 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Transformer-based Network for multimodal Emotion Recognition
Aug 27, 2023
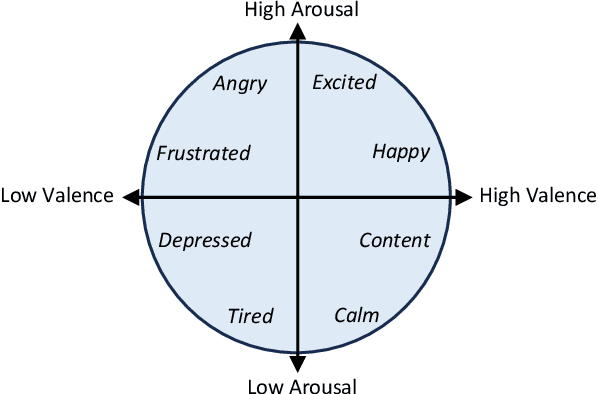

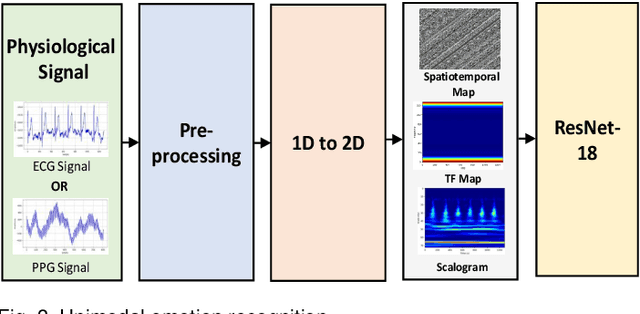
The development of transformer-based models has resulted in significant advances in addressing various vision and NLP-based research challenges. However, the progress made in transformer-based methods has not been effectively applied to biosensing research. This paper presents a novel Unified Biosensor-Vision Multi-modal Transformer-based (UBVMT) method to classify emotions in an arousal-valence space by combining a 2D representation of an ECG/PPG signal with the face information. To achieve this goal, we first investigate and compare the unimodal emotion recognition performance of three image-based representations of the ECG/PPG signal. We then present our UBVMT network which is trained to perform emotion recognition by combining the 2D image-based representation of the ECG/PPG signal and the facial expression features. Our unified transformer model consists of homogeneous transformer blocks that take as an input the 2D representation of the ECG/PPG signal and the corresponding face frame for emotion representation learning with minimal modality-specific design. Our UBVMT model is trained by reconstructing masked patches of video frames and 2D images of ECG/PPG signals, and contrastive modeling to align face and ECG/PPG data. Extensive experiments on the MAHNOB-HCI and DEAP datasets show that our Unified UBVMT-based model produces comparable results to the state-of-the-art techniques.
Semi-supervised Drifted Stream Learning with Short Lookback
May 25, 2022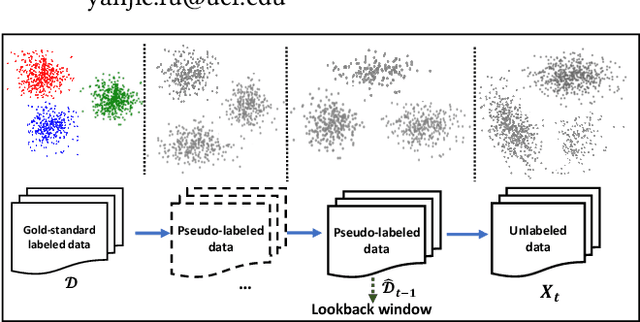
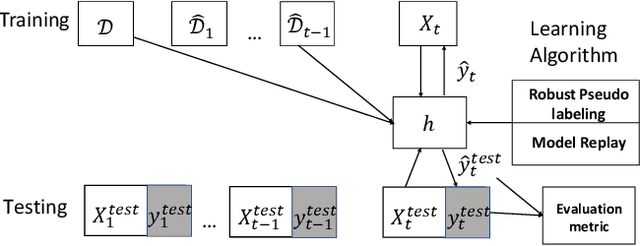
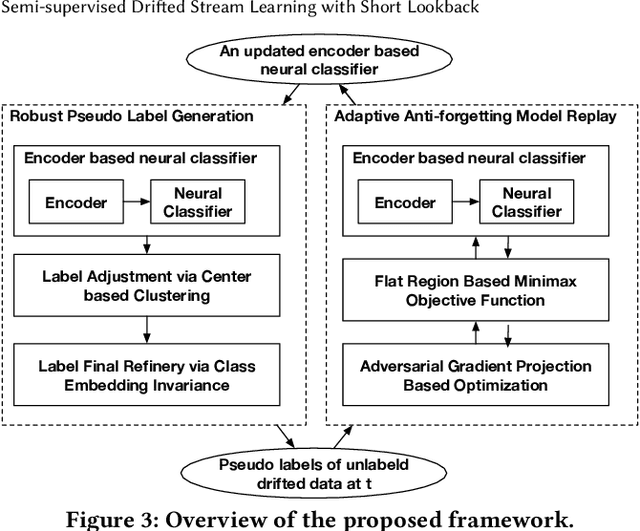
In many scenarios, 1) data streams are generated in real time; 2) labeled data are expensive and only limited labels are available in the beginning; 3) real-world data is not always i.i.d. and data drift over time gradually; 4) the storage of historical streams is limited and model updating can only be achieved based on a very short lookback window. This learning setting limits the applicability and availability of many Machine Learning (ML) algorithms. We generalize the learning task under such setting as a semi-supervised drifted stream learning with short lookback problem (SDSL). SDSL imposes two under-addressed challenges on existing methods in semi-supervised learning, continuous learning, and domain adaptation: 1) robust pseudo-labeling under gradual shifts and 2) anti-forgetting adaptation with short lookback. To tackle these challenges, we propose a principled and generic generation-replay framework to solve SDSL. The framework is able to accomplish: 1) robust pseudo-labeling in the generation step; 2) anti-forgetting adaption in the replay step. To achieve robust pseudo-labeling, we develop a novel pseudo-label classification model to leverage supervised knowledge of previously labeled data, unsupervised knowledge of new data, and, structure knowledge of invariant label semantics. To achieve adaptive anti-forgetting model replay, we propose to view the anti-forgetting adaptation task as a flat region search problem. We propose a novel minimax game-based replay objective function to solve the flat region search problem and develop an effective optimization solver. Finally, we present extensive experiments to demonstrate our framework can effectively address the task of anti-forgetting learning in drifted streams with short lookback.
Reinforced Imitative Graph Learning for Mobile User Profiling
Mar 13, 2022
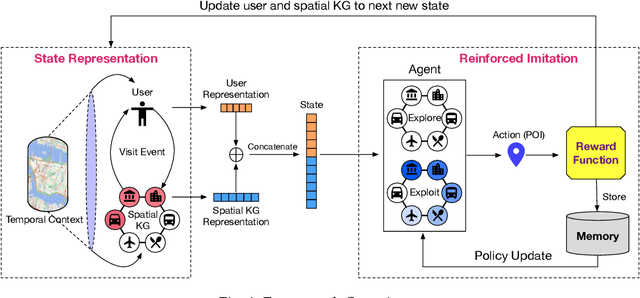
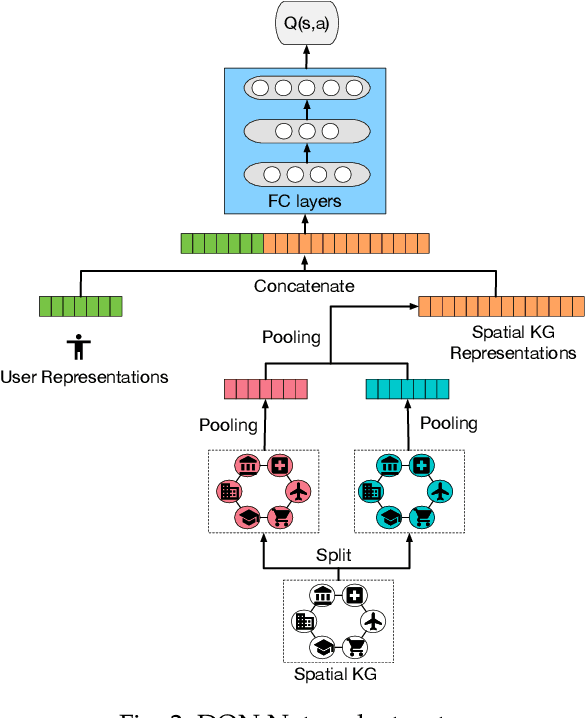

Mobile user profiling refers to the efforts of extracting users' characteristics from mobile activities. In order to capture the dynamic varying of user characteristics for generating effective user profiling, we propose an imitation-based mobile user profiling framework. Considering the objective of teaching an autonomous agent to imitate user mobility based on the user's profile, the user profile is the most accurate when the agent can perfectly mimic the user behavior patterns. The profiling framework is formulated into a reinforcement learning task, where an agent is a next-visit planner, an action is a POI that a user will visit next, and the state of the environment is a fused representation of a user and spatial entities. An event in which a user visits a POI will construct a new state, which helps the agent predict users' mobility more accurately. In the framework, we introduce a spatial Knowledge Graph (KG) to characterize the semantics of user visits over connected spatial entities. Additionally, we develop a mutual-updating strategy to quantify the state that evolves over time. Along these lines, we develop a reinforcement imitative graph learning framework for mobile user profiling. Finally, we conduct extensive experiments to demonstrate the superiority of our approach.
An Efficient Integration of Disentangled Attended Expression and Identity FeaturesFor Facial Expression Transfer andSynthesis
May 01, 2020
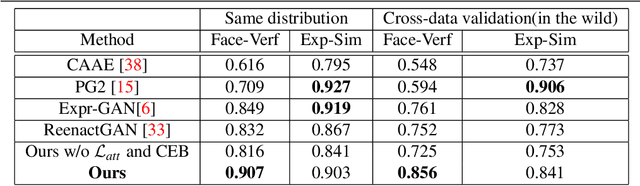

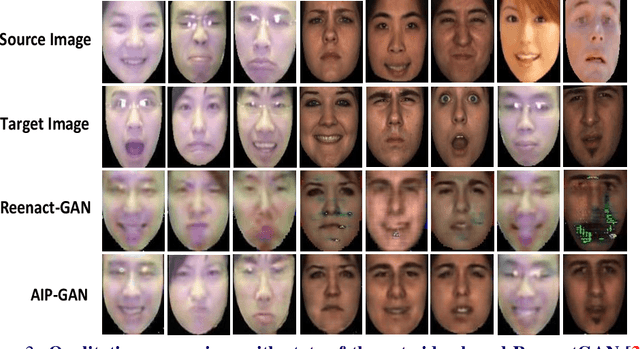
In this paper, we present an Attention-based Identity Preserving Generative Adversarial Network (AIP-GAN) to overcome the identity leakage problem from a source image to a generated face image, an issue that is encountered in a cross-subject facial expression transfer and synthesis process. Our key insight is that the identity preserving network should be able to disentangle and compose shape, appearance, and expression information for efficient facial expression transfer and synthesis. Specifically, the expression encoder of our AIP-GAN disentangles the expression information from the input source image by predicting its facial landmarks using our supervised spatial and channel-wise attention module. Similarly, the disentangled expression-agnostic identity features are extracted from the input target image by inferring its combined intrinsic-shape and appearance image employing our self-supervised spatial and channel-wise attention mod-ule. To leverage the expression and identity information encoded by the intermediate layers of both of our encoders, we combine these features with the features learned by the intermediate layers of our decoder using a cross-encoder bilinear pooling operation. Experimental results show the promising performance of our AIP-GAN based technique.
Facial Expression Representation Learning by Synthesizing Expression Images
Nov 30, 2019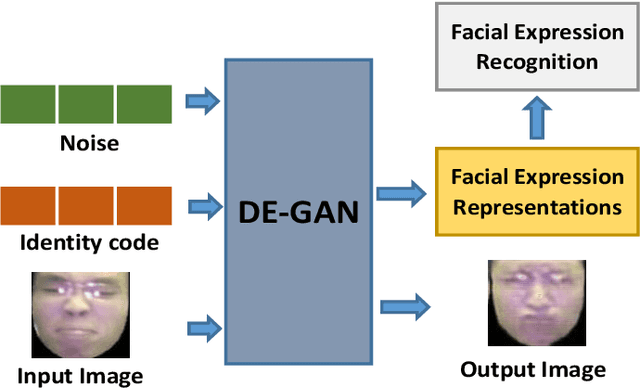
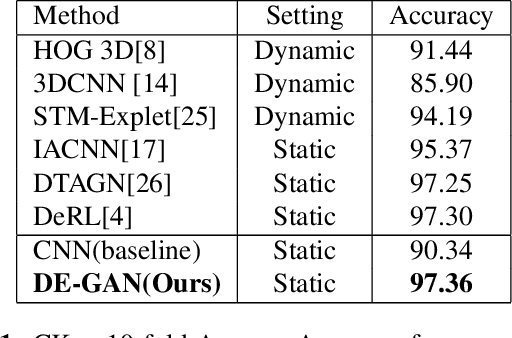
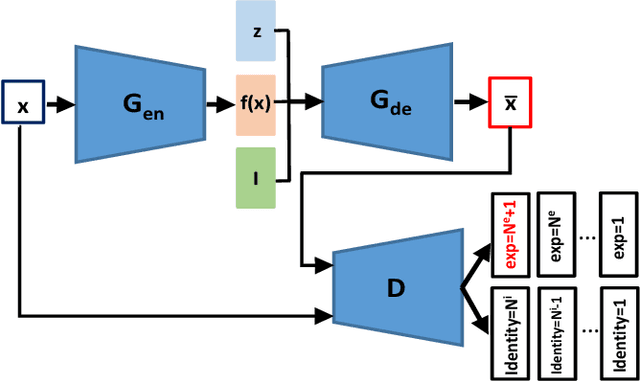
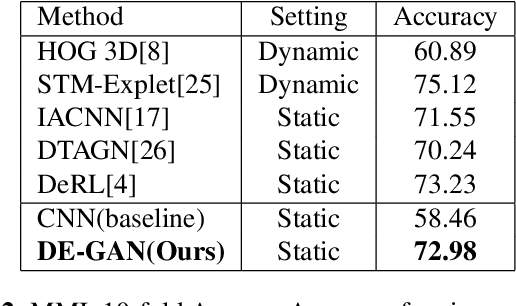
Representations used for Facial Expression Recognition (FER) usually contain expression information along with identity features. In this paper, we propose a novel Disentangled Expression learning-Generative Adversarial Network (DE-GAN) which combines the concept of disentangled representation learning with residue learning to explicitly disentangle facial expression representation from identity information. In this method the facial expression representation is learned by reconstructing an expression image employing an encoder-decoder based generator. Unlike previous works using only expression residual learning for facial expression recognition, our method learns the disentangled expression representation along with the expressive component recorded by the encoder of DE-GAN. In order to improve the quality of synthesized expression images and the effectiveness of the learned disentangled expression representation, expression and identity classification is performed by the discriminator of DE-GAN. Experiments performed on widely used datasets (CK+, MMI, Oulu-CASIA) show that the proposed technique produces comparable or better results than state-of-the-art methods.
All-In-One: Facial Expression Transfer, Editing and Recognition Using A Single Network
Nov 16, 2019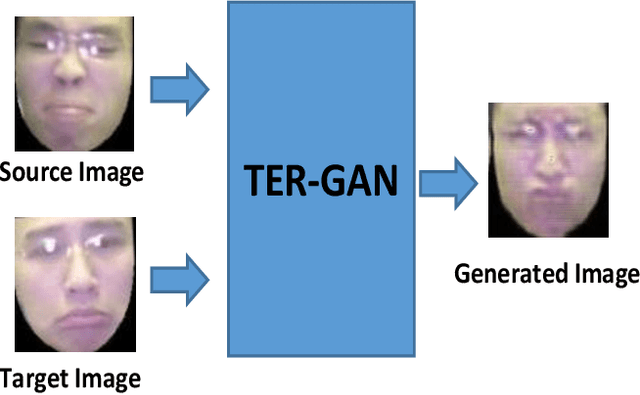
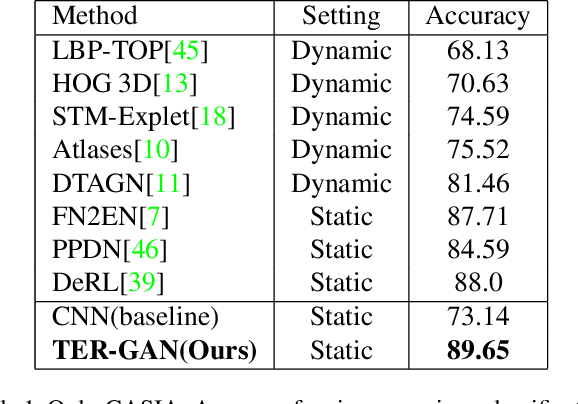
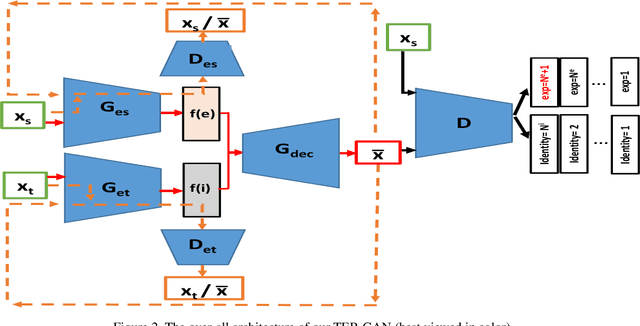

In this paper, we present a unified architecture known as Transfer-Editing and Recognition Generative Adversarial Network (TER-GAN) which can be used: 1. to transfer facial expressions from one identity to another identity, known as Facial Expression Transfer (FET), 2. to transform the expression of a given image to a target expression, while preserving the identity of the image, known as Facial Expression Editing (FEE), and 3. to recognize the facial expression of a face image, known as Facial Expression Recognition (FER). In TER-GAN, we combine the capabilities of generative models to generate synthetic images, while learning important information about the input images during the reconstruction process. More specifically, two encoders are used in TER-GAN to encode identity and expression information from two input images, and a synthetic expression image is generated by the decoder part of TER-GAN. To improve the feature disentanglement and extraction process, we also introduce a novel expression consistency loss and an identity consistency loss which exploit extra expression and identity information from generated images. Experimental results show that the proposed method can be used for efficient facial expression transfer, facial expression editing and facial expression recognition. In order to evaluate the proposed technique and to compare our results with state-of-the-art methods, we have used the Oulu-CASIA dataset for our experiments.
Facial Expression Recognition Using Disentangled Adversarial Learning
Sep 28, 2019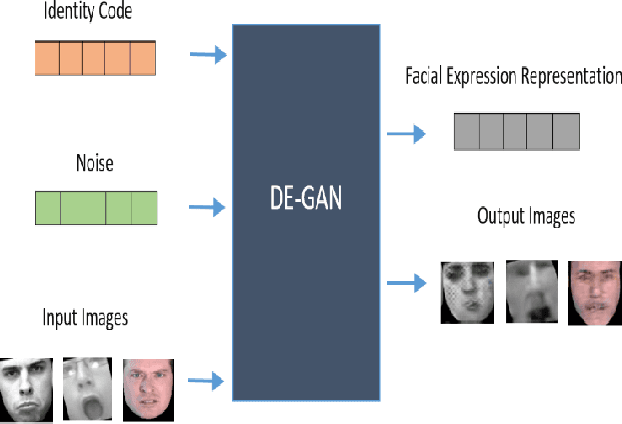
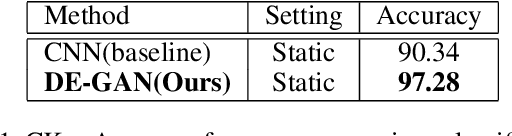
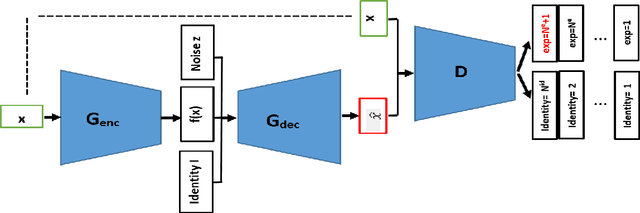
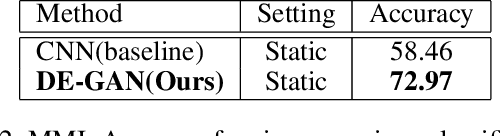
The representation used for Facial Expression Recognition (FER) usually contain expression information along with other variations such as identity and illumination. In this paper, we propose a novel Disentangled Expression learning-Generative Adversarial Network (DE-GAN) to explicitly disentangle facial expression representation from identity information. In this learning by reconstruction method, facial expression representation is learned by reconstructing an expression image employing an encoder-decoder based generator. This expression representation is disentangled from identity component by explicitly providing the identity code to the decoder part of DE-GAN. The process of expression image reconstruction and disentangled expression representation learning is improved by performing expression and identity classification in the discriminator of DE-GAN. The disentangled facial expression representation is then used for facial expression recognition employing simple classifiers like SVM or MLP. The experiments are performed on publicly available and widely used face expression databases (CK+, MMI, Oulu-CASIA). The experimental results show that the proposed technique produces comparable results with state-of-the-art methods.