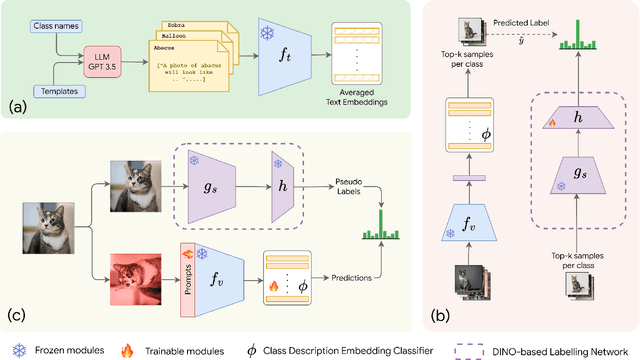
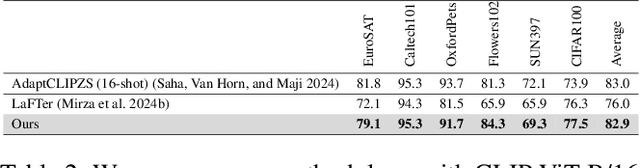
In the era of foundation models, CLIP has emerged as a powerful tool for aligning text and visual modalities into a common embedding space. However, the alignment objective used to train CLIP often results in subpar visual features for fine-grained tasks. In contrast, SSL-pretrained models like DINO excel at extracting rich visual features due to their specialized training paradigm. Yet, these SSL models require an additional supervised linear probing step, which relies on fully labeled data which is often expensive and difficult to obtain at scale. In this paper, we propose a label-free prompt-tuning method that leverages the rich visual features of self-supervised learning models (DINO) and the broad textual knowledge of large language models (LLMs) to largely enhance CLIP-based image classification performance using unlabeled images. Our approach unfolds in three key steps: (1) We generate robust textual feature embeddings that more accurately represent object classes by leveraging class-specific descriptions from LLMs, enabling more effective zero-shot classification compared to CLIP's default name-specific prompts. (2) These textual embeddings are then used to produce pseudo-labels to train an alignment module that integrates the complementary strengths of LLM description-based textual embeddings and DINO's visual features. (3) Finally, we prompt-tune CLIP's vision encoder through DINO-assisted supervision using the trained alignment module. This three-step process allows us to harness the best of visual and textual foundation models, resulting in a powerful and efficient approach that surpasses state-of-the-art label-free classification methods. Notably, our framework, NoLA (No Labels Attached), achieves an average absolute gain of 3.6% over the state-of-the-art LaFter across 11 diverse image classification datasets.
COSNet: A Novel Semantic Segmentation Network using Enhanced Boundaries in Cluttered Scenes
Oct 31, 2024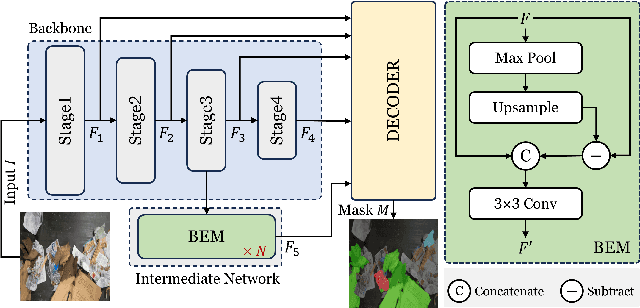

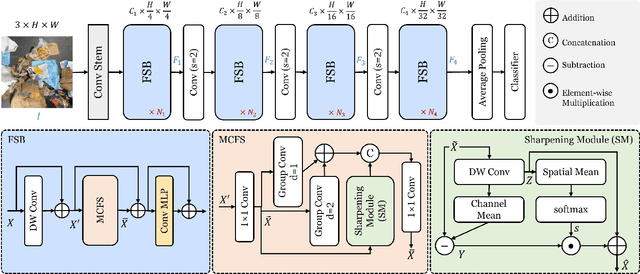

Automated waste recycling aims to efficiently separate the recyclable objects from the waste by employing vision-based systems. However, the presence of varying shaped objects having different material types makes it a challenging problem, especially in cluttered environments. Existing segmentation methods perform reasonably on many semantic segmentation datasets by employing multi-contextual representations, however, their performance is degraded when utilized for waste object segmentation in cluttered scenarios. In addition, plastic objects further increase the complexity of the problem due to their translucent nature. To address these limitations, we introduce an efficacious segmentation network, named COSNet, that uses boundary cues along with multi-contextual information to accurately segment the objects in cluttered scenes. COSNet introduces novel components including feature sharpening block (FSB) and boundary enhancement module (BEM) for enhancing the features and highlighting the boundary information of irregular waste objects in cluttered environment. Extensive experiments on three challenging datasets including ZeroWaste-f, SpectralWaste, and ADE20K demonstrate the effectiveness of the proposed method. Our COSNet achieves a significant gain of 1.8% on ZeroWaste-f and 2.1% on SpectralWaste datasets respectively in terms of mIoU metric.
Improving 3D Medical Image Segmentation at Boundary Regions using Local Self-attention and Global Volume Mixing
Oct 20, 2024



Volumetric medical image segmentation is a fundamental problem in medical image analysis where the objective is to accurately classify a given 3D volumetric medical image with voxel-level precision. In this work, we propose a novel hierarchical encoder-decoder-based framework that strives to explicitly capture the local and global dependencies for volumetric 3D medical image segmentation. The proposed framework exploits local volume-based self-attention to encode the local dependencies at high resolution and introduces a novel volumetric MLP-mixer to capture the global dependencies at low-resolution feature representations, respectively. The proposed volumetric MLP-mixer learns better associations among volumetric feature representations. These explicit local and global feature representations contribute to better learning of the shape-boundary characteristics of the organs. Extensive experiments on three different datasets reveal that the proposed method achieves favorable performance compared to state-of-the-art approaches. On the challenging Synapse Multi-organ dataset, the proposed method achieves an absolute 3.82\% gain over the state-of-the-art approaches in terms of HD95 evaluation metrics {while a similar improvement pattern is exhibited in MSD Liver and Pancreas tumor datasets}. We also provide a detailed comparison between recent architectural design choices in the 2D computer vision literature by adapting them for the problem of 3D medical image segmentation. Finally, our experiments on the ZebraFish 3D cell membrane dataset having limited training data demonstrate the superior transfer learning capabilities of the proposed vMixer model on the challenging 3D cell instance segmentation task, where accurate boundary prediction plays a vital role in distinguishing individual cell instances.
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Aug 30, 2024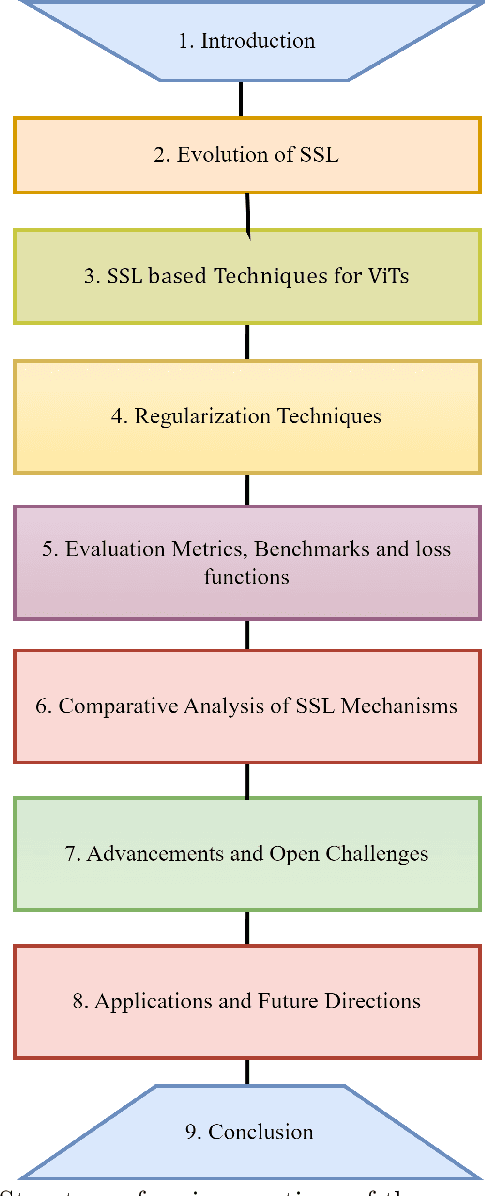
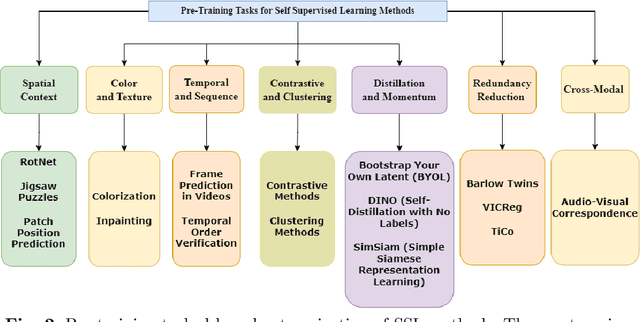
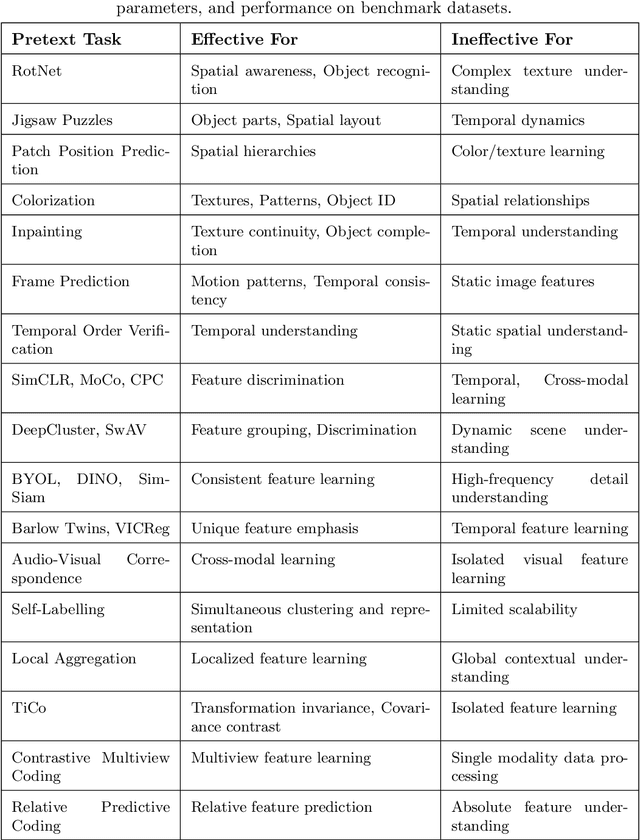
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.