 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Text Style Transfer for Controllable Intensity
Jan 03, 2026Unsupervised Text Style Transfer (UTST) aims to build a system to transfer the stylistic properties of a given text without parallel text pairs. Compared with text transfer between style polarities, UTST for controllable intensity is more challenging due to the subtle differences in stylistic features across different intensity levels. Faced with the challenges posed by the lack of parallel data and the indistinguishability between adjacent intensity levels, we propose a SFT-then-PPO paradigm to fine-tune an LLM. We first fine-tune the LLM with synthesized parallel data. Then, we further train the LLM with PPO, where the rewards are elaborately designed for distinguishing the stylistic intensity in hierarchical levels. Both the global and local stylistic features are considered to formulate the reward functions. The experiments on two UTST benchmarks showcase that both rewards have their advantages and applying them to LLM fine-tuning can effectively improve the performance of an LLM backbone based on various evaluation metrics. Even for close levels of intensity, we can still observe the noticeable stylistic difference between the generated text.
MCP-SafetyBench: A Benchmark for Safety Evaluation of Large Language Models with Real-World MCP Servers
Dec 17, 2025Large language models (LLMs) are evolving into agentic systems that reason, plan, and operate external tools. The Model Context Protocol (MCP) is a key enabler of this transition, offering a standardized interface for connecting LLMs with heterogeneous tools and services. Yet MCP's openness and multi-server workflows introduce new safety risks that existing benchmarks fail to capture, as they focus on isolated attacks or lack real-world coverage. We present MCP-SafetyBench, a comprehensive benchmark built on real MCP servers that supports realistic multi-turn evaluation across five domains: browser automation, financial analysis, location navigation, repository management, and web search. It incorporates a unified taxonomy of 20 MCP attack types spanning server, host, and user sides, and includes tasks requiring multi-step reasoning and cross-server coordination under uncertainty. Using MCP-SafetyBench, we systematically evaluate leading open- and closed-source LLMs, revealing large disparities in safety performance and escalating vulnerabilities as task horizons and server interactions grow. Our results highlight the urgent need for stronger defenses and establish MCP-SafetyBench as a foundation for diagnosing and mitigating safety risks in real-world MCP deployments.
RIDE: Difficulty Evolving Perturbation with Item Response Theory for Mathematical Reasoning
Nov 06, 2025Large language models (LLMs) achieve high performance on mathematical reasoning, but these results can be inflated by training data leakage or superficial pattern matching rather than genuine reasoning. To this end, an adversarial perturbation-based evaluation is needed to measure true mathematical reasoning ability. Current rule-based perturbation methods often generate ill-posed questions and impede the systematic evaluation of question difficulty and the evolution of benchmarks. To bridge this gap, we propose RIDE, a novel adversarial question-rewriting framework that leverages Item Response Theory (IRT) to rigorously measure question difficulty and to generate intrinsically more challenging, well-posed variations of mathematical problems. We employ 35 LLMs to simulate students and build a difficulty ranker from their responses. This ranker provides a reward signal during reinforcement learning and guides a question-rewriting model to reformulate existing questions across difficulty levels. Applying RIDE to competition-level mathematical benchmarks yields perturbed versions that degrade advanced LLM performance, with experiments showing an average 21.73% drop across 26 models, thereby exposing limited robustness in mathematical reasoning and confirming the validity of our evaluation approach.
MELLA: Bridging Linguistic Capability and Cultural Groundedness for Low-Resource Language MLLMs
Aug 07, 2025Multimodal Large Language Models (MLLMs) have shown remarkable performance in high-resource languages. However, their effectiveness diminishes significantly in the contexts of low-resource languages. Current multilingual enhancement methods are often limited to text modality or rely solely on machine translation. While such approaches help models acquire basic linguistic capabilities and produce "thin descriptions", they neglect the importance of multimodal informativeness and cultural groundedness, both of which are crucial for serving low-resource language users effectively. To bridge this gap, in this study, we identify two significant objectives for a truly effective MLLM in low-resource language settings, namely 1) linguistic capability and 2) cultural groundedness, placing special emphasis on cultural awareness. To achieve these dual objectives, we propose a dual-source strategy that guides the collection of data tailored to each goal, sourcing native web alt-text for culture and MLLM-generated captions for linguistics. As a concrete implementation, we introduce MELLA, a multimodal, multilingual dataset. Experiment results show that after fine-tuning on MELLA, there is a general performance improvement for the eight languages on various MLLM backbones, with models producing "thick descriptions". We verify that the performance gains are from both cultural knowledge enhancement and linguistic capability enhancement. Our dataset can be found at https://opendatalab.com/applyMultilingualCorpus.
SEAGraph: Unveiling the Whole Story of Paper Review Comments
Dec 16, 2024



Peer review, as a cornerstone of scientific research, ensures the integrity and quality of scholarly work by providing authors with objective feedback for refinement. However, in the traditional peer review process, authors often receive vague or insufficiently detailed feedback, which provides limited assistance and leads to a more time-consuming review cycle. If authors can identify some specific weaknesses in their paper, they can not only address the reviewer's concerns but also improve their work. This raises the critical question of how to enhance authors' comprehension of review comments. In this paper, we present SEAGraph, a novel framework developed to clarify review comments by uncovering the underlying intentions behind them. We construct two types of graphs for each paper: the semantic mind graph, which captures the author's thought process, and the hierarchical background graph, which delineates the research domains related to the paper. A retrieval method is then designed to extract relevant content from both graphs, facilitating coherent explanations for the review comments. Extensive experiments show that SEAGraph excels in review comment understanding tasks, offering significant benefits to authors.
NAT-NL2GQL: A Novel Multi-Agent Framework for Translating Natural Language to Graph Query Language
Dec 11, 2024



The emergence of Large Language Models (LLMs) has revolutionized many fields, not only traditional natural language processing (NLP) tasks. Recently, research on applying LLMs to the database field has been booming, and as a typical non-relational database, the use of LLMs in graph database research has naturally gained significant attention. Recent efforts have increasingly focused on leveraging LLMs to translate natural language into graph query language (NL2GQL). Although some progress has been made, these methods have clear limitations, such as their reliance on streamlined processes that often overlook the potential of LLMs to autonomously plan and collaborate with other LLMs in tackling complex NL2GQL challenges. To address this gap, we propose NAT-NL2GQL, a novel multi-agent framework for translating natural language to graph query language. Specifically, our framework consists of three synergistic agents: the Preprocessor agent, the Generator agent, and the Refiner agent. The Preprocessor agent manages data processing as context, including tasks such as name entity recognition, query rewriting, path linking, and the extraction of query-related schemas. The Generator agent is a fine-tuned LLM trained on NL-GQL data, responsible for generating corresponding GQL statements based on queries and their related schemas. The Refiner agent is tasked with refining the GQL or context using error information obtained from the GQL execution results. Given the scarcity of high-quality open-source NL2GQL datasets based on nGQL syntax, we developed StockGQL, a dataset constructed from a financial market graph database. It is available at: https://github.com/leonyuancode/StockGQL. Experimental results on the StockGQL and SpCQL datasets reveal that our method significantly outperforms baseline approaches, highlighting its potential for advancing NL2GQL research.
Unleashing the Power of Large Language Models in Zero-shot Relation Extraction via Self-Prompting
Oct 02, 2024



Recent research in zero-shot Relation Extraction (RE) has focused on using Large Language Models (LLMs) due to their impressive zero-shot capabilities. However, current methods often perform suboptimally, mainly due to a lack of detailed, context-specific prompts needed for understanding various sentences and relations. To address this, we introduce the Self-Prompting framework, a novel method designed to fully harness the embedded RE knowledge within LLMs. Specifically, our framework employs a three-stage diversity approach to prompt LLMs, generating multiple synthetic samples that encapsulate specific relations from scratch. These generated samples act as in-context learning samples, offering explicit and context-specific guidance to efficiently prompt LLMs for RE. Experimental evaluations on benchmark datasets show our approach outperforms existing LLM-based zero-shot RE methods. Additionally, our experiments confirm the effectiveness of our generation pipeline in producing high-quality synthetic data that enhances performance.
DFDG: Data-Free Dual-Generator Adversarial Distillation for One-Shot Federated Learning
Sep 12, 2024



Federated Learning (FL) is a distributed machine learning scheme in which clients jointly participate in the collaborative training of a global model by sharing model information rather than their private datasets. In light of concerns associated with communication and privacy, one-shot FL with a single communication round has emerged as a de facto promising solution. However, existing one-shot FL methods either require public datasets, focus on model homogeneous settings, or distill limited knowledge from local models, making it difficult or even impractical to train a robust global model. To address these limitations, we propose a new data-free dual-generator adversarial distillation method (namely DFDG) for one-shot FL, which can explore a broader local models' training space via training dual generators. DFDG is executed in an adversarial manner and comprises two parts: dual-generator training and dual-model distillation. In dual-generator training, we delve into each generator concerning fidelity, transferability and diversity to ensure its utility, and additionally tailor the cross-divergence loss to lessen the overlap of dual generators' output spaces. In dual-model distillation, the trained dual generators work together to provide the training data for updates of the global model. At last, our extensive experiments on various image classification tasks show that DFDG achieves significant performance gains in accuracy compared to SOTA baselines.
Aligning Large Language Models to a Domain-specific Graph Database
Feb 28, 2024

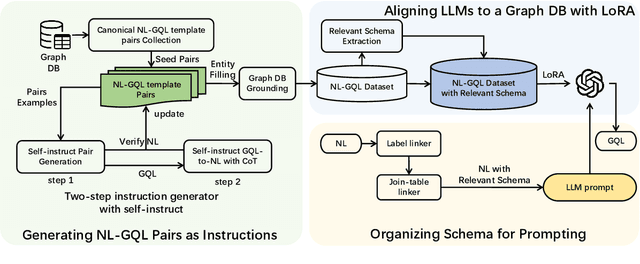

Graph Databases (Graph DB) are widely applied in various fields, including finance, social networks, and medicine. However, translating Natural Language (NL) into the Graph Query Language (GQL), commonly known as NL2GQL, proves to be challenging due to its inherent complexity and specialized nature. Some approaches have sought to utilize Large Language Models (LLMs) to address analogous tasks like text2SQL. Nevertheless, when it comes to NL2GQL taskson a particular domain, the absence of domain-specific NL-GQL data pairs makes it difficult to establish alignment between LLMs and the graph DB. To address this challenge, we propose a well-defined pipeline. Specifically, we utilize ChatGPT to create NL-GQL data pairs based on the given graph DB with self-instruct. Then, we use the created data to fine-tune LLMs, thereby achieving alignment between LLMs and the graph DB. Additionally, during inference, we propose a method that extracts relevant schema to the queried NL as the input context to guide LLMs for generating accurate GQLs.We evaluate our method on two constructed datasets deriving from graph DBs in finance domain and medicine domain, namely FinGQL and MediGQL. Experimental results demonstrate that our method significantly outperforms a set of baseline methods, with improvements of 5.90 and 6.36 absolute points on EM, and 6.00 and 7.09 absolute points on EX, respectively.
An LLM-Enhanced Adversarial Editing System for Lexical Simplification
Feb 23, 2024Lexical Simplification (LS) aims to simplify text at the lexical level. Existing methods rely heavily on annotated data, making it challenging to apply in low-resource scenarios. In this paper, we propose a novel LS method without parallel corpora. This method employs an Adversarial Editing System with guidance from a confusion loss and an invariance loss to predict lexical edits in the original sentences. Meanwhile, we introduce an innovative LLM-enhanced loss to enable the distillation of knowledge from Large Language Models (LLMs) into a small-size LS system. From that, complex words within sentences are masked and a Difficulty-aware Filling module is crafted to replace masked positions with simpler words. At last, extensive experimental results and analyses on three benchmark LS datasets demonstrate the effectiveness of our proposed method.