 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-In-One: Facial Expression Transfer, Editing and Recognition Using A Single Network
Paper and Code
Nov 16, 2019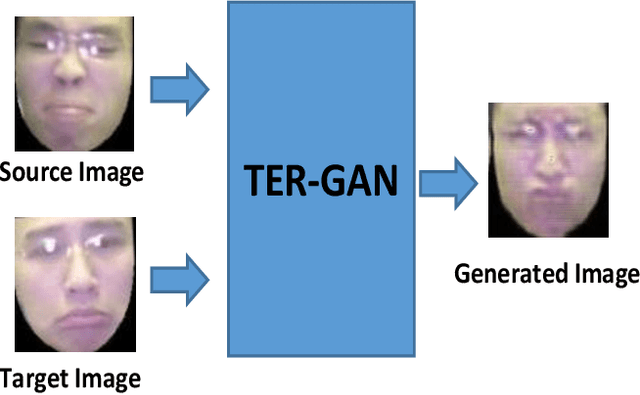
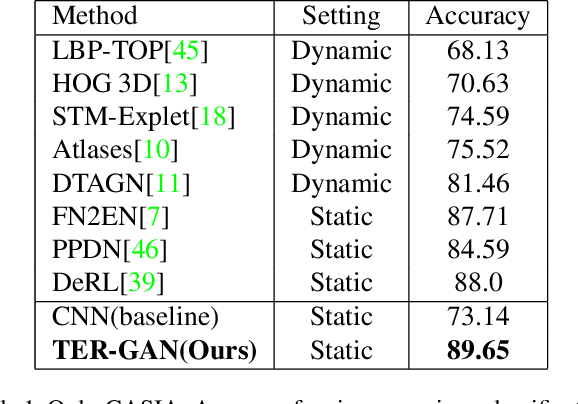
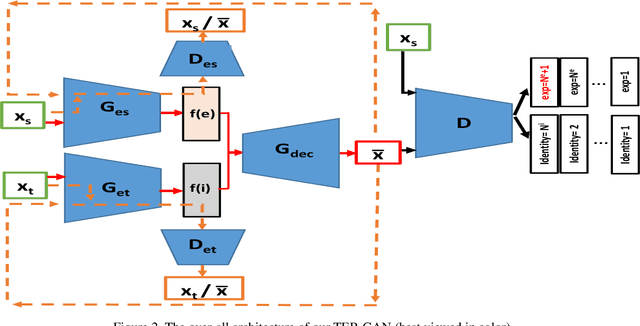

In this paper, we present a unified architecture known as Transfer-Editing and Recognition Generative Adversarial Network (TER-GAN) which can be used: 1. to transfer facial expressions from one identity to another identity, known as Facial Expression Transfer (FET), 2. to transform the expression of a given image to a target expression, while preserving the identity of the image, known as Facial Expression Editing (FEE), and 3. to recognize the facial expression of a face image, known as Facial Expression Recognition (FER). In TER-GAN, we combine the capabilities of generative models to generate synthetic images, while learning important information about the input images during the reconstruction process. More specifically, two encoders are used in TER-GAN to encode identity and expression information from two input images, and a synthetic expression image is generated by the decoder part of TER-GAN. To improve the feature disentanglement and extraction process, we also introduce a novel expression consistency loss and an identity consistency loss which exploit extra expression and identity information from generated images. Experimental results show that the proposed method can be used for efficient facial expression transfer, facial expression editing and facial expression recognition. In order to evaluate the proposed technique and to compare our results with state-of-the-art methods, we have used the Oulu-CASIA dataset for our experiments.