 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyRet-Change: A hybrid retentive network for remote sensing change detection
Jun 15, 2025Recently convolution and transformer-based change detection (CD) methods provide promising performance. However, it remains unclear how the local and global dependencies interact to effectively alleviate the pseudo changes. Moreover, directly utilizing standard self-attention presents intrinsic limitations including governing global feature representations limit to capture subtle changes, quadratic complexity, and restricted training parallelism. To address these limitations, we propose a Siamese-based framework, called HyRet-Change, which can seamlessly integrate the merits of convolution and retention mechanisms at multi-scale features to preserve critical information and enhance adaptability in complex scenes. Specifically, we introduce a novel feature difference module to exploit both convolutions and multi-head retention mechanisms in a parallel manner to capture complementary information. Furthermore, we propose an adaptive local-global interactive context awareness mechanism that enables mutual learning and enhances discrimination capability through information exchange. We perform experiments on three challenging CD datasets and achieve state-of-the-art performance compared to existing methods. Our source code is publicly available at https://github.com/mustansarfiaz/HyRect-Change.
* Accepted at IEEE IGARSS 2025
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Aug 30, 2024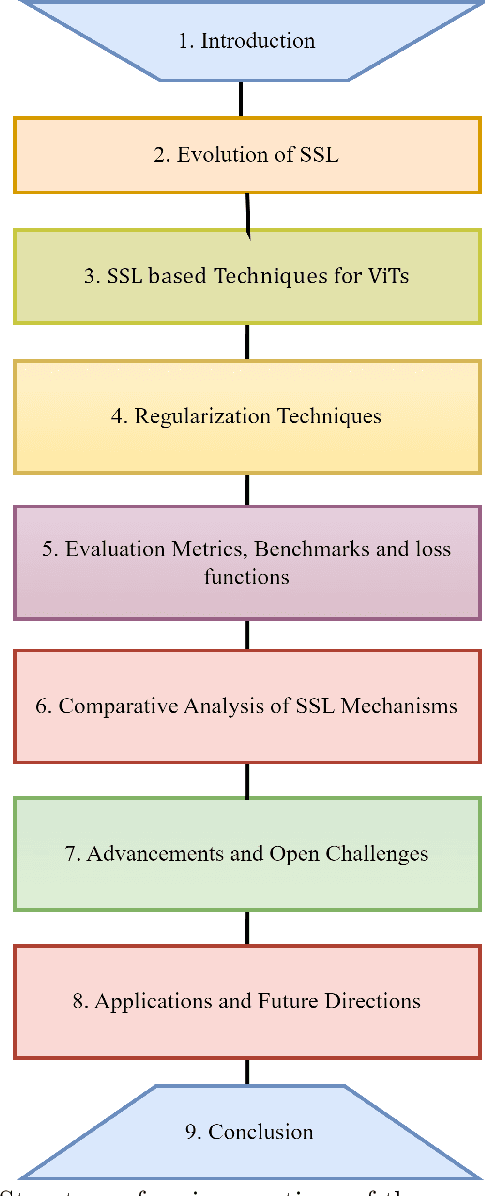
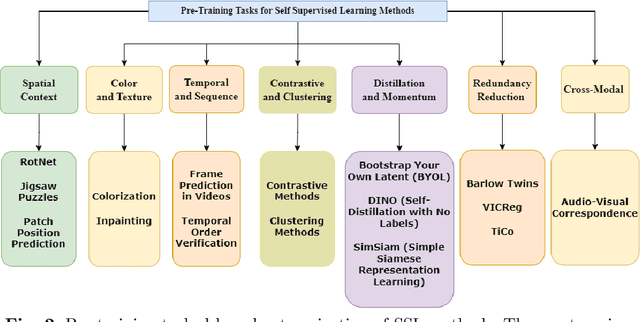
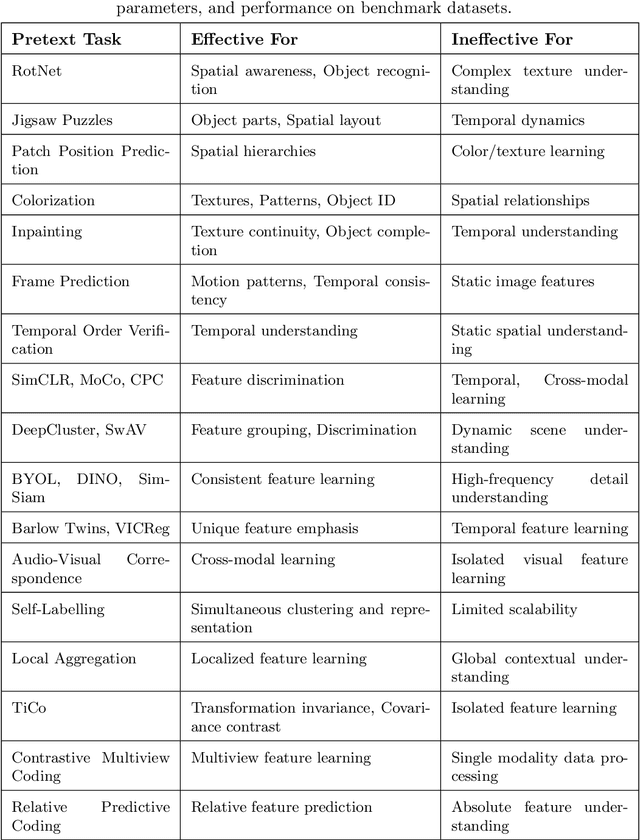
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
A Unified Transformer-based Network for multimodal Emotion Recognition
Aug 27, 2023

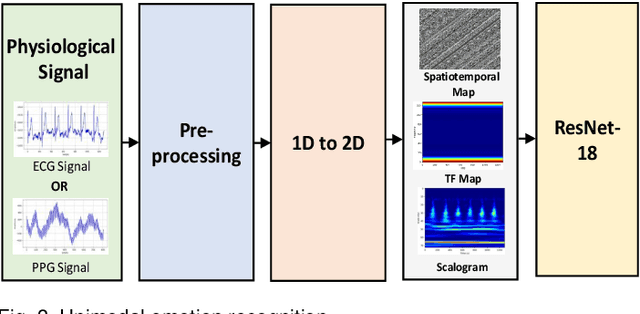
The development of transformer-based models has resulted in significant advances in addressing various vision and NLP-based research challenges. However, the progress made in transformer-based methods has not been effectively applied to biosensing research. This paper presents a novel Unified Biosensor-Vision Multi-modal Transformer-based (UBVMT) method to classify emotions in an arousal-valence space by combining a 2D representation of an ECG/PPG signal with the face information. To achieve this goal, we first investigate and compare the unimodal emotion recognition performance of three image-based representations of the ECG/PPG signal. We then present our UBVMT network which is trained to perform emotion recognition by combining the 2D image-based representation of the ECG/PPG signal and the facial expression features. Our unified transformer model consists of homogeneous transformer blocks that take as an input the 2D representation of the ECG/PPG signal and the corresponding face frame for emotion representation learning with minimal modality-specific design. Our UBVMT model is trained by reconstructing masked patches of video frames and 2D images of ECG/PPG signals, and contrastive modeling to align face and ECG/PPG data. Extensive experiments on the MAHNOB-HCI and DEAP datasets show that our Unified UBVMT-based model produces comparable results to the state-of-the-art techniques.
Fine-grained Vibration Based Sensing Using a Smartphone
Jul 08, 2020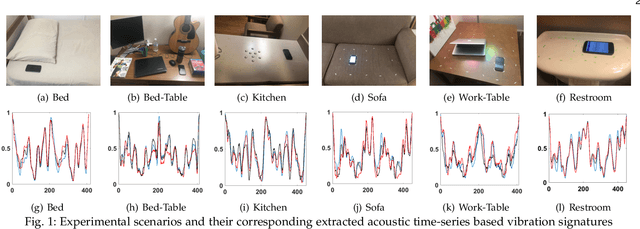
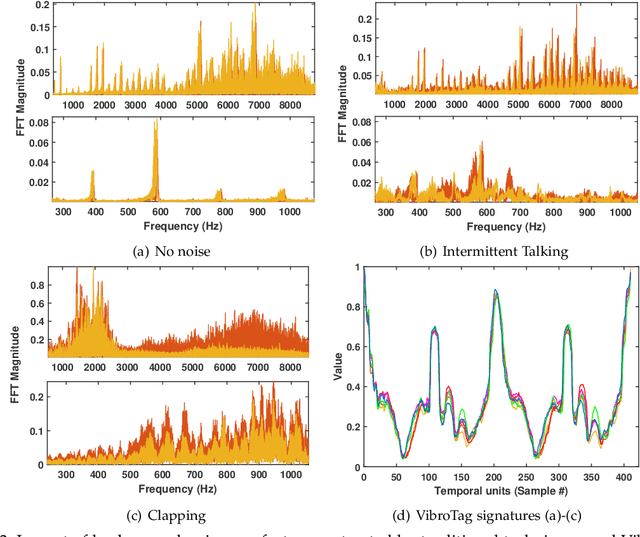
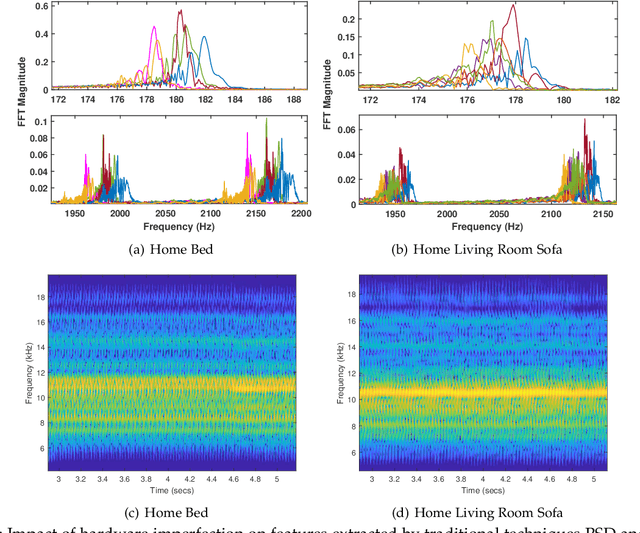
Recognizing surfaces based on their vibration signatures is useful as it can enable tagging of different locations without requiring any additional hardware such as Near Field Communication (NFC) tags. However, previous vibration based surface recognition schemes either use custom hardware for creating and sensing vibration, which makes them difficult to adopt, or use inertial (IMU) sensors in commercial off-the-shelf (COTS) smartphones to sense movements produced due to vibrations, which makes them coarse-grained because of the low sampling rates of IMU sensors. The mainstream COTS smartphones based schemes are also susceptible to inherent hardware based irregularities in vibration mechanism of the smartphones. Moreover, the existing schemes that use microphones to sense vibration are prone to short-term and constant background noises (e.g. intermittent talking, exhaust fan, etc.) because microphones not only capture the sounds created by vibration but also other interfering sounds present in the environment. In this paper, we propose VibroTag, a robust and practical vibration based sensing scheme that works with smartphones with different hardware, can extract fine-grained vibration signatures of different surfaces, and is robust to environmental noise and hardware based irregularities. We implemented VibroTag on two different Android phones and evaluated in multiple different environments where we collected data from 4 individuals for 5 to 20 consecutive days. Our results show that VibroTag achieves an average accuracy of 86.55% while recognizing 24 different locations/surfaces, even when some of those surfaces were made of similar material. VibroTag's accuracy is 37% higher than the average accuracy of 49.25% achieved by one of the state-of-the-art IMUs based schemes, which we implemented for comparison with VibroTag.
Monitoring Browsing Behavior of Customers in Retail Stores via RFID Imaging
Jul 07, 2020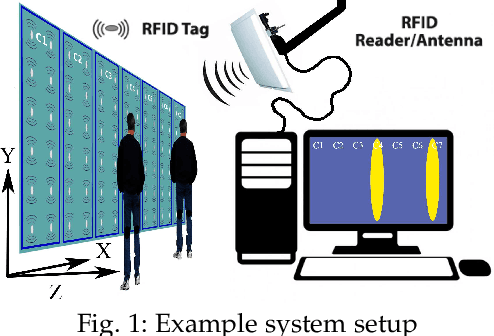
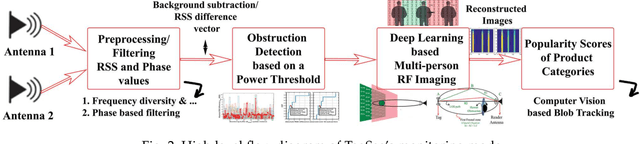
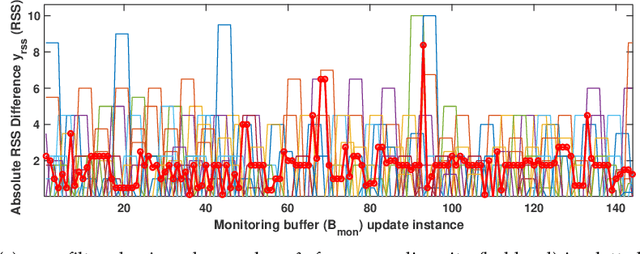
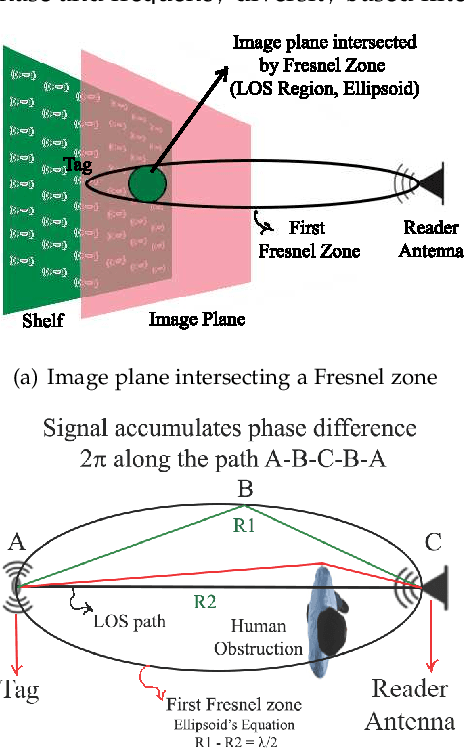
In this paper, we propose to use commercial off-the-shelf (COTS) monostatic RFID devices (i.e. which use a single antenna at a time for both transmitting and receiving RFID signals to and from the tags) to monitor browsing activity of customers in front of display items in places such as retail stores. To this end, we propose TagSee, a multi-person imaging system based on monostatic RFID imaging. TagSee is based on the insight that when customers are browsing the items on a shelf, they stand between the tags deployed along the boundaries of the shelf and the reader, which changes the multi-paths that the RFID signals travel along, and both the RSS and phase values of the RFID signals that the reader receives change. Based on these variations observed by the reader, TagSee constructs a coarse grained image of the customers. Afterwards, TagSee identifies the items that are being browsed by the customers by analyzing the constructed images. The key novelty of this paper is on achieving browsing behavior monitoring of multiple customers in front of display items by constructing coarse grained images via robust, analytical model-driven deep learning based, RFID imaging. To achieve this, we first mathematically formulate the problem of imaging humans using monostatic RFID devices and derive an approximate analytical imaging model that correlates the variations caused by human obstructions in the RFID signals. Based on this model, we then develop a deep learning framework to robustly image customers with high accuracy. We implement TagSee scheme using a Impinj Speedway R420 reader and SMARTRAC DogBone RFID tags. TagSee can achieve a TPR of more than ~90% and a FPR of less than ~10% in multi-person scenarios using training data from just 3-4 users.
An Efficient Integration of Disentangled Attended Expression and Identity FeaturesFor Facial Expression Transfer andSynthesis
May 01, 2020
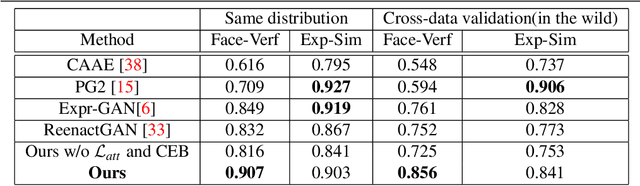

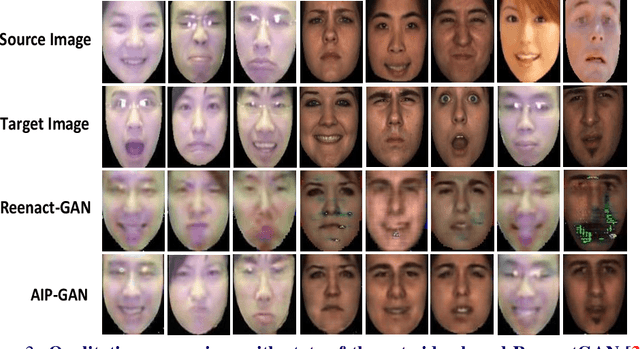
In this paper, we present an Attention-based Identity Preserving Generative Adversarial Network (AIP-GAN) to overcome the identity leakage problem from a source image to a generated face image, an issue that is encountered in a cross-subject facial expression transfer and synthesis process. Our key insight is that the identity preserving network should be able to disentangle and compose shape, appearance, and expression information for efficient facial expression transfer and synthesis. Specifically, the expression encoder of our AIP-GAN disentangles the expression information from the input source image by predicting its facial landmarks using our supervised spatial and channel-wise attention module. Similarly, the disentangled expression-agnostic identity features are extracted from the input target image by inferring its combined intrinsic-shape and appearance image employing our self-supervised spatial and channel-wise attention mod-ule. To leverage the expression and identity information encoded by the intermediate layers of both of our encoders, we combine these features with the features learned by the intermediate layers of our decoder using a cross-encoder bilinear pooling operation. Experimental results show the promising performance of our AIP-GAN based technique.
AI4COVID-19: AI Enabled Preliminary Diagnosis for COVID-19 from Cough Samples via an App
Apr 16, 2020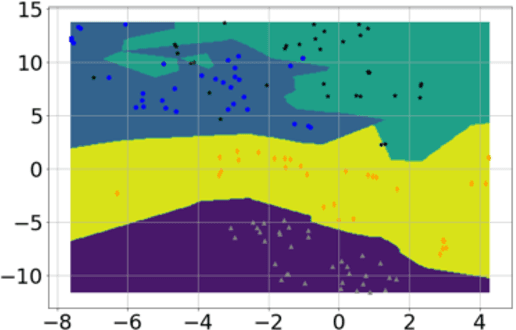
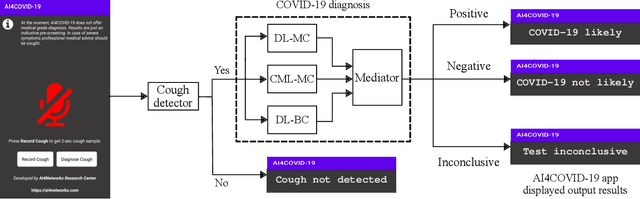
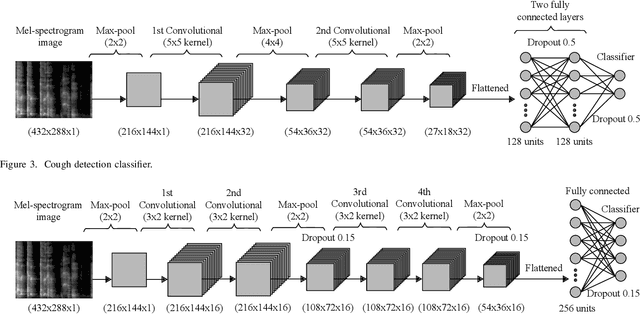
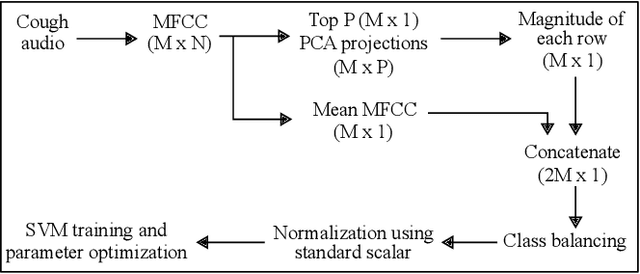
Inability to test at scale has become Achille's heel in humanity's ongoing war against COVID-19 pandemic. An agile, scalable and cost-effective testing, deployable at a global scale, can act as a game changer in this war. To address this challenge, building on the promising results of our prior work on cough-based diagnosis of a motley of respiratory diseases, we develop an Artificial Intelligence (AI)-based test for COVID-19 preliminary diagnosis. The test is deployable at scale through a mobile app named AI4COVID-19. The AI4COVID-19 app requires 2-second cough recordings of the subject. By analyzing the cough samples through an AI engine running in the cloud, the app returns a preliminary diagnosis within a minute. Unfortunately, cough is common symptom of over two dozen non-COVID-19 related medical conditions. This makes the COVID-19 diagnosis from cough alone an extremely challenging problem. We solve this problem by developing a novel multi-pronged mediator centered risk-averse AI architecture that minimizes misdiagnosis. At the time of writing, our AI engine can distinguish between COVID-19 patient coughs and several types of non-COVID-19 coughs with over 90% accuracy. AI4COVID-19's performance is likely to improve as more and better data becomes available. This paper presents a proof of concept to encourage controlled clinical trials and serves as a call for labeled cough data. AI4COVID-19 is not designed to compete with clinical testing. Instead, it offers a complementing tele-testing tool deployable anytime, anywhere, by anyone, so clinical-testing and treatment can be channeled to those who need it the most, thereby saving more lives.
Facial Expression Representation Learning by Synthesizing Expression Images
Nov 30, 2019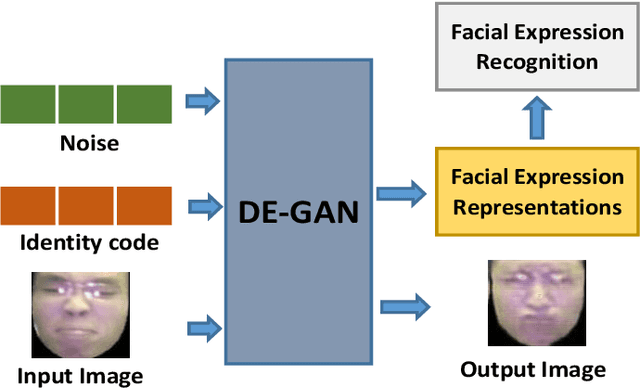
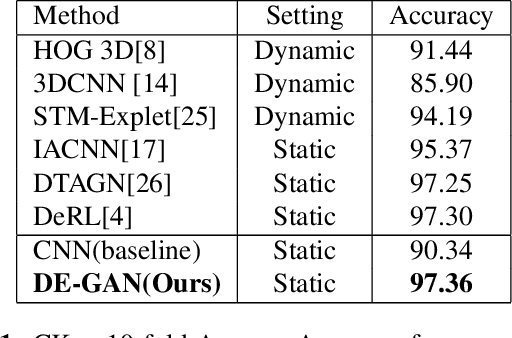
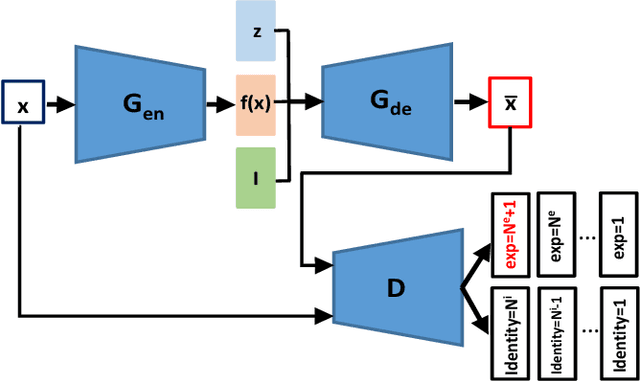
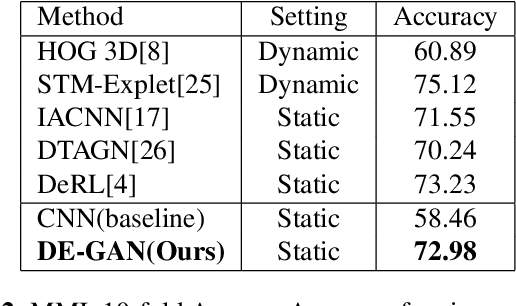
Representations used for Facial Expression Recognition (FER) usually contain expression information along with identity features. In this paper, we propose a novel Disentangled Expression learning-Generative Adversarial Network (DE-GAN) which combines the concept of disentangled representation learning with residue learning to explicitly disentangle facial expression representation from identity information. In this method the facial expression representation is learned by reconstructing an expression image employing an encoder-decoder based generator. Unlike previous works using only expression residual learning for facial expression recognition, our method learns the disentangled expression representation along with the expressive component recorded by the encoder of DE-GAN. In order to improve the quality of synthesized expression images and the effectiveness of the learned disentangled expression representation, expression and identity classification is performed by the discriminator of DE-GAN. Experiments performed on widely used datasets (CK+, MMI, Oulu-CASIA) show that the proposed technique produces comparable or better results than state-of-the-art methods.
All-In-One: Facial Expression Transfer, Editing and Recognition Using A Single Network
Nov 16, 2019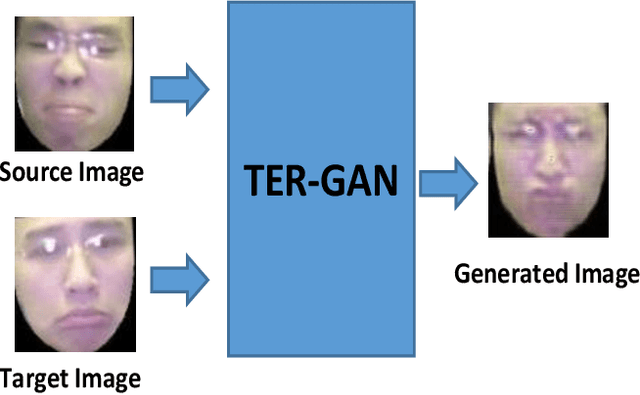
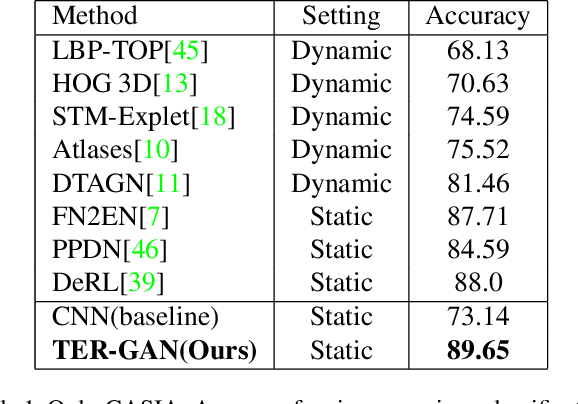
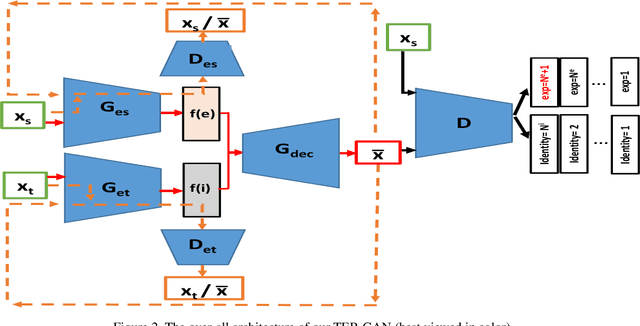

In this paper, we present a unified architecture known as Transfer-Editing and Recognition Generative Adversarial Network (TER-GAN) which can be used: 1. to transfer facial expressions from one identity to another identity, known as Facial Expression Transfer (FET), 2. to transform the expression of a given image to a target expression, while preserving the identity of the image, known as Facial Expression Editing (FEE), and 3. to recognize the facial expression of a face image, known as Facial Expression Recognition (FER). In TER-GAN, we combine the capabilities of generative models to generate synthetic images, while learning important information about the input images during the reconstruction process. More specifically, two encoders are used in TER-GAN to encode identity and expression information from two input images, and a synthetic expression image is generated by the decoder part of TER-GAN. To improve the feature disentanglement and extraction process, we also introduce a novel expression consistency loss and an identity consistency loss which exploit extra expression and identity information from generated images. Experimental results show that the proposed method can be used for efficient facial expression transfer, facial expression editing and facial expression recognition. In order to evaluate the proposed technique and to compare our results with state-of-the-art methods, we have used the Oulu-CASIA dataset for our experiments.
Facial Expression Recognition Using Human to Animated-Character Expression Translation
Oct 12, 2019

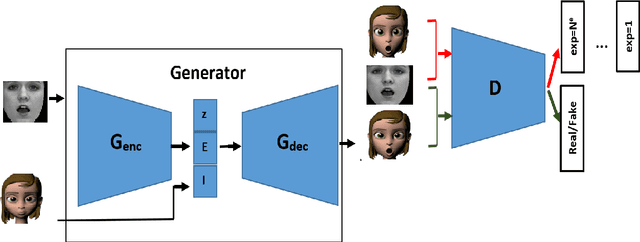

Facial expression recognition is a challenging task due to two major problems: the presence of inter-subject variations in facial expression recognition dataset and impure expressions posed by human subjects. In this paper we present a novel Human-to-Animation conditional Generative Adversarial Network (HA-GAN) to overcome these two problems by using many (human faces) to one (animated face) mapping. Specifically, for any given input human expression image, our HA-GAN transfers the expression information from the input image to a fixed animated identity. Stylized animated characters from the Facial Expression Research Group-Database (FERGDB) are used for the generation of fixed identity. By learning this many-to-one identity mapping function using our proposed HA-GAN, the effect of inter-subject variations can be reduced in Facial Expression Recognition(FER). We also argue that the expressions in the generated animated images are pure expressions and since FER is performed on these generated images, the performance of facial expression recognition is improved. Our initial experimental results on the state-of-the-art datasets show that facial expression recognition carried out on the generated animated images using our HA-GAN framework outperforms the baseline deep neural network and produces comparable or even better results than the state-of-the-art methods for facial expression recognition.