 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Lengthy Context With UltraGist
Paper and Code
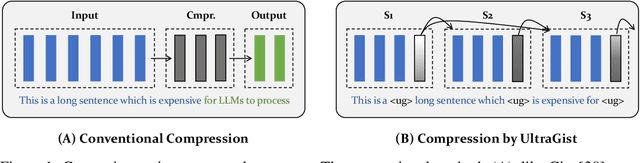
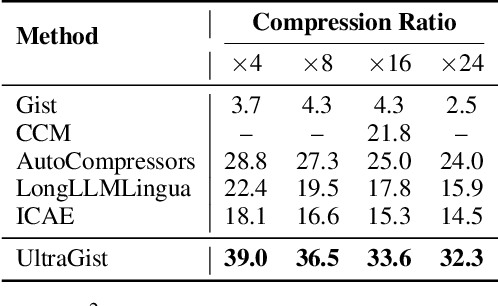
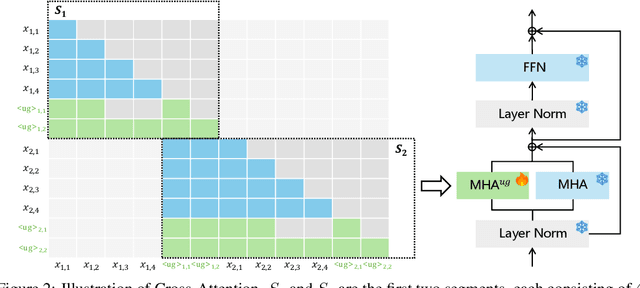
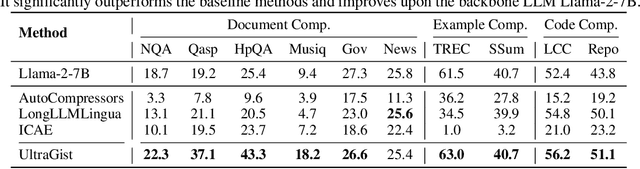
Compressing lengthy context is a critical but technically challenging problem. In this paper, we propose a new method called UltraGist, which is distinguished for its high-quality compression of lengthy context due to the innovative design of the compression and learning algorithm. UltraGist brings forth the following important benefits. Firstly, it notably contributes to the flexibility of compression, as it can be effectively learned to support a broad range of context lengths and compression ratios. Secondly, it helps to produce fine-grained compression for the lengthy context, where each small segment of the context is progressively processed on top of a tailored cross-attention mechanism. Thirdly, it makes the training process sample-efficient and thus maximizes the use of training data. Finally, it facilitates the efficient running of compression for dynamic context, as the compression result can be progressively generated and hence incrementally updated. UltraGist is evaluated on a wide variety of tasks associated with lengthy context, such as document QA and summarization, few-shot learning, multi-session conversation, et al. Whilst the existing methods fail to handle these challenging scenarios, our approach is able to preserve a near-lossless compression performance throughout all the evaluations. Our data, model, and code have been released at \url{https://github.com/namespace-Pt/UltraGist}.