 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawKeeper: Comprehensive Safety Protection for OpenClaw Agents Through Skills, Plugins, and Watchers
Mar 25, 2026OpenClaw has rapidly established itself as a leading open-source autonomous agent runtime, offering powerful capabilities including tool integration, local file access, and shell command execution. However, these broad operational privileges introduce critical security vulnerabilities, transforming model errors into tangible system-level threats such as sensitive data leakage, privilege escalation, and malicious third-party skill execution. Existing security measures for the OpenClaw ecosystem remain highly fragmented, addressing only isolated stages of the agent lifecycle rather than providing holistic protection. To bridge this gap, we present ClawKeeper, a real-time security framework that integrates multi-dimensional protection mechanisms across three complementary architectural layers. (1) \textbf{Skill-based protection} operates at the instruction level, injecting structured security policies directly into the agent context to enforce environment-specific constraints and cross-platform boundaries. (2) \textbf{Plugin-based protection} serves as an internal runtime enforcer, providing configuration hardening, proactive threat detection, and continuous behavioral monitoring throughout the execution pipeline. (3) \textbf{Watcher-based protection} introduces a novel, decoupled system-level security middleware that continuously verifies agent state evolution. It enables real-time execution intervention without coupling to the agent's internal logic, supporting operations such as halting high-risk actions or enforcing human confirmation. We argue that this Watcher paradigm holds strong potential to serve as a foundational building block for securing next-generation autonomous agent systems. Extensive qualitative and quantitative evaluations demonstrate the effectiveness and robustness of ClawKeeper across diverse threat scenarios. We release our code.
Autoregressive Visual Decoding from EEG Signals
Feb 26, 2026Electroencephalogram (EEG) signals have become a popular medium for decoding visual information due to their cost-effectiveness and high temporal resolution. However, current approaches face significant challenges in bridging the modality gap between EEG and image data. These methods typically rely on complex adaptation processes involving multiple stages, making it hard to maintain consistency and manage compounding errors. Furthermore, the computational overhead imposed by large-scale diffusion models limit their practicality in real-world brain-computer interface (BCI) applications. In this work, we present AVDE, a lightweight and efficient framework for visual decoding from EEG signals. First, we leverage LaBraM, a pre-trained EEG model, and fine-tune it via contrastive learning to align EEG and image representations. Second, we adopt an autoregressive generative framework based on a "next-scale prediction" strategy: images are encoded into multi-scale token maps using a pre-trained VQ-VAE, and a transformer is trained to autoregressively predict finer-scale tokens starting from EEG embeddings as the coarsest representation. This design enables coherent generation while preserving a direct connection between the input EEG signals and the reconstructed images. Experiments on two datasets show that AVDE outperforms previous state-of-the-art methods in both image retrieval and reconstruction tasks, while using only 10% of the parameters. In addition, visualization of intermediate outputs shows that the generative process of AVDE reflects the hierarchical nature of human visual perception. These results highlight the potential of autoregressive models as efficient and interpretable tools for practical BCI applications.
The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies
Feb 11, 2026The emergence of multi-agent systems built from large language models (LLMs) offers a promising paradigm for scalable collective intelligence and self-evolution. Ideally, such systems would achieve continuous self-improvement in a fully closed loop while maintaining robust safety alignment--a combination we term the self-evolution trilemma. However, we demonstrate both theoretically and empirically that an agent society satisfying continuous self-evolution, complete isolation, and safety invariance is impossible. Drawing on an information-theoretic framework, we formalize safety as the divergence degree from anthropic value distributions. We theoretically demonstrate that isolated self-evolution induces statistical blind spots, leading to the irreversible degradation of the system's safety alignment. Empirical and qualitative results from an open-ended agent community (Moltbook) and two closed self-evolving systems reveal phenomena that align with our theoretical prediction of inevitable safety erosion. We further propose several solution directions to alleviate the identified safety concern. Our work establishes a fundamental limit on the self-evolving AI societies and shifts the discourse from symptom-driven safety patches to a principled understanding of intrinsic dynamical risks, highlighting the need for external oversight or novel safety-preserving mechanisms.
FloydNet: A Learning Paradigm for Global Relational Reasoning
Jan 27, 2026Developing models capable of complex, multi-step reasoning is a central goal in artificial intelligence. While representing problems as graphs is a powerful approach, Graph Neural Networks (GNNs) are fundamentally constrained by their message-passing mechanism, which imposes a local bottleneck that limits global, holistic reasoning. We argue that dynamic programming (DP), which solves problems by iteratively refining a global state, offers a more powerful and suitable learning paradigm. We introduce FloydNet, a new architecture that embodies this principle. In contrast to local message passing, FloydNet maintains a global, all-pairs relationship tensor and learns a generalized DP operator to progressively refine it. This enables the model to develop a task-specific relational calculus, providing a principled framework for capturing long-range dependencies. Theoretically, we prove that FloydNet achieves 3-WL (2-FWL) expressive power, and its generalized form aligns with the k-FWL hierarchy. FloydNet demonstrates state-of-the-art performance across challenging domains: it achieves near-perfect scores (often >99\%) on the CLRS-30 algorithmic benchmark, finds exact optimal solutions for the general Traveling Salesman Problem (TSP) at rates significantly exceeding strong heuristics, and empirically matches the 3-WL test on the BREC benchmark. Our results establish this learned, DP-style refinement as a powerful and practical alternative to message passing for high-level graph reasoning.
EPO: Diverse and Realistic Protein Ensemble Generation via Energy Preference Optimization
Nov 13, 2025Accurate exploration of protein conformational ensembles is essential for uncovering function but remains hard because molecular-dynamics (MD) simulations suffer from high computational costs and energy-barrier trapping. This paper presents Energy Preference Optimization (EPO), an online refinement algorithm that turns a pretrained protein ensemble generator into an energy-aware sampler without extra MD trajectories. Specifically, EPO leverages stochastic differential equation sampling to explore the conformational landscape and incorporates a novel energy-ranking mechanism based on list-wise preference optimization. Crucially, EPO introduces a practical upper bound to efficiently approximate the intractable probability of long sampling trajectories in continuous-time generative models, making it easily adaptable to existing pretrained generators. On Tetrapeptides, ATLAS, and Fast-Folding benchmarks, EPO successfully generates diverse and physically realistic ensembles, establishing a new state-of-the-art in nine evaluation metrics. These results demonstrate that energy-only preference signals can efficiently steer generative models toward thermodynamically consistent conformational ensembles, providing an alternative to long MD simulations and widening the applicability of learned potentials in structural biology and drug discovery.
The Latent Road to Atoms: Backmapping Coarse-grained Protein Structures with Latent Diffusion
Oct 17, 2024
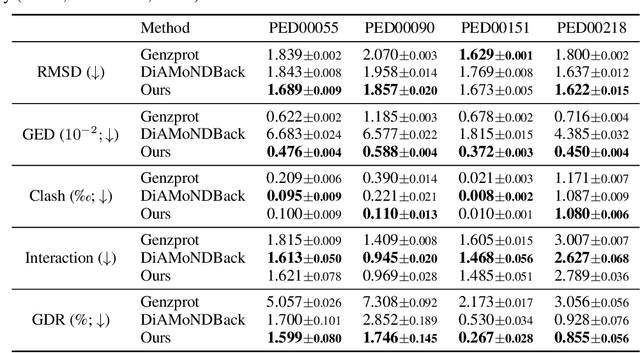
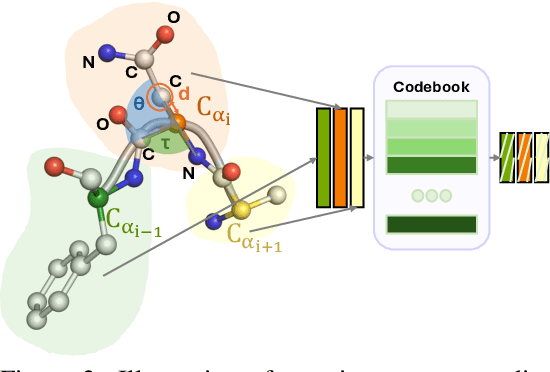
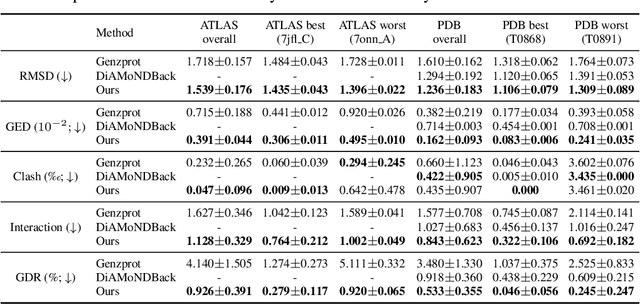
Coarse-grained(CG) molecular dynamics simulations offer computational efficiency for exploring protein conformational ensembles and thermodynamic properties. Though coarse representations enable large-scale simulations across extended temporal and spatial ranges, the sacrifice of atomic-level details limits their utility in tasks such as ligand docking and protein-protein interaction prediction. Backmapping, the process of reconstructing all-atom structures from coarse-grained representations, is crucial for recovering these fine details. While recent machine learning methods have made strides in protein structure generation, challenges persist in reconstructing diverse atomistic conformations that maintain geometric accuracy and chemical validity. In this paper, we present Latent Diffusion Backmapping (LDB), a novel approach leveraging denoising diffusion within latent space to address these challenges. By combining discrete latent encoding with diffusion, LDB bypasses the need for equivariant and internal coordinate manipulation, significantly simplifying the training and sampling processes as well as facilitating better and wider exploration in configuration space. We evaluate LDB's state-of-the-art performance on three distinct protein datasets, demonstrating its ability to efficiently reconstruct structures with high structural accuracy and chemical validity. Moreover, LDB shows exceptional versatility in capturing diverse protein ensembles, highlighting its capability to explore intricate conformational spaces. Our results position LDB as a powerful and scalable approach for backmapping, effectively bridging the gap between CG simulations and atomic-level analyses in computational biology.
Pre-training with Fractional Denoising to Enhance Molecular Property Prediction
Jul 14, 2024Deep learning methods have been considered promising for accelerating molecular screening in drug discovery and material design. Due to the limited availability of labelled data, various self-supervised molecular pre-training methods have been presented. While many existing methods utilize common pre-training tasks in computer vision (CV) and natural language processing (NLP), they often overlook the fundamental physical principles governing molecules. In contrast, applying denoising in pre-training can be interpreted as an equivalent force learning, but the limited noise distribution introduces bias into the molecular distribution. To address this issue, we introduce a molecular pre-training framework called fractional denoising (Frad), which decouples noise design from the constraints imposed by force learning equivalence. In this way, the noise becomes customizable, allowing for incorporating chemical priors to significantly improve molecular distribution modeling. Experiments demonstrate that our framework consistently outperforms existing methods, establishing state-of-the-art results across force prediction, quantum chemical properties, and binding affinity tasks. The refined noise design enhances force accuracy and sampling coverage, which contribute to the creation of physically consistent molecular representations, ultimately leading to superior predictive performance.
Compressing Lengthy Context With UltraGist
May 26, 2024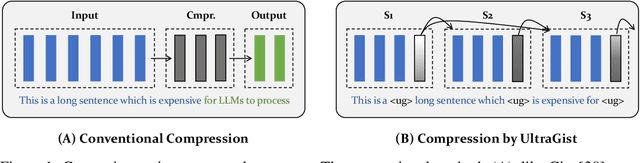
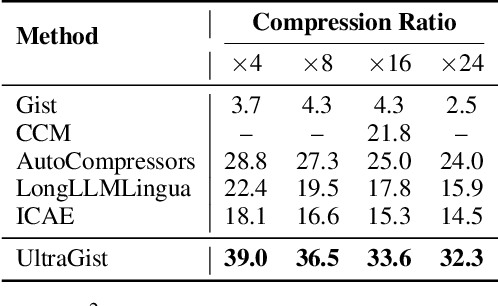
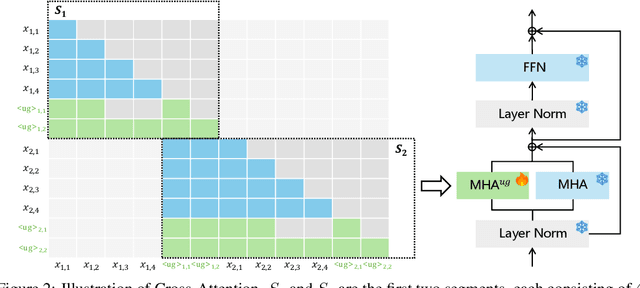
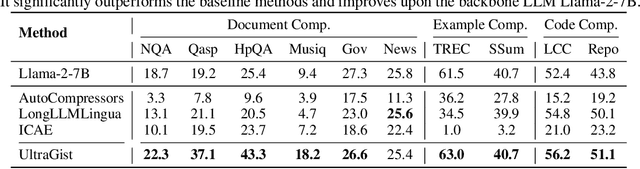
Compressing lengthy context is a critical but technically challenging problem. In this paper, we propose a new method called UltraGist, which is distinguished for its high-quality compression of lengthy context due to the innovative design of the compression and learning algorithm. UltraGist brings forth the following important benefits. Firstly, it notably contributes to the flexibility of compression, as it can be effectively learned to support a broad range of context lengths and compression ratios. Secondly, it helps to produce fine-grained compression for the lengthy context, where each small segment of the context is progressively processed on top of a tailored cross-attention mechanism. Thirdly, it makes the training process sample-efficient and thus maximizes the use of training data. Finally, it facilitates the efficient running of compression for dynamic context, as the compression result can be progressively generated and hence incrementally updated. UltraGist is evaluated on a wide variety of tasks associated with lengthy context, such as document QA and summarization, few-shot learning, multi-session conversation, et al. Whilst the existing methods fail to handle these challenging scenarios, our approach is able to preserve a near-lossless compression performance throughout all the evaluations. Our data, model, and code have been released at \url{https://github.com/namespace-Pt/UltraGist}.
Extending Llama-3's Context Ten-Fold Overnight
Apr 30, 2024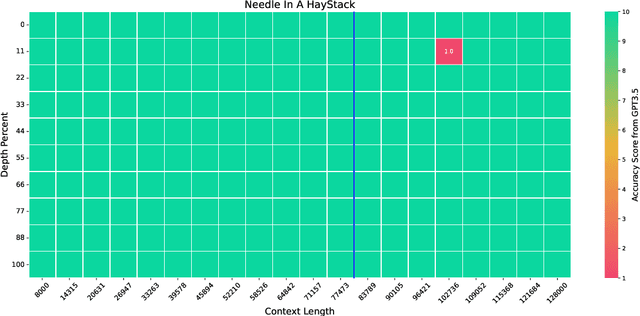
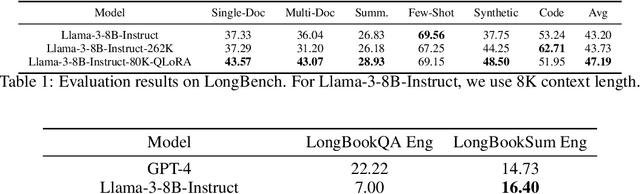
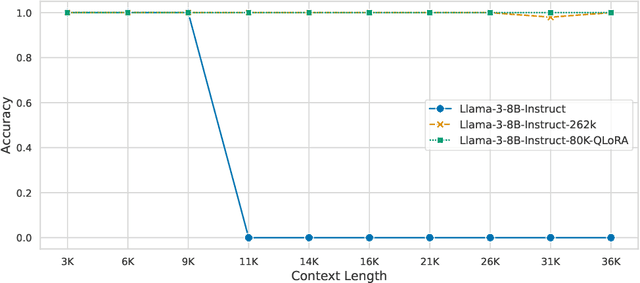
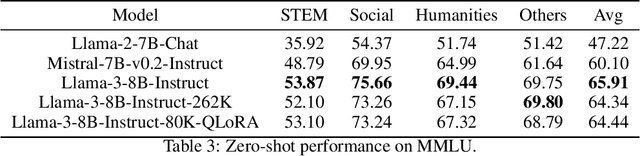
We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine. The resulted model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts. The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4 , which indicates the LLMs' inherent (yet largely underestimated) potential to extend its original context length. In fact, the context length could be extended far beyond 80K with more computation resources. Therefore, the team will publicly release the entire resources (including data, model, data generation pipeline, training code) so as to facilitate the future research from the community: \url{https://github.com/FlagOpen/FlagEmbedding}.
SGNet: Folding Symmetrical Protein Complex with Deep Learning
Mar 07, 2024Deep learning has made significant progress in protein structure prediction, advancing the development of computational biology. However, despite the high accuracy achieved in predicting single-chain structures, a significant number of large homo-oligomeric assemblies exhibit internal symmetry, posing a major challenge in structure determination. The performances of existing deep learning methods are limited since the symmetrical protein assembly usually has a long sequence, making structural computation infeasible. In addition, multiple identical subunits in symmetrical protein complex cause the issue of supervision ambiguity in label assignment, requiring a consistent structure modeling for the training. To tackle these problems, we propose a protein folding framework called SGNet to model protein-protein interactions in symmetrical assemblies. SGNet conducts feature extraction on a single subunit and generates the whole assembly using our proposed symmetry module, which largely mitigates computational problems caused by sequence length. Thanks to the elaborate design of modeling symmetry consistently, we can model all global symmetry types in quaternary protein structure prediction. Extensive experimental results on a benchmark of symmetrical protein complexes further demonstrate the effectiveness of our method.