 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Data Barrier -- Building GUI Agents Through Task Generalization
Apr 15, 2025Graphical User Interface (GUI) agents offer cross-platform solutions for automating complex digital tasks, with significant potential to transform productivity workflows. However, their performance is often constrained by the scarcity of high-quality trajectory data. To address this limitation, we propose training Vision Language Models (VLMs) on data-rich, reasoning-intensive tasks during a dedicated mid-training stage, and then examine how incorporating these tasks facilitates generalization to GUI planning scenarios. Specifically, we explore a range of tasks with readily available instruction-tuning data, including GUI perception, multimodal reasoning, and textual reasoning. Through extensive experiments across 11 mid-training tasks, we demonstrate that: (1) Task generalization proves highly effective, yielding substantial improvements across most settings. For instance, multimodal mathematical reasoning enhances performance on AndroidWorld by an absolute 6.3%. Remarkably, text-only mathematical data significantly boosts GUI web agent performance, achieving a 5.6% improvement on WebArena and 5.4% improvement on AndroidWorld, underscoring notable cross-modal generalization from text-based to visual domains; (2) Contrary to prior assumptions, GUI perception data - previously considered closely aligned with GUI agent tasks and widely utilized for training - has a comparatively limited impact on final performance; (3) Building on these insights, we identify the most effective mid-training tasks and curate optimized mixture datasets, resulting in absolute performance gains of 8.0% on WebArena and 12.2% on AndroidWorld. Our work provides valuable insights into cross-domain knowledge transfer for GUI agents and offers a practical approach to addressing data scarcity challenges in this emerging field. The code, data and models will be available at https://github.com/hkust-nlp/GUIMid.
Non-myopic Generation of Language Models for Reasoning and Planning
Oct 28, 2024



Large Language Models have demonstrated remarkable abilities in reasoning and planning by breaking down complex problems into sequential steps. Despite their success in various domains like mathematical problem-solving and coding, LLMs face challenges in ensuring reliable and optimal planning due to their inherent myopic nature of autoregressive decoding. This paper revisits LLM reasoning from an optimal-control perspective, proposing a novel method, Predictive-Decoding, that leverages Model Predictive Control to enhance planning accuracy. By re-weighting LLM distributions based on foresight trajectories, Predictive-Decoding aims to mitigate early errors and promote non-myopic planning. Our experiments show significant improvements in a wide range of tasks for math, coding, and agents. Furthermore, Predictive-Decoding demonstrates computational efficiency, outperforming search baselines with reduced computational resources. This study provides insights into optimizing LLM planning capabilities.
Non-myopic Generation of Language Model for Reasoning and Planning
Oct 23, 2024Large Language Models have demonstrated remarkable abilities in reasoning and planning by breaking down complex problems into sequential steps. Despite their success in various domains like mathematical problem-solving and coding, LLMs face challenges in ensuring reliable and optimal planning due to their inherent myopic nature of autoregressive decoding. This paper revisits LLM reasoning from an optimal-control perspective, proposing a novel method, Predictive-Decoding, that leverages Model Predictive Control to enhance planning accuracy. By re-weighting LLM distributions based on foresight trajectories, Predictive-Decoding aims to mitigate early errors and promote non-myopic planning. Our experiments show significant improvements in a wide range of tasks for math, coding, and agents. Furthermore, Predictive-Decoding demonstrates computational efficiency, outperforming search baselines with reduced computational resources. This study provides insights into optimizing LLM planning capabilities.
AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents
Jan 24, 2024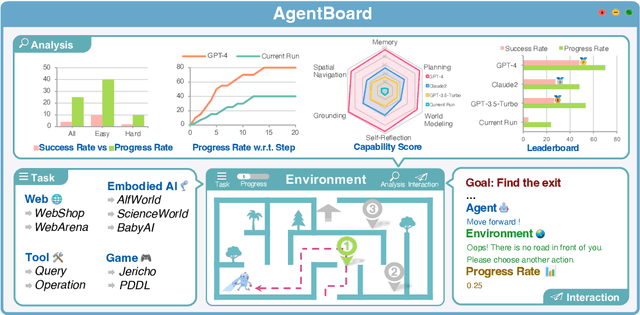

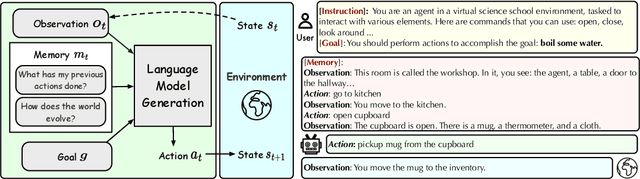

Evaluating large language models (LLMs) as general-purpose agents is essential for understanding their capabilities and facilitating their integration into practical applications. However, the evaluation process presents substantial challenges. A primary obstacle is the benchmarking of agent performance across diverse scenarios within a unified framework, especially in maintaining partially-observable environments and ensuring multi-round interactions. Moreover, current evaluation frameworks mostly focus on the final success rate, revealing few insights during the process and failing to provide a deep understanding of the model abilities. To address these challenges, we introduce AgentBoard, a pioneering comprehensive benchmark and accompanied open-source evaluation framework tailored to analytical evaluation of LLM agents. AgentBoard offers a fine-grained progress rate metric that captures incremental advancements as well as a comprehensive evaluation toolkit that features easy assessment of agents for multi-faceted analysis through interactive visualization. This not only sheds light on the capabilities and limitations of LLM agents but also propels the interpretability of their performance to the forefront. Ultimately, AgentBoard serves as a significant step towards demystifying agent behaviors and accelerating the development of stronger LLM agents.
PsyBench: a balanced and in-depth Psychological Chinese Evaluation Benchmark for Foundation Models
Nov 17, 2023As Large Language Models (LLMs) are becoming prevalent in various fields, there is an urgent need for improved NLP benchmarks that encompass all the necessary knowledge of individual discipline. Many contemporary benchmarks for foundational models emphasize a broad range of subjects but often fall short in presenting all the critical subjects and encompassing necessary professional knowledge of them. This shortfall has led to skewed results, given that LLMs exhibit varying performance across different subjects and knowledge areas. To address this issue, we present psybench, the first comprehensive Chinese evaluation suite that covers all the necessary knowledge required for graduate entrance exams. psybench offers a deep evaluation of a model's strengths and weaknesses in psychology through multiple-choice questions. Our findings show significant differences in performance across different sections of a subject, highlighting the risk of skewed results when the knowledge in test sets is not balanced. Notably, only the ChatGPT model reaches an average accuracy above $70\%$, indicating that there is still plenty of room for improvement. We expect that psybench will help to conduct thorough evaluations of base models' strengths and weaknesses and assist in practical application in the field of psychology.
Contrastive Learning of Sentence Embeddings from Scratch
May 24, 2023Contrastive learning has been the dominant approach to train state-of-the-art sentence embeddings. Previous studies have typically learned sentence embeddings either through the use of human-annotated natural language inference (NLI) data or via large-scale unlabeled sentences in an unsupervised manner. However, even in the case of unlabeled data, their acquisition presents challenges in certain domains due to various reasons. To address these issues, we present SynCSE, a contrastive learning framework that trains sentence embeddings with synthesized data. Specifically, we explore utilizing large language models to synthesize the required data samples for contrastive learning, including (1) producing positive and negative annotations given unlabeled sentences (SynCSE-partial), and (2) generating sentences along with their corresponding annotations from scratch (SynCSE-scratch). Experimental results on sentence similarity and reranking tasks indicate that both SynCSE-partial and SynCSE-scratch greatly outperform unsupervised baselines, and SynCSE-partial even achieves comparable performance to the supervised models in most settings.
Instance Smoothed Contrastive Learning for Unsupervised Sentence Embedding
May 18, 2023Contrastive learning-based methods, such as unsup-SimCSE, have achieved state-of-the-art (SOTA) performances in learning unsupervised sentence embeddings. However, in previous studies, each embedding used for contrastive learning only derived from one sentence instance, and we call these embeddings instance-level embeddings. In other words, each embedding is regarded as a unique class of its own, whichmay hurt the generalization performance. In this study, we propose IS-CSE (instance smoothing contrastive sentence embedding) to smooth the boundaries of embeddings in the feature space. Specifically, we retrieve embeddings from a dynamic memory buffer according to the semantic similarity to get a positive embedding group. Then embeddings in the group are aggregated by a self-attention operation to produce a smoothed instance embedding for further analysis. We evaluate our method on standard semantic text similarity (STS) tasks and achieve an average of 78.30%, 79.47%, 77.73%, and 79.42% Spearman's correlation on the base of BERT-base, BERT-large, RoBERTa-base, and RoBERTa-large respectively, a 2.05%, 1.06%, 1.16% and 0.52% improvement compared to unsup-SimCSE.
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
May 17, 2023



New NLP benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present C-Eval, the first comprehensive Chinese evaluation suite designed to assess advanced knowledge and reasoning abilities of foundation models in a Chinese context. C-Eval comprises multiple-choice questions across four difficulty levels: middle school, high school, college, and professional. The questions span 52 diverse disciplines, ranging from humanities to science and engineering. C-Eval is accompanied by C-Eval Hard, a subset of very challenging subjects in C-Eval that requires advanced reasoning abilities to solve. We conduct a comprehensive evaluation of the most advanced LLMs on C-Eval, including both English- and Chinese-oriented models. Results indicate that only GPT-4 could achieve an average accuracy of over 60%, suggesting that there is still significant room for improvement for current LLMs. We anticipate C-Eval will help analyze important strengths and shortcomings of foundation models, and foster their development and growth for Chinese users.
S-SimCSE: Sampled Sub-networks for Contrastive Learning of Sentence Embedding
Nov 24, 2021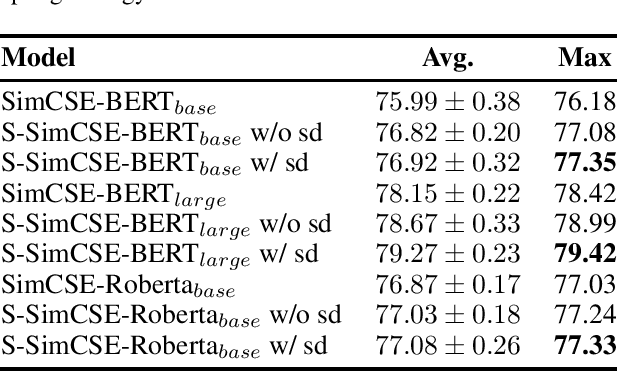
Contrastive learning has been studied for improving the performance of learning sentence embeddings. The current state-of-the-art method is the SimCSE, which takes dropout as the data augmentation method and feeds a pre-trained transformer encoder the same input sentence twice. The corresponding outputs, two sentence embeddings derived from the same sentence with different dropout masks, can be used to build a positive pair. A network being applied with a dropout mask can be regarded as a sub-network of itsef, whose expected scale is determined by the dropout rate. In this paper, we push sub-networks with different expected scales learn similar embedding for the same sentence. SimCSE failed to do so because they fixed the dropout rate to a tuned hyperparameter. We achieve this by sampling dropout rate from a distribution eatch forward process. As this method may make optimization harder, we also propose a simple sentence-wise mask strategy to sample more sub-networks. We evaluated the proposed S-SimCSE on several popular semantic text similarity datasets. Experimental results show that S-SimCSE outperforms the state-of-the-art SimCSE more than $1\%$ on BERT$_{base}$