 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoFlow: Reinforcing Search Agent Via Reward Density Optimization
Oct 30, 2025Reinforcement Learning with Verifiable Rewards (RLVR) is a promising approach for enhancing agentic deep search. However, its application is often hindered by low \textbf{Reward Density} in deep search scenarios, where agents expend significant exploratory costs for infrequent and often null final rewards. In this paper, we formalize this challenge as the \textbf{Reward Density Optimization} problem, which aims to improve the reward obtained per unit of exploration cost. This paper introduce \textbf{InfoFlow}, a systematic framework that tackles this problem from three aspects. 1) \textbf{Subproblem decomposition}: breaking down long-range tasks to assign process rewards, thereby providing denser learning signals. 2) \textbf{Failure-guided hints}: injecting corrective guidance into stalled trajectories to increase the probability of successful outcomes. 3) \textbf{Dual-agent refinement}: employing a dual-agent architecture to offload the cognitive burden of deep exploration. A refiner agent synthesizes the search history, which effectively compresses the researcher's perceived trajectory, thereby reducing exploration cost and increasing the overall reward density. We evaluate InfoFlow on multiple agentic search benchmarks, where it significantly outperforms strong baselines, enabling lightweight LLMs to achieve performance comparable to advanced proprietary LLMs.
Video-XL-2: Towards Very Long-Video Understanding Through Task-Aware KV Sparsification
Jun 24, 2025Multi-modal large language models (MLLMs) models have made significant progress in video understanding over the past few years. However, processing long video inputs remains a major challenge due to high memory and computational costs. This makes it difficult for current models to achieve both strong performance and high efficiency in long video understanding. To address this challenge, we propose Video-XL-2, a novel MLLM that delivers superior cost-effectiveness for long-video understanding based on task-aware KV sparsification. The proposed framework operates with two key steps: chunk-based pre-filling and bi-level key-value decoding. Chunk-based pre-filling divides the visual token sequence into chunks, applying full attention within each chunk and sparse attention across chunks. This significantly reduces computational and memory overhead. During decoding, bi-level key-value decoding selectively reloads either dense or sparse key-values for each chunk based on its relevance to the task. This approach further improves memory efficiency and enhances the model's ability to capture fine-grained information. Video-XL-2 achieves state-of-the-art performance on various long video understanding benchmarks, outperforming existing open-source lightweight models. It also demonstrates exceptional efficiency, capable of processing over 10,000 frames on a single NVIDIA A100 (80GB) GPU and thousands of frames in just a few seconds.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
EfficientLLM: Scalable Pruning-Aware Pretraining for Architecture-Agnostic Edge Language Models
Feb 10, 2025Modern large language models (LLMs) driven by scaling laws, achieve intelligence emergency in large model sizes. Recently, the increasing concerns about cloud costs, latency, and privacy make it an urgent requirement to develop compact edge language models. Distinguished from direct pretraining that bounded by the scaling law, this work proposes the pruning-aware pretraining, focusing on retaining performance of much larger optimized models. It features following characteristics: 1) Data-scalable: we introduce minimal parameter groups in LLM and continuously optimize structural pruning, extending post-training pruning methods like LLM-Pruner and SparseGPT into the pretraining phase. 2) Architecture-agnostic: the LLM architecture is auto-designed using saliency-driven pruning, which is the first time to exceed SoTA human-designed LLMs in modern pretraining. We reveal that it achieves top-quality edge language models, termed EfficientLLM, by scaling up LLM compression and extending its boundary. EfficientLLM significantly outperforms SoTA baselines with $100M \sim 1B$ parameters, such as MobileLLM, SmolLM, Qwen2.5-0.5B, OLMo-1B, Llama3.2-1B in common sense benchmarks. As the first attempt, EfficientLLM bridges the performance gap between traditional LLM compression and direct pretraining methods, and we will fully open source at https://github.com/Xingrun-Xing2/EfficientLLM.
Matryoshka Re-Ranker: A Flexible Re-Ranking Architecture With Configurable Depth and Width
Jan 27, 2025



Large language models (LLMs) provide powerful foundations to perform fine-grained text re-ranking. However, they are often prohibitive in reality due to constraints on computation bandwidth. In this work, we propose a \textbf{flexible} architecture called \textbf{Matroyshka Re-Ranker}, which is designed to facilitate \textbf{runtime customization} of model layers and sequence lengths at each layer based on users' configurations. Consequently, the LLM-based re-rankers can be made applicable across various real-world situations. The increased flexibility may come at the cost of precision loss. To address this problem, we introduce a suite of techniques to optimize the performance. First, we propose \textbf{cascaded self-distillation}, where each sub-architecture learns to preserve a precise re-ranking performance from its super components, whose predictions can be exploited as smooth and informative teacher signals. Second, we design a \textbf{factorized compensation mechanism}, where two collaborative Low-Rank Adaptation modules, vertical and horizontal, are jointly employed to compensate for the precision loss resulted from arbitrary combinations of layer and sequence compression. We perform comprehensive experiments based on the passage and document retrieval datasets from MSMARCO, along with all public datasets from BEIR benchmark. In our experiments, Matryoshka Re-Ranker substantially outperforms the existing methods, while effectively preserving its superior performance across various forms of compression and different application scenarios.
MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval
Dec 19, 2024Despite the rapidly growing demand for multimodal retrieval, progress in this field remains severely constrained by a lack of training data. In this paper, we introduce MegaPairs, a novel data synthesis method that leverages vision language models (VLMs) and open-domain images, together with a massive synthetic dataset generated from this method. Our empirical analysis shows that MegaPairs generates high-quality data, enabling the multimodal retriever to significantly outperform the baseline model trained on 70$\times$ more data from existing datasets. Moreover, since MegaPairs solely relies on general image corpora and open-source VLMs, it can be easily scaled up, enabling continuous improvements in retrieval performance. In this stage, we produced more than 26 million training instances and trained several models of varying sizes using this data. These new models achieve state-of-the-art zero-shot performance across 4 popular composed image retrieval (CIR) benchmarks and the highest overall performance on the 36 datasets provided by MMEB. They also demonstrate notable performance improvements with additional downstream fine-tuning. Our produced dataset, well-trained models, and data synthesis pipeline will be made publicly available to facilitate the future development of this field.
AIR-Bench: Automated Heterogeneous Information Retrieval Benchmark
Dec 17, 2024



Evaluation plays a crucial role in the advancement of information retrieval (IR) models. However, current benchmarks, which are based on predefined domains and human-labeled data, face limitations in addressing evaluation needs for emerging domains both cost-effectively and efficiently. To address this challenge, we propose the Automated Heterogeneous Information Retrieval Benchmark (AIR-Bench). AIR-Bench is distinguished by three key features: 1) Automated. The testing data in AIR-Bench is automatically generated by large language models (LLMs) without human intervention. 2) Heterogeneous. The testing data in AIR-Bench is generated with respect to diverse tasks, domains and languages. 3) Dynamic. The domains and languages covered by AIR-Bench are constantly augmented to provide an increasingly comprehensive evaluation benchmark for community developers. We develop a reliable and robust data generation pipeline to automatically create diverse and high-quality evaluation datasets based on real-world corpora. Our findings demonstrate that the generated testing data in AIR-Bench aligns well with human-labeled testing data, making AIR-Bench a dependable benchmark for evaluating IR models. The resources in AIR-Bench are publicly available at https://github.com/AIR-Bench/AIR-Bench.
OmniGen: Unified Image Generation
Sep 17, 2024
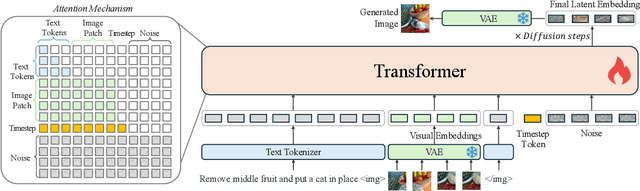
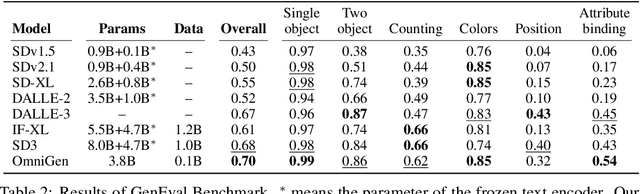

In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at https://github.com/VectorSpaceLab/OmniGen to foster advancements in this field.
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
Aug 23, 2024



Pretrained language models like BERT and T5 serve as crucial backbone encoders for dense retrieval. However, these models often exhibit limited generalization capabilities and face challenges in improving in domain accuracy. Recent research has explored using large language models (LLMs) as retrievers, achieving SOTA performance across various tasks. Despite these advancements, the specific benefits of LLMs over traditional retrievers and the impact of different LLM configurations, such as parameter sizes, pretraining duration, and alignment processes on retrieval tasks remain unclear. In this work, we conduct a comprehensive empirical study on a wide range of retrieval tasks, including in domain accuracy, data efficiency, zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. We evaluate over 15 different backbone LLMs and non LLMs. Our findings reveal that larger models and extensive pretraining consistently enhance in domain accuracy and data efficiency. Additionally, larger models demonstrate significant potential in zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. These results underscore the advantages of LLMs as versatile and effective backbone encoders in dense retrieval, providing valuable insights for future research and development in this field.