 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPACE: Bisimulation-Guided Policy Optimization with Action Counterfactual Estimation for LLM Agents
Jun 24, 2026Stepwise group-based RL is an attractive way to train long-horizon LLM agents without a learned critic: it reuses multiple sampled rollouts to estimate local advantages. Its weakness is less visible but more fundamental: every group-relative estimator assumes that the steps it compares are equivalent for credit assignment. We show that current agentic variants violate this assumption through a state-action credit mismatch. The observation-hash partition is overly fine on the state side, creating singleton groups with zero step-level signal, while a single within-group mean is too coarse on the action side, mixing state-value estimation with action-specific credit. We introduce BiPACE (Bisimulation-Guided Policy Optimization with Action Counterfactual Estimation), a drop-in advantage estimator that fixes both sides without adding a critic, auxiliary loss, or extra rollouts. BiGPO clusters steps by cosine distance in the actor's own hidden-state geometry, an empirical policy-induced proxy for bisimulation that substantially lowers the singleton rate left by observation hashing. PACE then recenters returns within each behavioral cluster using action-conditioned peer baselines; its Q-style instance estimates a local Q(s,a)-V(s) nonparametrically. On ALFWorld/Qwen2.5-7B, BiPACE_Q raises overall validation success from GiGPO's 90.8 to $97.1\pm0.9$ over three seeds, and crosses the 95% threshold on every seed, which GiGPO never does within the same budget. On Qwen2.5-1.5B it reaches $93.5\pm1.2$ versus GiGPO's 86.7, and on WebShop and TextCraft it improves over GRPO and GiGPO at both model scales. The measured BiPACE-specific overhead is 11.3% of a single training-step wall time. Yet it changes the estimator's comparison unit from surface identity to approximate behavioral equivalence plus action-side counterfactuals. The code is available at https://github.com/TianxiangZhao/BiPACE.
Deep Learning within Tabular Data: Foundations, Challenges, Advances and Future Directions
Jan 07, 2025Tabular data remains one of the most prevalent data types across a wide range of real-world applications, yet effective representation learning for this domain poses unique challenges due to its irregular patterns, heterogeneous feature distributions, and complex inter-column dependencies. This survey provides a comprehensive review of state-of-the-art techniques in tabular data representation learning, structured around three foundational design elements: training data, neural architectures, and learning objectives. Unlike prior surveys that focus primarily on either architecture design or learning strategies, we adopt a holistic perspective that emphasizes the universality and robustness of representation learning methods across diverse downstream tasks. We examine recent advances in data augmentation and generation, specialized neural network architectures tailored to tabular data, and innovative learning objectives that enhance representation quality. Additionally, we highlight the growing influence of self-supervised learning and the adaptation of transformer-based foundation models for tabular data. Our review is based on a systematic literature search using rigorous inclusion criteria, encompassing 127 papers published since 2020 in top-tier conferences and journals. Through detailed analysis and comparison, we identify emerging trends, critical gaps, and promising directions for future research, aiming to guide the development of more generalizable and effective tabular data representation methods.
RATT: A Thought Structure for Coherent and Correct LLM Reasoning
Jun 09, 2024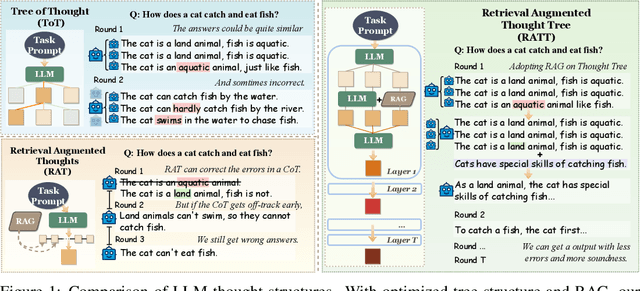



Large Language Models (LLMs) gain substantial reasoning and decision-making capabilities from thought structures. However, existing methods such as Tree of Thought and Retrieval Augmented Thoughts often fall short in complex tasks due to the limitations of insufficient local retrieval of factual knowledge and inadequate global selection of strategies. These limitations make it challenging for these methods to balance factual accuracy and comprehensive logical optimization effectively. To address these limitations, we introduce the Retrieval Augmented Thought Tree (RATT), a novel thought structure that considers both overall logical soundness and factual correctness at each step of the thinking process. Specifically, at every point of a thought branch, RATT performs planning and lookahead to explore and evaluate multiple potential reasoning steps, and integrate the fact-checking ability of Retrieval-Augmented Generation (RAG) with LLM's ability to assess overall strategy. Through this combination of factual knowledge and strategic feasibility, the RATT adjusts and integrates the thought tree structure to search for the most promising branches within the search space. This thought structure significantly enhances the model's coherence in logical inference and efficiency in decision-making, and thus increases the limit of the capacity of LLM to generate reliable inferences and decisions based on thought structures. A broad range of experiments on different types of tasks showcases that the RATT structure significantly outperforms existing methods in factual correctness and logical coherence.
RATT: AThought Structure for Coherent and Correct LLMReasoning
Jun 04, 2024Large Language Models (LLMs) gain substantial reasoning and decision-making capabilities from thought structures. However, existing methods such as Tree of Thought and Retrieval Augmented Thoughts often fall short in complex tasks due to the limitations of insufficient local retrieval of factual knowledge and inadequate global selection of strategies. These limitations make it challenging for these methods to balance factual accuracy and comprehensive logical optimization effectively. To address these limitations, we introduce the Retrieval Augmented Thought Tree (RATT), a novel thought structure that considers both overall logical soundness and factual correctness at each step of the thinking process. Specifically, at every point of a thought branch, RATT performs planning and lookahead to explore and evaluate multiple potential reasoning steps, and integrate the fact-checking ability of Retrieval-Augmented Generation (RAG) with LLM's ability to assess overall strategy. Through this combination of factual knowledge and strategic feasibility, the RATT adjusts and integrates the thought tree structure to search for the most promising branches within the search space. This thought structure significantly enhances the model's coherence in logical inference and efficiency in decision-making, and thus increases the limit of the capacity of LLM to generate reliable inferences and decisions based on thought structures. A broad range of experiments on different types of tasks showcases that the RATT structure significantly outperforms existing methods in factual correctness and logical coherence.
Gradient-Aware Logit Adjustment Loss for Long-tailed Classifier
Mar 14, 2024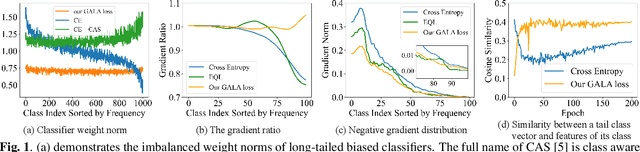

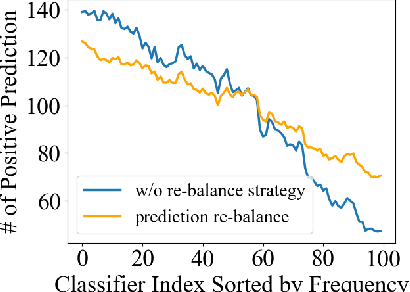

In the real-world setting, data often follows a long-tailed distribution, where head classes contain significantly more training samples than tail classes. Consequently, models trained on such data tend to be biased toward head classes. The medium of this bias is imbalanced gradients, which include not only the ratio of scale between positive and negative gradients but also imbalanced gradients from different negative classes. Therefore, we propose the Gradient-Aware Logit Adjustment (GALA) loss, which adjusts the logits based on accumulated gradients to balance the optimization process. Additionally, We find that most of the solutions to long-tailed problems are still biased towards head classes in the end, and we propose a simple and post hoc prediction re-balancing strategy to further mitigate the basis toward head class. Extensive experiments are conducted on multiple popular long-tailed recognition benchmark datasets to evaluate the effectiveness of these two designs. Our approach achieves top-1 accuracy of 48.5\%, 41.4\%, and 73.3\% on CIFAR100-LT, Places-LT, and iNaturalist, outperforming the state-of-the-art method GCL by a significant margin of 3.62\%, 0.76\% and 1.2\%, respectively. Code is available at https://github.com/lt-project-repository/lt-project.
Analyzing and Reducing Catastrophic Forgetting in Parameter Efficient Tuning
Feb 29, 2024Existing research has shown that large language models (LLMs) exhibit remarkable performance in language understanding and generation. However, when LLMs are continuously fine-tuned on complex and diverse domain-specific downstream tasks, the inference performance on historical tasks decreases dramatically, which is known as a catastrophic forgetting problem. A trade-off needs to be kept between learning plasticity and memory stability. Plenty of existing works have explored strategies like memory replay, regularization and parameter isolation, but little is known about the geometric connection of various adjacent minima in the continual LLMs fine-tuning scenarios. In this work, we investigate the geometric connections of different minima through the lens of mode connectivity, which means different minima can be connected by a low-loss valley. Through extensive experiments, we uncover the mode connectivity phenomenon in the LLMs continual learning scenario and find that it can strike a balance between plasticity and stability. Building upon these findings, we propose a simple yet effective method called Interpolation-based LoRA (I-LoRA), which constructs a dual-memory experience replay framework based on LoRA parameter interpolations. Extensive experiments and analysis on eight domain-specific CL benchmarks demonstrate that I-LoRA consistently show significant improvement over the previous state-of-the-art approaches with up to $11\%$ performance gains, providing a strong baseline and insights for future research on the large language model continual learning problem. Our code is available at \url{https://github.com/which47/LLMCL}.
EsaCL: Efficient Continual Learning of Sparse Models
Jan 11, 2024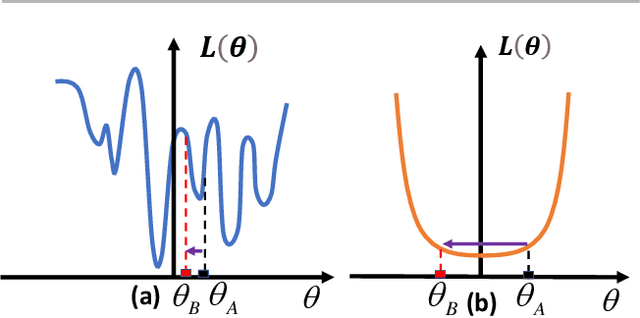
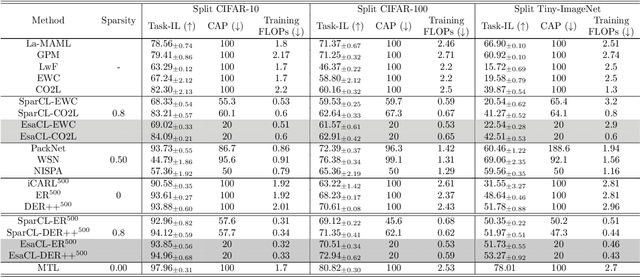

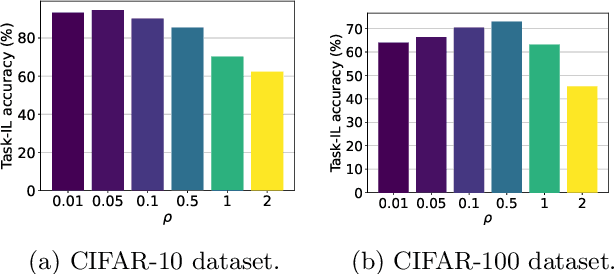
A key challenge in the continual learning setting is to efficiently learn a sequence of tasks without forgetting how to perform previously learned tasks. Many existing approaches to this problem work by either retraining the model on previous tasks or by expanding the model to accommodate new tasks. However, these approaches typically suffer from increased storage and computational requirements, a problem that is worsened in the case of sparse models due to need for expensive re-training after sparsification. To address this challenge, we propose a new method for efficient continual learning of sparse models (EsaCL) that can automatically prune redundant parameters without adversely impacting the model's predictive power, and circumvent the need of retraining. We conduct a theoretical analysis of loss landscapes with parameter pruning, and design a directional pruning (SDP) strategy that is informed by the sharpness of the loss function with respect to the model parameters. SDP ensures model with minimal loss of predictive accuracy, accelerating the learning of sparse models at each stage. To accelerate model update, we introduce an intelligent data selection (IDS) strategy that can identify critical instances for estimating loss landscape, yielding substantially improved data efficiency. The results of our experiments show that EsaCL achieves performance that is competitive with the state-of-the-art methods on three continual learning benchmarks, while using substantially reduced memory and computational resources.
T-SaS: Toward Shift-aware Dynamic Adaptation for Streaming Data
Sep 05, 2023



In many real-world scenarios, distribution shifts exist in the streaming data across time steps. Many complex sequential data can be effectively divided into distinct regimes that exhibit persistent dynamics. Discovering the shifted behaviors and the evolving patterns underlying the streaming data are important to understand the dynamic system. Existing methods typically train one robust model to work for the evolving data of distinct distributions or sequentially adapt the model utilizing explicitly given regime boundaries. However, there are two challenges: (1) shifts in data streams could happen drastically and abruptly without precursors. Boundaries of distribution shifts are usually unavailable, and (2) training a shared model for all domains could fail to capture varying patterns. This paper aims to solve the problem of sequential data modeling in the presence of sudden distribution shifts that occur without any precursors. Specifically, we design a Bayesian framework, dubbed as T-SaS, with a discrete distribution-modeling variable to capture abrupt shifts of data. Then, we design a model that enable adaptation with dynamic network selection conditioned on that discrete variable. The proposed method learns specific model parameters for each distribution by learning which neurons should be activated in the full network. A dynamic masking strategy is adopted here to support inter-distribution transfer through the overlapping of a set of sparse networks. Extensive experiments show that our proposed method is superior in both accurately detecting shift boundaries to get segments of varying distributions and effectively adapting to downstream forecast or classification tasks.
Graph Relation Aware Continual Learning
Aug 16, 2023



Continual graph learning (CGL) studies the problem of learning from an infinite stream of graph data, consolidating historical knowledge, and generalizing it to the future task. At once, only current graph data are available. Although some recent attempts have been made to handle this task, we still face two potential challenges: 1) most of existing works only manipulate on the intermediate graph embedding and ignore intrinsic properties of graphs. It is non-trivial to differentiate the transferred information across graphs. 2) recent attempts take a parameter-sharing policy to transfer knowledge across time steps or progressively expand new architecture given shifted graph distribution. Learning a single model could loss discriminative information for each graph task while the model expansion scheme suffers from high model complexity. In this paper, we point out that latent relations behind graph edges can be attributed as an invariant factor for the evolving graphs and the statistical information of latent relations evolves. Motivated by this, we design a relation-aware adaptive model, dubbed as RAM-CG, that consists of a relation-discovery modular to explore latent relations behind edges and a task-awareness masking classifier to accounts for the shifted. Extensive experiments show that RAM-CG provides significant 2.2%, 6.9% and 6.6% accuracy improvements over the state-of-the-art results on CitationNet, OGBN-arxiv and TWITCH dataset, respective.
Read, Diagnose and Chat: Towards Explainable and Interactive LLMs-Augmented Depression Detection in Social Media
May 09, 2023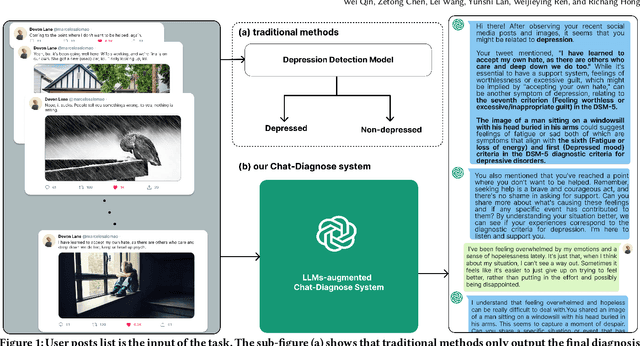
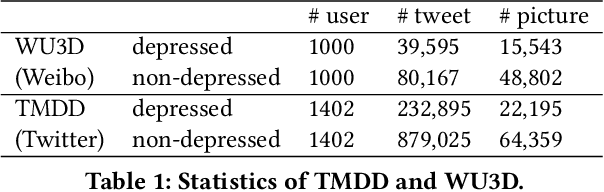
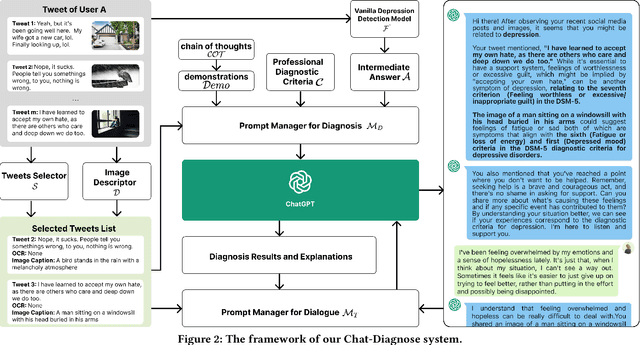
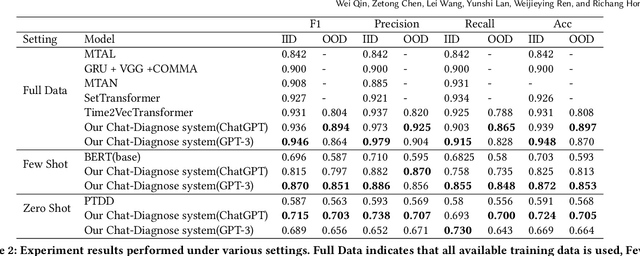
This paper proposes a new depression detection system based on LLMs that is both interpretable and interactive. It not only provides a diagnosis, but also diagnostic evidence and personalized recommendations based on natural language dialogue with the user. We address challenges such as the processing of large amounts of text and integrate professional diagnostic criteria. Our system outperforms traditional methods across various settings and is demonstrated through case studies.