 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Llama-3's Context Ten-Fold Overnight
Paper and Code
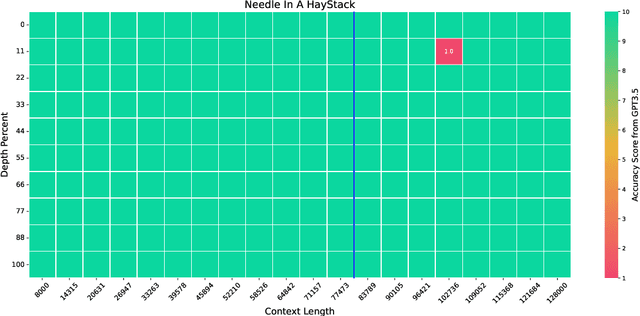
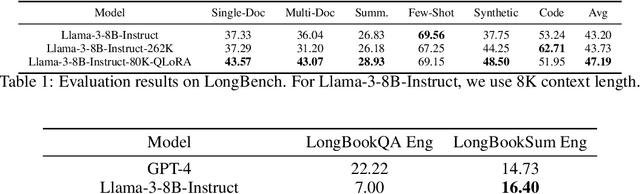
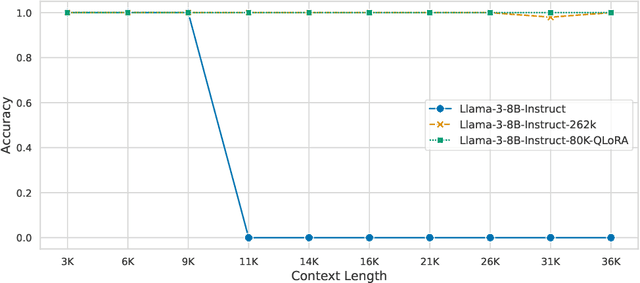
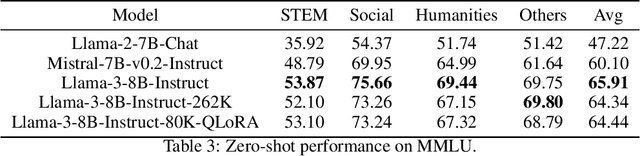
We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine. The resulted model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts. The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4 , which indicates the LLMs' inherent (yet largely underestimated) potential to extend its original context length. In fact, the context length could be extended far beyond 80K with more computation resources. Therefore, the team will publicly release the entire resources (including data, model, data generation pipeline, training code) so as to facilitate the future research from the community: \url{https://github.com/FlagOpen/FlagEmbedding}.