 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Lengthy Context With UltraGist
May 26, 2024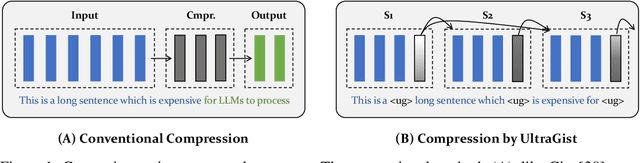
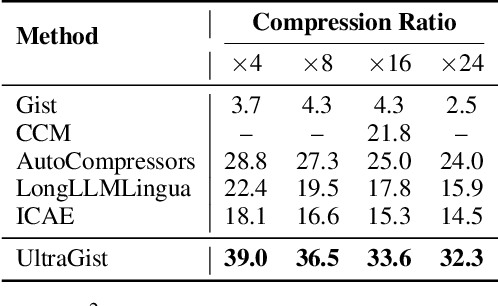
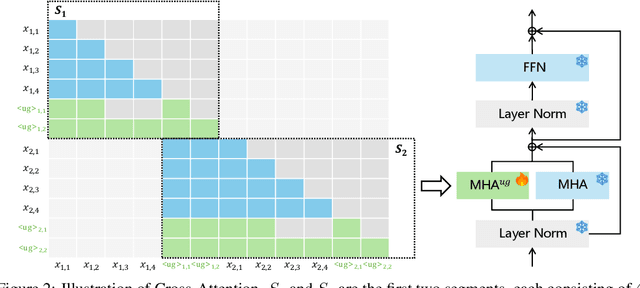
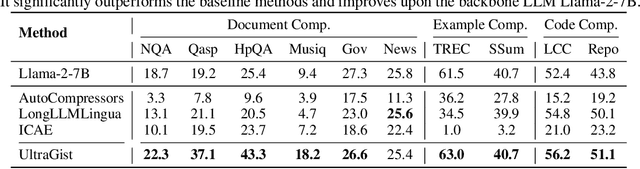
Compressing lengthy context is a critical but technically challenging problem. In this paper, we propose a new method called UltraGist, which is distinguished for its high-quality compression of lengthy context due to the innovative design of the compression and learning algorithm. UltraGist brings forth the following important benefits. Firstly, it notably contributes to the flexibility of compression, as it can be effectively learned to support a broad range of context lengths and compression ratios. Secondly, it helps to produce fine-grained compression for the lengthy context, where each small segment of the context is progressively processed on top of a tailored cross-attention mechanism. Thirdly, it makes the training process sample-efficient and thus maximizes the use of training data. Finally, it facilitates the efficient running of compression for dynamic context, as the compression result can be progressively generated and hence incrementally updated. UltraGist is evaluated on a wide variety of tasks associated with lengthy context, such as document QA and summarization, few-shot learning, multi-session conversation, et al. Whilst the existing methods fail to handle these challenging scenarios, our approach is able to preserve a near-lossless compression performance throughout all the evaluations. Our data, model, and code have been released at \url{https://github.com/namespace-Pt/UltraGist}.
Extending Llama-3's Context Ten-Fold Overnight
Apr 30, 2024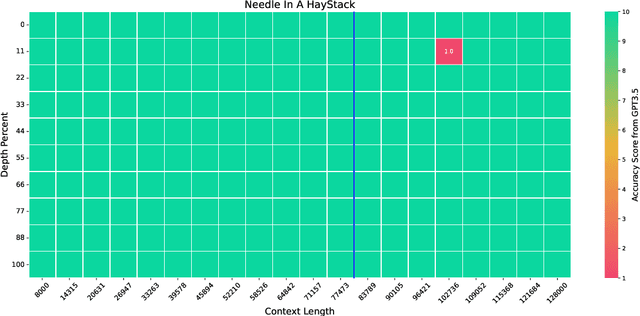
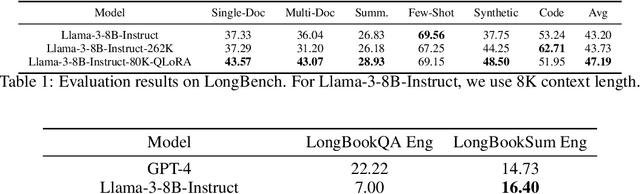
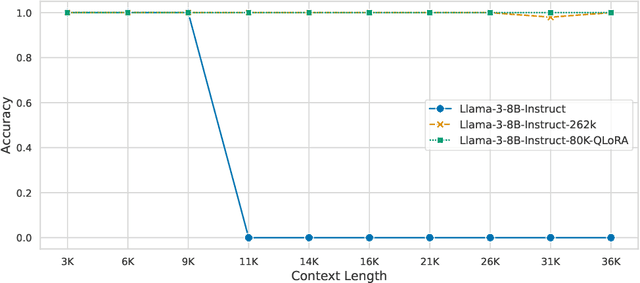
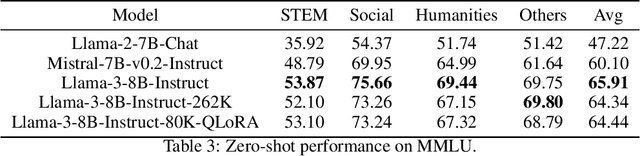
We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine. The resulted model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts. The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4 , which indicates the LLMs' inherent (yet largely underestimated) potential to extend its original context length. In fact, the context length could be extended far beyond 80K with more computation resources. Therefore, the team will publicly release the entire resources (including data, model, data generation pipeline, training code) so as to facilitate the future research from the community: \url{https://github.com/FlagOpen/FlagEmbedding}.
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Apr 25, 2024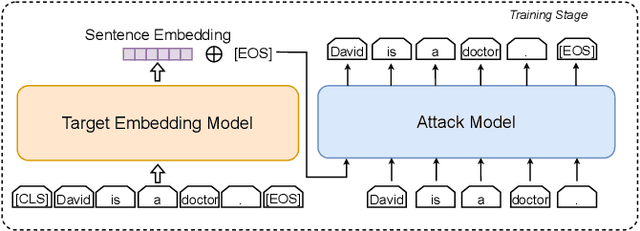
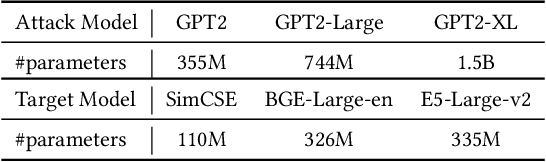
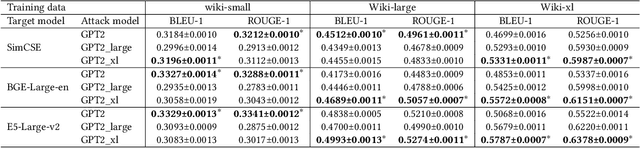

Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
Extensible Embedding: A Flexible Multipler For LLM's Context Length
Feb 18, 2024Large language models (LLMs) call for extension of context to handle many critical applications. However, the existing approaches are prone to expensive costs and inferior quality of context extension. In this work, we propose Extensible Embedding, which realizes high-quality extension of LLM's context with strong flexibility and cost-effectiveness. Extensible embedding stand as an enhancement of typical token embedding, which represents the information for an extensible scope of context instead of a single token. By leveraging such compact input units of higher information density, the LLM can access to a vast scope of context even with a small context window. Extensible embedding is systematically optimized in architecture and training method, which leads to multiple advantages. 1) High flexibility of context extension, which flexibly supports ad-hoc extension of diverse context lengths. 2) Strong sample efficiency of training, which enables the embedding model to be learned in a cost-effective way. 3) Superior compatibility with the existing LLMs, where the extensible embedding can be seamlessly introduced as a plug-in component. Comprehensive evaluations on long-context language modeling and understanding tasks verify extensible embedding as an effective, efficient, flexible, and compatible method to extend the LLM's context.
Flexibly Scaling Large Language Models Contexts Through Extensible Tokenization
Jan 15, 2024Large language models (LLMs) are in need of sufficient contexts to handle many critical applications, such as retrieval augmented generation and few-shot learning. However, due to the constrained window size, the LLMs can only access to the information within a limited context. Although the size of context window can be extended by fine-tuning, it will result in a substantial cost in both training and inference stage. In this paper, we present Extensible Tokenization as an alternative method which realizes the flexible scaling of LLMs' context. Extensible Tokenization stands as a midware in between of the tokenized context and the LLM, which transforms the raw token embeddings into the extensible embeddings. Such embeddings provide a more compact representation for the long context, on top of which the LLM is able to perceive more information with the same context window. Extensible Tokenization is also featured by its flexibility: the scaling factor can be flexibly determined within a feasible scope, leading to the extension of an arbitrary context length at the inference time. Besides, Extensible Tokenization is introduced as a drop-in component, which can be seamlessly plugged into not only the LLM itself and but also its fine-tuned derivatives, bringing in the extended contextual information while fully preserving the LLM's existing capabilities. We perform comprehensive experiments on long-context language modeling and understanding tasks, which verify Extensible Tokenization as an effective, efficient, flexible, and compatible method to extend LLM's context. Our model and source code will be made publicly available.
Soaring from 4K to 400K: Extending LLM's Context with Activation Beacon
Jan 07, 2024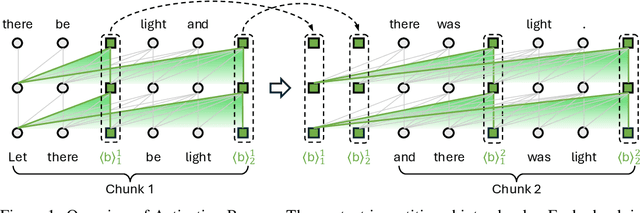
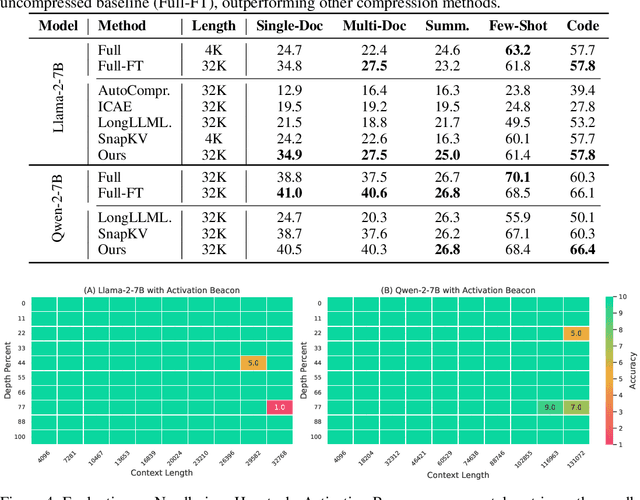
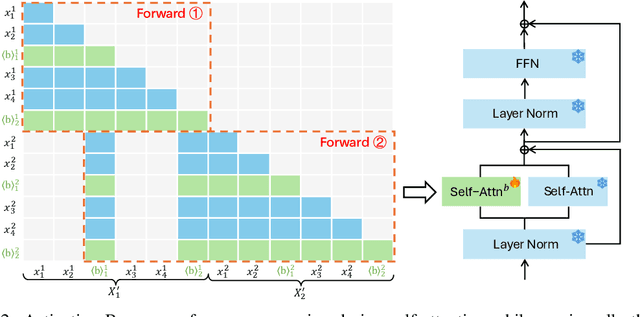
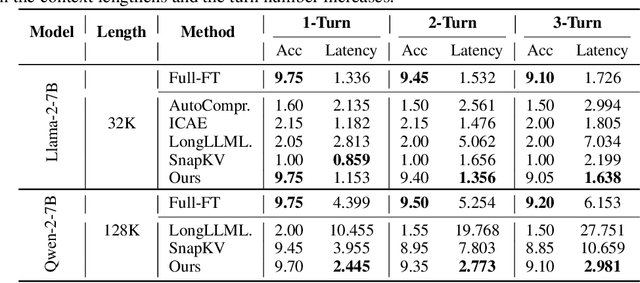
The utilization of long contexts poses a big challenge for large language models due to their limited context window length. Although the context window can be extended through fine-tuning, it will result in a considerable cost at both training and inference time, and exert an unfavorable impact to the LLM's original capabilities. In this work, we propose Activation Beacon, which condenses LLM's raw activations into more compact forms such that it can perceive a much longer context with a limited context window. Activation Beacon is introduced as a plug-and-play module for the LLM. It fully preserves the LLM's original capability on short contexts while extending the new capability on processing longer contexts. Besides, it works with short sliding windows to process the long context, which achieves a competitive memory and time efficiency in both training and inference. Activation Beacon is learned by the auto-regression task conditioned on a mixture of beacons with diversified condensing ratios. Thanks to such a treatment, it can be efficiently trained purely with short-sequence data in just 10K steps, which consumes less than 9 hours on a single 8xA800 GPU machine. The experimental studies show that Activation Beacon is able to extend Llama-2-7B's context length by $\times100$ times (from 4K to 400K), meanwhile achieving a superior result on both long-context generation and understanding tasks. Our model and code will be available at the BGE repository.
Uncovering ChatGPT's Capabilities in Recommender Systems
May 11, 2023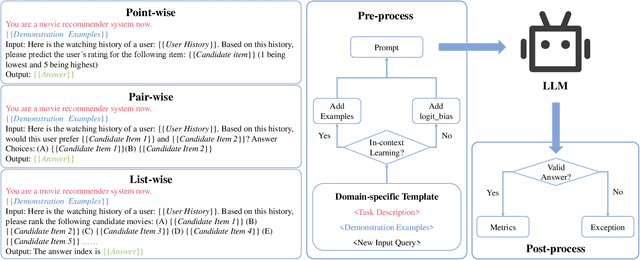
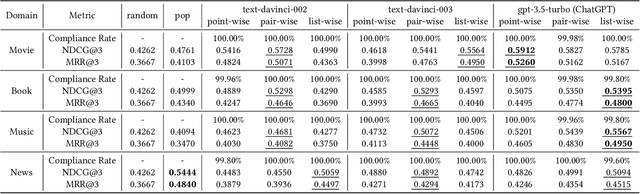

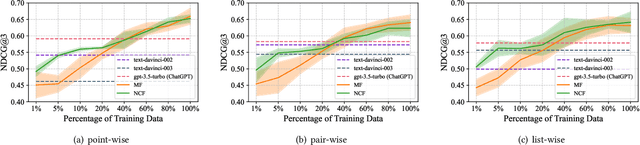
The debut of ChatGPT has recently attracted the attention of the natural language processing (NLP) community and beyond. Existing studies have demonstrated that ChatGPT shows significant improvement in a range of downstream NLP tasks, but the capabilities and limitations of ChatGPT in terms of recommendations remain unclear. In this study, we aim to conduct an empirical analysis of ChatGPT's recommendation ability from an Information Retrieval (IR) perspective, including point-wise, pair-wise, and list-wise ranking. To achieve this goal, we re-formulate the above three recommendation policies into a domain-specific prompt format. Through extensive experiments on four datasets from different domains, we demonstrate that ChatGPT outperforms other large language models across all three ranking policies. Based on the analysis of unit cost improvements, we identify that ChatGPT with list-wise ranking achieves the best trade-off between cost and performance compared to point-wise and pair-wise ranking. Moreover, ChatGPT shows the potential for mitigating the cold start problem and explainable recommendation. To facilitate further explorations in this area, the full code and detailed original results are open-sourced at https://github.com/rainym00d/LLM4RS.
Partial Information as Full: Reward Imputation with Sketching in Bandits
Oct 20, 2022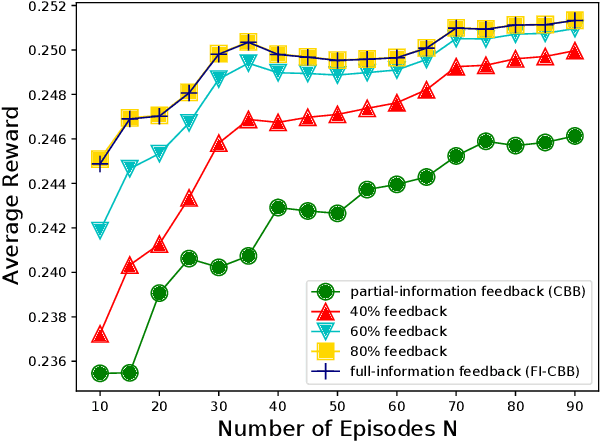

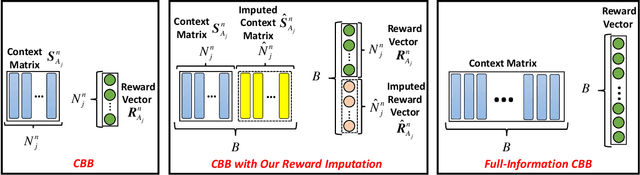
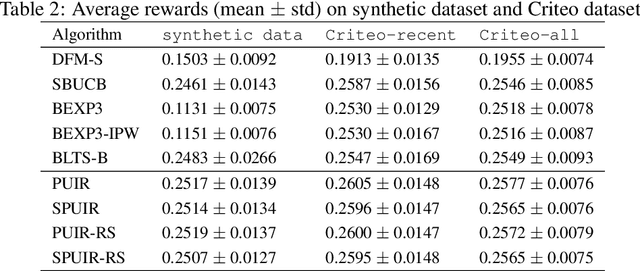
We focus on the setting of contextual batched bandit (CBB), where a batch of rewards is observed from the environment in each episode. But the rewards of the non-executed actions are unobserved (i.e., partial-information feedbacks). Existing approaches for CBB usually ignore the rewards of the non-executed actions, resulting in feedback information being underutilized. In this paper, we propose an efficient reward imputation approach using sketching for CBB, which completes the unobserved rewards with the imputed rewards approximating the full-information feedbacks. Specifically, we formulate the reward imputation as a problem of imputation regularized ridge regression, which captures the feedback mechanisms of both the non-executed and executed actions. To reduce the time complexity of reward imputation, we solve the regression problem using randomized sketching. We prove that our reward imputation approach obtains a relative-error bound for sketching approximation, achieves an instantaneous regret with a controllable bias and a smaller variance than that without reward imputation, and enjoys a sublinear regret bound against the optimal policy. Moreover, we present two extensions of our approach, including the rate-scheduled version and the version for nonlinear rewards, making our approach more feasible. Experimental results demonstrated that our approach can outperform the state-of-the-art baselines on synthetic and real-world datasets.