 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProact-VL: A Proactive VideoLLM for Real-Time AI Companions
Mar 03, 2026Proactive and real-time interactive experiences are essential for human-like AI companions, yet face three key challenges: (1) achieving low-latency inference under continuous streaming inputs, (2) autonomously deciding when to respond, and (3) controlling both quality and quantity of generated content to meet real-time constraints. In this work, we instantiate AI companions through two gaming scenarios, commentator and guide, selected for their suitability for automatic evaluation. We introduce the Live Gaming Benchmark, a large-scale dataset with three representative scenarios: solo commentary, co-commentary, and user guidance, and present Proact-VL, a general framework that shapes multimodal language models into proactive, real-time interactive agents capable of human-like environment perception and interaction. Extensive experiments show Proact-VL achieves superior response latency and quality while maintaining strong video understanding capabilities, demonstrating its practicality for real-time interactive applications.
Avoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs
May 06, 2025Large Language Models (LLMs) have shown promise for generative recommender systems due to their transformative capabilities in user interaction. However, ensuring they do not recommend out-of-domain (OOD) items remains a challenge. We study two distinct methods to address this issue: RecLM-ret, a retrieval-based method, and RecLM-cgen, a constrained generation method. Both methods integrate seamlessly with existing LLMs to ensure in-domain recommendations. Comprehensive experiments on three recommendation datasets demonstrate that RecLM-cgen consistently outperforms RecLM-ret and existing LLM-based recommender models in accuracy while eliminating OOD recommendations, making it the preferred method for adoption. Additionally, RecLM-cgen maintains strong generalist capabilities and is a lightweight plug-and-play module for easy integration into LLMs, offering valuable practical benefits for the community. Source code is available at https://github.com/microsoft/RecAI
AIR-Bench: Automated Heterogeneous Information Retrieval Benchmark
Dec 17, 2024



Evaluation plays a crucial role in the advancement of information retrieval (IR) models. However, current benchmarks, which are based on predefined domains and human-labeled data, face limitations in addressing evaluation needs for emerging domains both cost-effectively and efficiently. To address this challenge, we propose the Automated Heterogeneous Information Retrieval Benchmark (AIR-Bench). AIR-Bench is distinguished by three key features: 1) Automated. The testing data in AIR-Bench is automatically generated by large language models (LLMs) without human intervention. 2) Heterogeneous. The testing data in AIR-Bench is generated with respect to diverse tasks, domains and languages. 3) Dynamic. The domains and languages covered by AIR-Bench are constantly augmented to provide an increasingly comprehensive evaluation benchmark for community developers. We develop a reliable and robust data generation pipeline to automatically create diverse and high-quality evaluation datasets based on real-world corpora. Our findings demonstrate that the generated testing data in AIR-Bench aligns well with human-labeled testing data, making AIR-Bench a dependable benchmark for evaluating IR models. The resources in AIR-Bench are publicly available at https://github.com/AIR-Bench/AIR-Bench.
Exploring Loss Landscapes through the Lens of Spin Glass Theory
Jul 30, 2024



In the past decade, significant strides in deep learning have led to numerous groundbreaking applications. Despite these advancements, the understanding of the high generalizability of deep learning, especially in such an over-parametrized space, remains limited. Successful applications are often considered as empirical rather than scientific achievements. For instance, deep neural networks' (DNNs) internal representations, decision-making mechanism, absence of overfitting in an over-parametrized space, high generalizability, etc., remain less understood. This paper delves into the loss landscape of DNNs through the lens of spin glass in statistical physics, i.e. a system characterized by a complex energy landscape with numerous metastable states, to better understand how DNNs work. We investigated a single hidden layer Rectified Linear Unit (ReLU) neural network model, and introduced several protocols to examine the analogy between DNNs (trained with datasets including MNIST and CIFAR10) and spin glass. Specifically, we used (1) random walk in the parameter space of DNNs to unravel the structures in their loss landscape; (2) a permutation-interpolation protocol to study the connection between copies of identical regions in the loss landscape due to the permutation symmetry in the hidden layers; (3) hierarchical clustering to reveal the hierarchy among trained solutions of DNNs, reminiscent of the so-called Replica Symmetry Breaking (RSB) phenomenon (i.e. the Parisi solution) in analogy to spin glass; (4) finally, we examine the relationship between the degree of the ruggedness of the loss landscape of the DNN and its generalizability, showing an improvement of flattened minima.
Re-Search for The Truth: Multi-round Retrieval-augmented Large Language Models are Strong Fake News Detectors
Mar 14, 2024
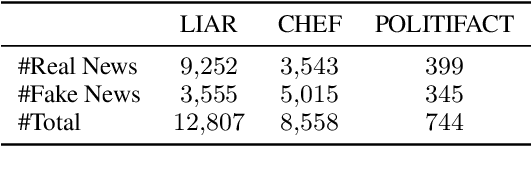
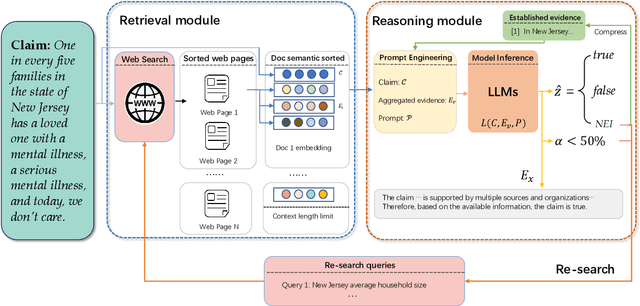
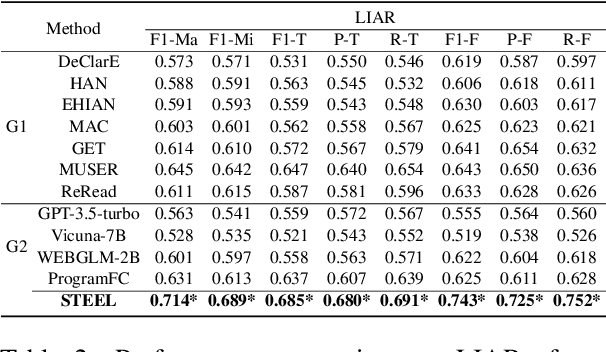
The proliferation of fake news has had far-reaching implications on politics, the economy, and society at large. While Fake news detection methods have been employed to mitigate this issue, they primarily depend on two essential elements: the quality and relevance of the evidence, and the effectiveness of the verdict prediction mechanism. Traditional methods, which often source information from static repositories like Wikipedia, are limited by outdated or incomplete data, particularly for emerging or rare claims. Large Language Models (LLMs), known for their remarkable reasoning and generative capabilities, introduce a new frontier for fake news detection. However, like traditional methods, LLM-based solutions also grapple with the limitations of stale and long-tail knowledge. Additionally, retrieval-enhanced LLMs frequently struggle with issues such as low-quality evidence retrieval and context length constraints. To address these challenges, we introduce a novel, retrieval-augmented LLMs framework--the first of its kind to automatically and strategically extract key evidence from web sources for claim verification. Employing a multi-round retrieval strategy, our framework ensures the acquisition of sufficient, relevant evidence, thereby enhancing performance. Comprehensive experiments across three real-world datasets validate the framework's superiority over existing methods. Importantly, our model not only delivers accurate verdicts but also offers human-readable explanations to improve result interpretability.
Aligning Large Language Models for Controllable Recommendations
Mar 08, 2024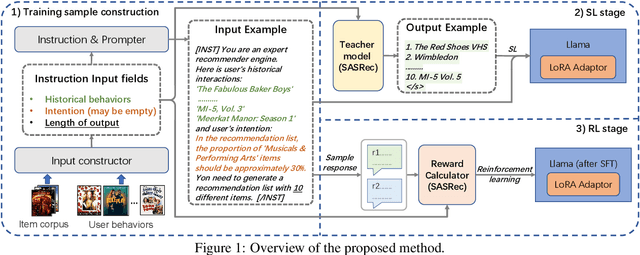
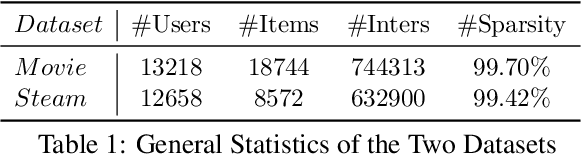
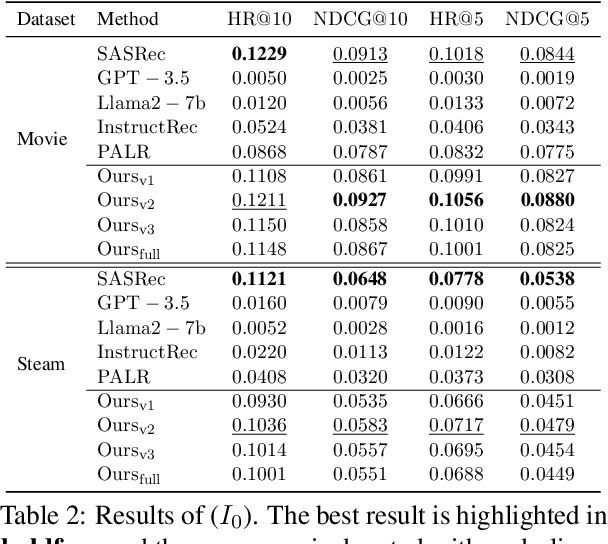
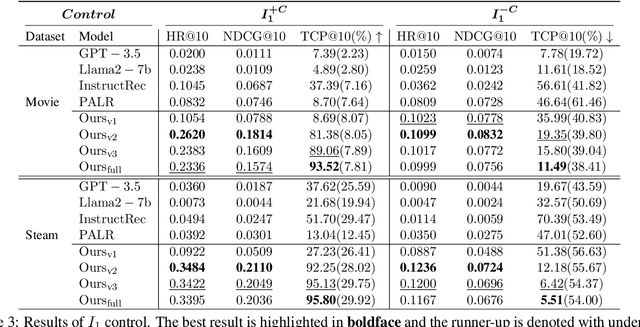
Inspired by the exceptional general intelligence of Large Language Models (LLMs), researchers have begun to explore their application in pioneering the next generation of recommender systems - systems that are conversational, explainable, and controllable. However, existing literature primarily concentrates on integrating domain-specific knowledge into LLMs to enhance accuracy, often neglecting the ability to follow instructions. To address this gap, we initially introduce a collection of supervised learning tasks, augmented with labels derived from a conventional recommender model, aimed at explicitly improving LLMs' proficiency in adhering to recommendation-specific instructions. Subsequently, we develop a reinforcement learning-based alignment procedure to further strengthen LLMs' aptitude in responding to users' intentions and mitigating formatting errors. Through extensive experiments on two real-world datasets, our method markedly advances the capability of LLMs to comply with instructions within recommender systems, while sustaining a high level of accuracy performance.
Resisting Graph Adversarial Attack via Cooperative Homophilous Augmentation
Nov 15, 2022



Recent studies show that Graph Neural Networks(GNNs) are vulnerable and easily fooled by small perturbations, which has raised considerable concerns for adapting GNNs in various safety-critical applications. In this work, we focus on the emerging but critical attack, namely, Graph Injection Attack(GIA), in which the adversary poisons the graph by injecting fake nodes instead of modifying existing structures or node attributes. Inspired by findings that the adversarial attacks are related to the increased heterophily on perturbed graphs (the adversary tends to connect dissimilar nodes), we propose a general defense framework CHAGNN against GIA through cooperative homophilous augmentation of graph data and model. Specifically, the model generates pseudo-labels for unlabeled nodes in each round of training to reduce heterophilous edges of nodes with distinct labels. The cleaner graph is fed back to the model, producing more informative pseudo-labels. In such an iterative manner, model robustness is then promisingly enhanced. We present the theoretical analysis of the effect of homophilous augmentation and provide the guarantee of the proposal's validity. Experimental results empirically demonstrate the effectiveness of CHAGNN in comparison with recent state-of-the-art defense methods on diverse real-world datasets.
Addressing Time Bias in Bipartite Graph Ranking for Important Node Identification
Nov 28, 2019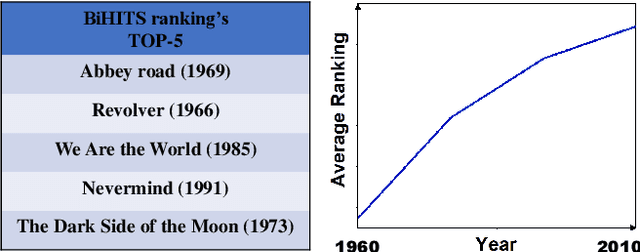

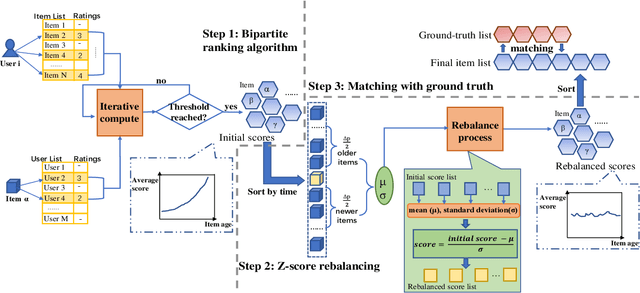
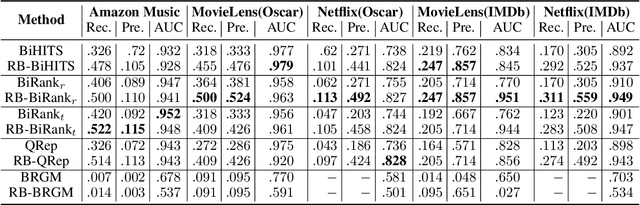
The goal of the ranking problem in networks is to rank nodes from best to worst, according to a chosen criterion. In this work, we focus on ranking the nodes according to their quality. The problem of ranking the nodes in bipartite networks is valuable for many real-world applications. For instance, high-quality products can be promoted on an online shop or highly reputed restaurants attract more people on venues review platforms. However, many classical ranking algorithms share a common drawback: they tend to rank older movies higher than newer movies, though some newer movies may have a high quality. This time bias originates from the fact that older nodes in a network tend to have more connections than newer ones. In the study, we develop a ranking method using a rebalance approach to diminish the time bias of the rankings in bipartite graphs.
Predicting missing links via correlation between nodes
Sep 30, 2014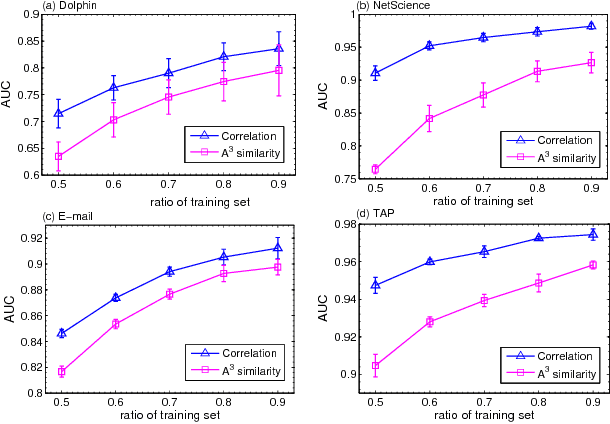
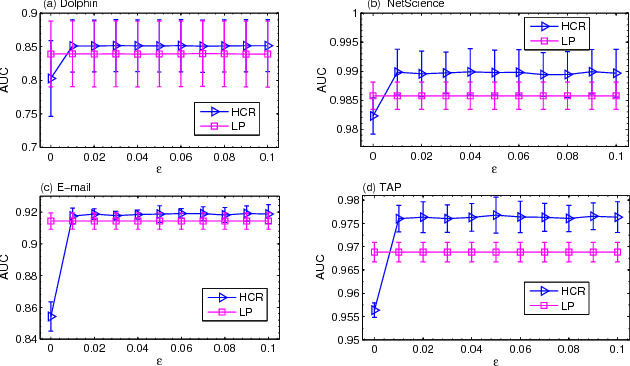
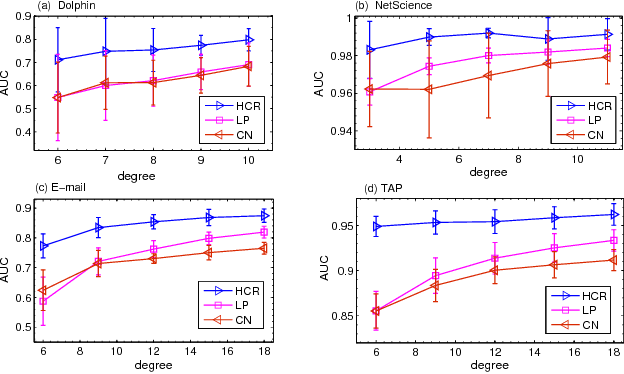
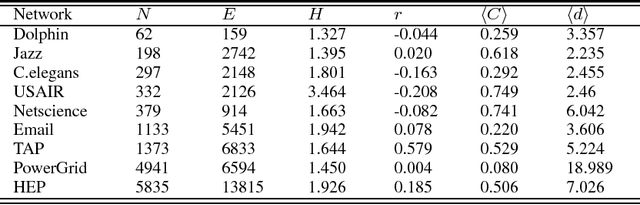
As a fundamental problem in many different fields, link prediction aims to estimate the likelihood of an existing link between two nodes based on the observed information. Since this problem is related to many applications ranging from uncovering missing data to predicting the evolution of networks, link prediction has been intensively investigated recently and many methods have been proposed so far. The essential challenge of link prediction is to estimate the similarity between nodes. Most of the existing methods are based on the common neighbor index and its variants. In this paper, we propose to calculate the similarity between nodes by the correlation coefficient. This method is found to be very effective when applied to calculate similarity based on high order paths. We finally fuse the correlation-based method with the resource allocation method, and find that the combined method can substantially outperform the existing methods, especially in sparse networks.