 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistractMIA: Black-Box Membership Inference on Vision-Language Models via Semantic Distraction
May 12, 2026Vision-language models (VLMs) are trained on large-scale image-text corpora that may contain private, copyrighted, or otherwise sensitive data, motivating membership inference as a tool for training-data auditing. This is especially challenging for deployed VLMs, where auditors typically observe only generated textual responses. Existing VLM membership inference attacks either rely on probability-level signals unavailable in such settings, or use mask-based semantic prediction tasks whose effectiveness depends on object-centric visual assumptions. To address these limitations, we propose DistractMIA, an output-only black-box framework based on semantic distraction. Rather than removing visual evidence, DistractMIA preserves the original image, inserts a known semantic distractor, and measures how generated responses change. This design is motivated by the intuition that member samples remain more anchored to the original image semantics, while non-member samples are more easily redirected toward the distractor. To make this signal reliable, DistractMIA calibrates distractor configurations on a reference set and derives membership scores from repeated textual generations, capturing response stability and distractor uptake without accessing logits, probabilities, or hidden states. Experiments across multiple VLMs and benchmarks show that DistractMIA consistently outperforms both output-only and stronger-access baselines. Its performance on a medical benchmark further demonstrates applicability beyond object-centric natural images.
Perception Without Engagement: Dissecting the Causal Discovery Deficit in LMMs
May 10, 2026Although Large Multimodal Models (LMMs) have achieved strong performance on general video understanding, their susceptibility to textual prior shortcuts during causal discovery has been recognized as a critical deficit. The underlying mechanisms of this phenomenon remain incompletely understood, as existing benchmarks only measure response accuracy without revealing the sources and extent of the deficit. We introduce ProCauEval, a perturbation-based evaluation protocol that shifts from outcome assessment to mechanism diagnosis, probing causal discovery through five controlled configurations that systematically manipulate visual and textual modalities to decompose their respective contributions to model behavior and dissect the failure modes. Evaluating 17 mainstream LMMs, we find that models faithfully perceive video content yet systematically underexploit it during causal reasoning. We further observe that stronger post-training amplifies rather than mitigates textual prior reliance, and that higher baseline performance correlates with greater fragility under perturbation. To address these, we propose Anti-Distillation Policy Optimization (ADPO), a reinforcement learning framework built on negative teacher alignment, which augments GRPO by explicitly pushing the policy away from a prior-only counterfactual teacher induced by visual corruption. Specifically, ADPO maximizes the divergence between the policy distributions conditioned on the original and visually corrupted inputs, thereby forcing the model to ground its reasoning in visual evidence rather than textual shortcuts. Extensive experiments show that ADPO improves visual engagement without sacrificing fundamental comprehension, thus offering a preliminary step toward reliable causal discovery.
Analyzing Reasoning Consistency in Large Multimodal Models under Cross-Modal Conflicts
Jan 07, 2026Large Multimodal Models (LMMs) have demonstrated impressive capabilities in video reasoning via Chain-of-Thought (CoT). However, the robustness of their reasoning chains remains questionable. In this paper, we identify a critical failure mode termed textual inertia, where once a textual hallucination occurs in the thinking process, models tend to blindly adhere to the erroneous text while neglecting conflicting visual evidence. To systematically investigate this, we propose the LogicGraph Perturbation Protocol that structurally injects perturbations into the reasoning chains of diverse LMMs spanning both native reasoning architectures and prompt-driven paradigms to evaluate their self-reflection capabilities. The results reveal that models successfully self-correct in less than 10% of cases and predominantly succumb to blind textual error propagation. To mitigate this, we introduce Active Visual-Context Refinement, a training-free inference paradigm which orchestrates an active visual re-grounding mechanism to enforce fine-grained verification coupled with an adaptive context refinement strategy to summarize and denoise the reasoning history. Experiments demonstrate that our approach significantly stifles hallucination propagation and enhances reasoning robustness.
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Dec 29, 2025Memory serves as the pivotal nexus bridging past and future, providing both humans and AI systems with invaluable concepts and experience to navigate complex tasks. Recent research on autonomous agents has increasingly focused on designing efficient memory workflows by drawing on cognitive neuroscience. However, constrained by interdisciplinary barriers, existing works struggle to assimilate the essence of human memory mechanisms. To bridge this gap, we systematically synthesizes interdisciplinary knowledge of memory, connecting insights from cognitive neuroscience with LLM-driven agents. Specifically, we first elucidate the definition and function of memory along a progressive trajectory from cognitive neuroscience through LLMs to agents. We then provide a comparative analysis of memory taxonomy, storage mechanisms, and the complete management lifecycle from both biological and artificial perspectives. Subsequently, we review the mainstream benchmarks for evaluating agent memory. Additionally, we explore memory security from dual perspectives of attack and defense. Finally, we envision future research directions, with a focus on multimodal memory systems and skill acquisition.
Identifying Pre-training Data in LLMs: A Neuron Activation-Based Detection Framework
Jul 22, 2025The performance of large language models (LLMs) is closely tied to their training data, which can include copyrighted material or private information, raising legal and ethical concerns. Additionally, LLMs face criticism for dataset contamination and internalizing biases. To address these issues, the Pre-Training Data Detection (PDD) task was proposed to identify if specific data was included in an LLM's pre-training corpus. However, existing PDD methods often rely on superficial features like prediction confidence and loss, resulting in mediocre performance. To improve this, we introduce NA-PDD, a novel algorithm analyzing differential neuron activation patterns between training and non-training data in LLMs. This is based on the observation that these data types activate different neurons during LLM inference. We also introduce CCNewsPDD, a temporally unbiased benchmark employing rigorous data transformations to ensure consistent time distributions between training and non-training data. Our experiments demonstrate that NA-PDD significantly outperforms existing methods across three benchmarks and multiple LLMs.
Salient Temporal Encoding for Dynamic Scene Graph Generation
Mar 15, 2025Representing a dynamic scene using a structured spatial-temporal scene graph is a novel and particularly challenging task. To tackle this task, it is crucial to learn the temporal interactions between objects in addition to their spatial relations. Due to the lack of explicitly annotated temporal relations in current benchmark datasets, most of the existing spatial-temporal scene graph generation methods build dense and abstract temporal connections among all objects across frames. However, not all temporal connections are encoding meaningful temporal dynamics. We propose a novel spatial-temporal scene graph generation method that selectively builds temporal connections only between temporal-relevant objects pairs and represents the temporal relations as explicit edges in the scene graph. The resulting sparse and explicit temporal representation allows us to improve upon strong scene graph generation baselines by up to $4.4\%$ in Scene Graph Detection. In addition, we show that our approach can be leveraged to improve downstream vision tasks. Particularly, applying our approach to action recognition, shows 0.6\% gain in mAP in comparison to the state-of-the-art
TDDBench: A Benchmark for Training data detection
Nov 05, 2024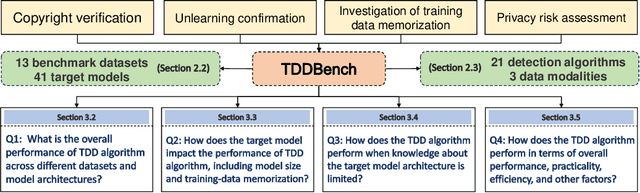
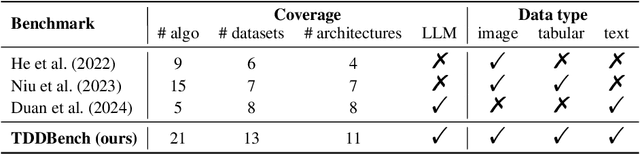

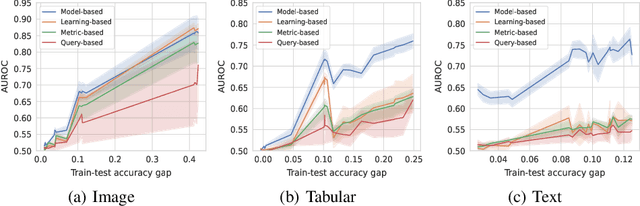
Training Data Detection (TDD) is a task aimed at determining whether a specific data instance is used to train a machine learning model. In the computer security literature, TDD is also referred to as Membership Inference Attack (MIA). Given its potential to assess the risks of training data breaches, ensure copyright authentication, and verify model unlearning, TDD has garnered significant attention in recent years, leading to the development of numerous methods. Despite these advancements, there is no comprehensive benchmark to thoroughly evaluate the effectiveness of TDD methods. In this work, we introduce TDDBench, which consists of 13 datasets spanning three data modalities: image, tabular, and text. We benchmark 21 different TDD methods across four detection paradigms and evaluate their performance from five perspectives: average detection performance, best detection performance, memory consumption, and computational efficiency in both time and memory. With TDDBench, researchers can identify bottlenecks and areas for improvement in TDD algorithms, while practitioners can make informed trade-offs between effectiveness and efficiency when selecting TDD algorithms for specific use cases. Our large-scale benchmarking also reveals the generally unsatisfactory performance of TDD algorithms across different datasets. To enhance accessibility and reproducibility, we open-source TDDBench for the research community.
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Apr 25, 2024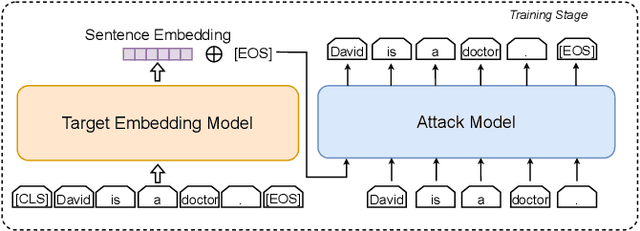
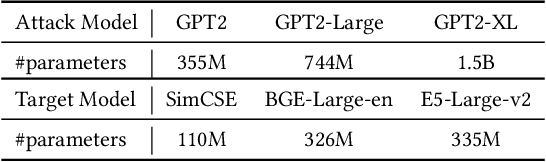
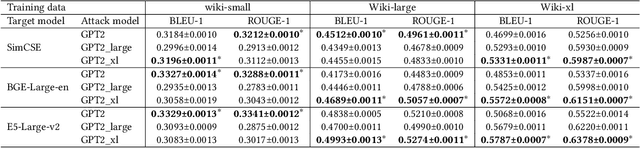

Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents
Jan 24, 2024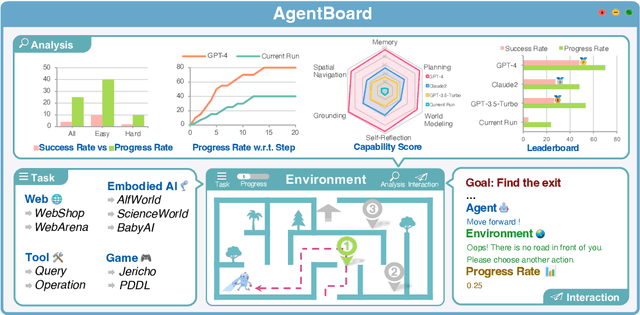

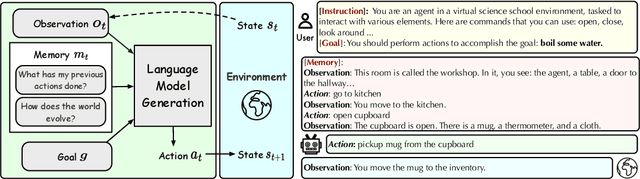

Evaluating large language models (LLMs) as general-purpose agents is essential for understanding their capabilities and facilitating their integration into practical applications. However, the evaluation process presents substantial challenges. A primary obstacle is the benchmarking of agent performance across diverse scenarios within a unified framework, especially in maintaining partially-observable environments and ensuring multi-round interactions. Moreover, current evaluation frameworks mostly focus on the final success rate, revealing few insights during the process and failing to provide a deep understanding of the model abilities. To address these challenges, we introduce AgentBoard, a pioneering comprehensive benchmark and accompanied open-source evaluation framework tailored to analytical evaluation of LLM agents. AgentBoard offers a fine-grained progress rate metric that captures incremental advancements as well as a comprehensive evaluation toolkit that features easy assessment of agents for multi-faceted analysis through interactive visualization. This not only sheds light on the capabilities and limitations of LLM agents but also propels the interpretability of their performance to the forefront. Ultimately, AgentBoard serves as a significant step towards demystifying agent behaviors and accelerating the development of stronger LLM agents.
Model Stealing Attack against Graph Classification with Authenticity, Uncertainty and Diversity
Dec 26, 2023Recent research demonstrates that GNNs are vulnerable to the model stealing attack, a nefarious endeavor geared towards duplicating the target model via query permissions. However, they mainly focus on node classification tasks, neglecting the potential threats entailed within the domain of graph classification tasks. Furthermore, their practicality is questionable due to unreasonable assumptions, specifically concerning the large data requirements and extensive model knowledge. To this end, we advocate following strict settings with limited real data and hard-label awareness to generate synthetic data, thereby facilitating the stealing of the target model. Specifically, following important data generation principles, we introduce three model stealing attacks to adapt to different actual scenarios: MSA-AU is inspired by active learning and emphasizes the uncertainty to enhance query value of generated samples; MSA-AD introduces diversity based on Mixup augmentation strategy to alleviate the query inefficiency issue caused by over-similar samples generated by MSA-AU; MSA-AUD combines the above two strategies to seamlessly integrate the authenticity, uncertainty, and diversity of the generated samples. Finally, extensive experiments consistently demonstrate the superiority of the proposed methods in terms of concealment, query efficiency, and stealing performance.