 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
Feb 05, 2026The rapid advancement of Large Language Models (LLMs) has catalyzed the development of autonomous agents capable of navigating complex environments. However, existing evaluations primarily adopt a deductive paradigm, where agents execute tasks based on explicitly provided rules and static goals, often within limited planning horizons. Crucially, this neglects the inductive necessity for agents to discover latent transition laws from experience autonomously, which is the cornerstone for enabling agentic foresight and sustaining strategic coherence. To bridge this gap, we introduce OdysseyArena, which re-centers agent evaluation on long-horizon, active, and inductive interactions. We formalize and instantiate four primitives, translating abstract transition dynamics into concrete interactive environments. Building upon this, we establish OdysseyArena-Lite for standardized benchmarking, providing a set of 120 tasks to measure an agent's inductive efficiency and long-horizon discovery. Pushing further, we introduce OdysseyArena-Challenge to stress-test agent stability across extreme interaction horizons (e.g., > 200 steps). Extensive experiments on 15+ leading LLMs reveal that even frontier models exhibit a deficiency in inductive scenarios, identifying a critical bottleneck in the pursuit of autonomous discovery in complex environments. Our code and data are available at https://github.com/xufangzhi/Odyssey-Arena
TIDE: Trajectory-based Diagnostic Evaluation of Test-Time Improvement in LLM Agents
Feb 03, 2026Recent advances in autonomous LLM agents demonstrate their ability to improve performance through iterative interaction with the environment. We define this paradigm as Test-Time Improvement (TTI). However, the mechanisms under how and why TTI succeed or fail remain poorly understood, and existing evaluation metrics fail to capture their task optimization efficiency, behavior adaptation after erroneous actions, and the specific utility of working memory for task completion. To address these gaps, we propose Test-time Improvement Diagnostic Evaluation (TIDE), an agent-agnostic and environment-agnostic framework that decomposes TTI into three comprehensive and interconnected dimensions. The framework measures (1) the overall temporal dynamics of task completion and (2) identifies whether performance is primarily constrained by recursive looping behaviors or (3) by burdensome accumulated memory. Through extensive experiments across diverse agents and environments, TIDE highlights that improving agent performance requires more than scaling internal reasoning, calling for explicitly optimizing the interaction dynamics between the agent and the environment.
OS-Symphony: A Holistic Framework for Robust and Generalist Computer-Using Agent
Jan 12, 2026While Vision-Language Models (VLMs) have significantly advanced Computer-Using Agents (CUAs), current frameworks struggle with robustness in long-horizon workflows and generalization in novel domains. These limitations stem from a lack of granular control over historical visual context curation and the absence of visual-aware tutorial retrieval. To bridge these gaps, we introduce OS-Symphony, a holistic framework that comprises an Orchestrator coordinating two key innovations for robust automation: (1) a Reflection-Memory Agent that utilizes milestone-driven long-term memory to enable trajectory-level self-correction, effectively mitigating visual context loss in long-horizon tasks; (2) Versatile Tool Agents featuring a Multimodal Searcher that adopts a SeeAct paradigm to navigate a browser-based sandbox to synthesize live, visually aligned tutorials, thereby resolving fidelity issues in unseen scenarios. Experimental results demonstrate that OS-Symphony delivers substantial performance gains across varying model scales, establishing new state-of-the-art results on three online benchmarks, notably achieving 65.84% on OSWorld.
GRACE: Reinforcement Learning for Grounded Response and Abstention under Contextual Evidence
Jan 08, 2026Retrieval-Augmented Generation (RAG) integrates external knowledge to enhance Large Language Models (LLMs), yet systems remain susceptible to two critical flaws: providing correct answers without explicit grounded evidence and producing fabricated responses when the retrieved context is insufficient. While prior research has addressed these issues independently, a unified framework that integrates evidence-based grounding and reliable abstention is currently lacking. In this paper, we propose GRACE, a reinforcement-learning framework that simultaneously mitigates both types of flaws. GRACE employs a data construction method that utilizes heterogeneous retrievers to generate diverse training samples without manual annotation. A multi-stage gated reward function is then employed to train the model to assess evidence sufficiency, extract key supporting evidence, and provide answers or explicitly abstain. Experimental results on two benchmarks demonstrate that GRACE achieves state-of-the-art overall accuracy and strikes a favorable balance between accurate response and rejection, while requiring only 10% of the annotation costs of prior methods. Our code is available at https://github.com/YiboZhao624/Grace..
OS-Oracle: A Comprehensive Framework for Cross-Platform GUI Critic Models
Dec 18, 2025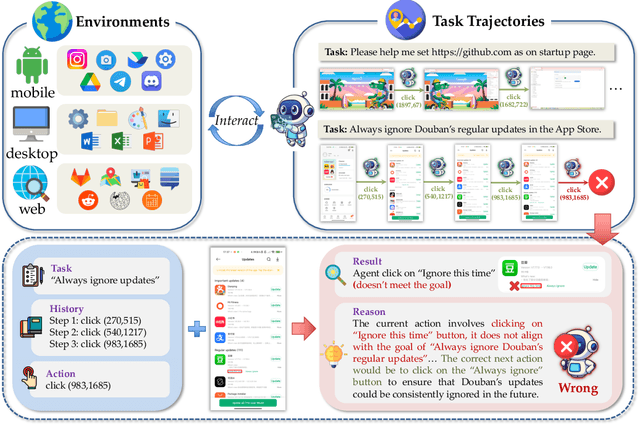
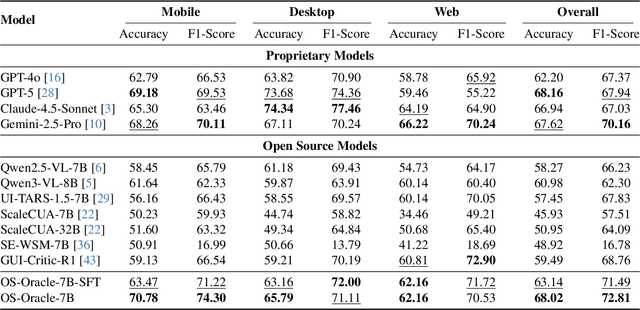
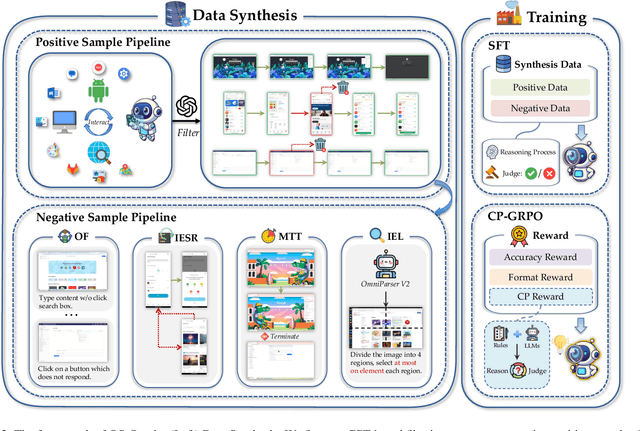
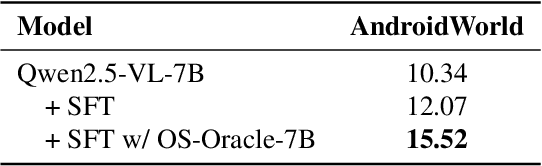
With VLM-powered computer-using agents (CUAs) becoming increasingly capable at graphical user interface (GUI) navigation and manipulation, reliable step-level decision-making has emerged as a key bottleneck for real-world deployment. In long-horizon workflows, errors accumulate quickly and irreversible actions can cause unintended consequences, motivating critic models that assess each action before execution. While critic models offer a promising solution, their effectiveness is hindered by the lack of diverse, high-quality GUI feedback data and public critic benchmarks for step-level evaluation in computer use. To bridge these gaps, we introduce OS-Oracle that makes three core contributions: (1) a scalable data pipeline for synthesizing cross-platform GUI critic data; (2) a two-stage training paradigm combining supervised fine-tuning (SFT) and consistency-preserving group relative policy optimization (CP-GRPO); (3) OS-Critic Bench, a holistic benchmark for evaluating critic model performance across Mobile, Web, and Desktop platforms. Leveraging this framework, we curate a high-quality dataset containing 310k critic samples. The resulting critic model, OS-Oracle-7B, achieves state-of-the-art performance among open-source VLMs on OS-Critic Bench, and surpasses proprietary models on the mobile domain. Furthermore, when serving as a pre-critic, OS-Oracle-7B improves the performance of native GUI agents such as UI-TARS-1.5-7B in OSWorld and AndroidWorld environments. The code is open-sourced at https://github.com/numbmelon/OS-Oracle.
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Sep 18, 2025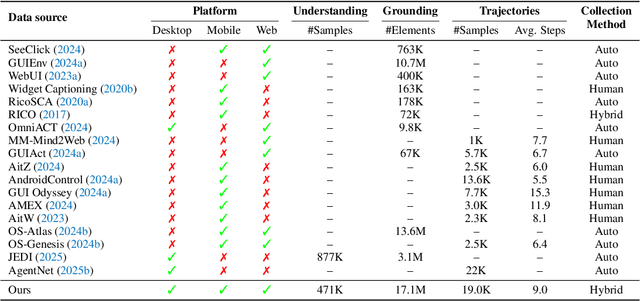
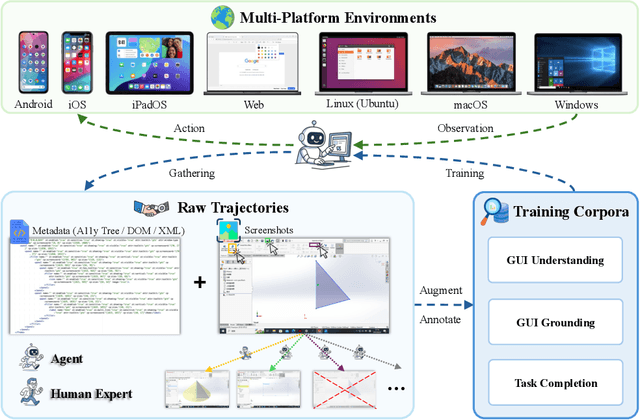
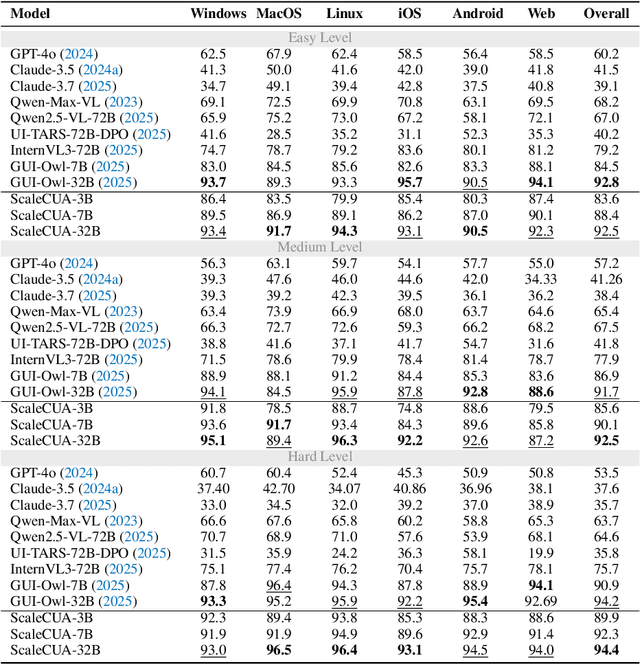
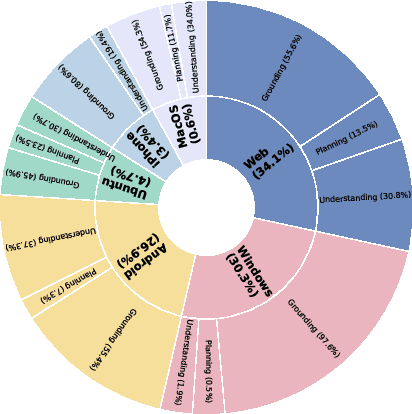
Vision-Language Models (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
May 26, 2025



Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.
Breaking the Data Barrier -- Building GUI Agents Through Task Generalization
Apr 15, 2025Graphical User Interface (GUI) agents offer cross-platform solutions for automating complex digital tasks, with significant potential to transform productivity workflows. However, their performance is often constrained by the scarcity of high-quality trajectory data. To address this limitation, we propose training Vision Language Models (VLMs) on data-rich, reasoning-intensive tasks during a dedicated mid-training stage, and then examine how incorporating these tasks facilitates generalization to GUI planning scenarios. Specifically, we explore a range of tasks with readily available instruction-tuning data, including GUI perception, multimodal reasoning, and textual reasoning. Through extensive experiments across 11 mid-training tasks, we demonstrate that: (1) Task generalization proves highly effective, yielding substantial improvements across most settings. For instance, multimodal mathematical reasoning enhances performance on AndroidWorld by an absolute 6.3%. Remarkably, text-only mathematical data significantly boosts GUI web agent performance, achieving a 5.6% improvement on WebArena and 5.4% improvement on AndroidWorld, underscoring notable cross-modal generalization from text-based to visual domains; (2) Contrary to prior assumptions, GUI perception data - previously considered closely aligned with GUI agent tasks and widely utilized for training - has a comparatively limited impact on final performance; (3) Building on these insights, we identify the most effective mid-training tasks and curate optimized mixture datasets, resulting in absolute performance gains of 8.0% on WebArena and 12.2% on AndroidWorld. Our work provides valuable insights into cross-domain knowledge transfer for GUI agents and offers a practical approach to addressing data scarcity challenges in this emerging field. The code, data and models will be available at https://github.com/hkust-nlp/GUIMid.
OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Dec 27, 2024



Graphical User Interface (GUI) agents powered by Vision-Language Models (VLMs) have demonstrated human-like computer control capability. Despite their utility in advancing digital automation, a critical bottleneck persists: collecting high-quality trajectory data for training. Common practices for collecting such data rely on human supervision or synthetic data generation through executing pre-defined tasks, which are either resource-intensive or unable to guarantee data quality. Moreover, these methods suffer from limited data diversity and significant gaps between synthetic data and real-world environments. To address these challenges, we propose OS-Genesis, a novel GUI data synthesis pipeline that reverses the conventional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis enables agents first to perceive environments and perform step-wise interactions, then retrospectively derive high-quality tasks to enable trajectory-level exploration. A trajectory reward model is then employed to ensure the quality of the generated trajectories. We demonstrate that training GUI agents with OS-Genesis significantly improves their performance on highly challenging online benchmarks. In-depth analysis further validates OS-Genesis's efficiency and its superior data quality and diversity compared to existing synthesis methods. Our codes, data, and checkpoints are available at \href{https://qiushisun.github.io/OS-Genesis-Home/}{OS-Genesis Homepage}.