 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models for spreading dynamics in complex systems
Feb 08, 2026Spreading dynamics is a central topic in the physics of complex systems and network science, providing a unified framework for understanding how information, behaviors, and diseases propagate through interactions among system units. In many propagation contexts, spreading processes are influenced by multiple interacting factors, such as information expression patterns, cultural contexts, living environments, cognitive preferences, and public policies, which are difficult to incorporate directly into classical modeling frameworks. Recently, large language models (LLMs) have exhibited strong capabilities in natural language understanding, reasoning, and generation, enabling explicit perception of semantic content and contextual cues in spreading processes, thereby supporting the analysis of the different influencing factors. Beyond serving as external analytical tools, LLMs can also act as interactive agents embedded in propagation systems, potentially influencing spreading pathways and feedback structures. Consequently, the roles and impacts of LLMs on spreading dynamics have become an active and rapidly growing research area across multiple research disciplines. This review provides a comprehensive overview of recent advances in applying LLMs to the study of spreading dynamics across two representative domains: digital epidemics, such as misinformation and rumors, and biological epidemics, including infectious disease outbreaks. We first examine the foundations of epidemic modeling from a complex-systems perspective and discuss how LLM-based approaches relate to traditional frameworks. We then systematically review recent studies from three key perspectives, which are epidemic modeling, epidemic detection and surveillance, and epidemic prediction and management, to clarify how LLMs enhance these areas. Finally, open challenges and potential research directions are discussed.
Network Alignment
Apr 15, 2025Complex networks are frequently employed to model physical or virtual complex systems. When certain entities exist across multiple systems simultaneously, unveiling their corresponding relationships across the networks becomes crucial. This problem, known as network alignment, holds significant importance. It enhances our understanding of complex system structures and behaviours, facilitates the validation and extension of theoretical physics research about studying complex systems, and fosters diverse practical applications across various fields. However, due to variations in the structure, characteristics, and properties of complex networks across different fields, the study of network alignment is often isolated within each domain, with even the terminologies and concepts lacking uniformity. This review comprehensively summarizes the latest advancements in network alignment research, focusing on analyzing network alignment characteristics and progress in various domains such as social network analysis, bioinformatics, computational linguistics and privacy protection. It provides a detailed analysis of various methods' implementation principles, processes, and performance differences, including structure consistency-based methods, network embedding-based methods, and graph neural network-based (GNN-based) methods. Additionally, the methods for network alignment under different conditions, such as in attributed networks, heterogeneous networks, directed networks, and dynamic networks, are presented. Furthermore, the challenges and the open issues for future studies are also discussed.
Learning from the past: predicting critical transitions with machine learning trained on surrogates of historical data
Oct 13, 2024
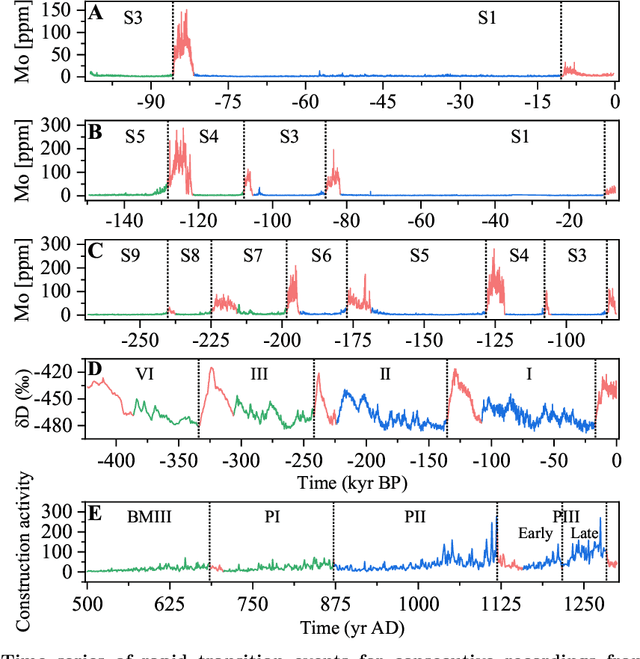


Complex systems can undergo critical transitions, where slowly changing environmental conditions trigger a sudden shift to a new, potentially catastrophic state. Early warning signals for these events are crucial for decision-making in fields such as ecology, biology and climate science. Generic early warning signals motivated by dynamical systems theory have had mixed success on real noisy data. More recent studies found that deep learning classifiers trained on synthetic data could improve performance. However, neither of these methods take advantage of historical, system-specific data. Here, we introduce an approach that trains machine learning classifiers directly on surrogate data of past transitions, namely surrogate data-based machine learning (SDML). The approach provides early warning signals in empirical and experimental data from geology, climatology, sociology, and cardiology with higher sensitivity and specificity than two widely used generic early warning signals -- variance and lag-1 autocorrelation. Since the approach is trained directly on surrogates of historical data, it is not bound by the restricting assumption of a local bifurcation like previous methods. This system-specific approach can contribute to improved early warning signals to help humans better prepare for or avoid undesirable critical transitions.
A Fast Maximum Clique Algorithm Based on Network Decomposition for Large Sparse Networks
Apr 19, 2024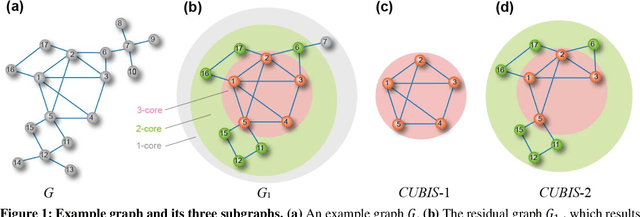
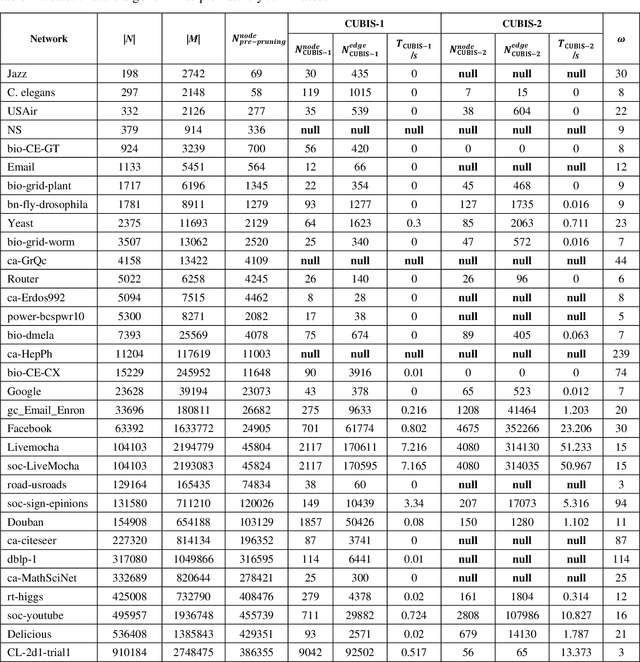
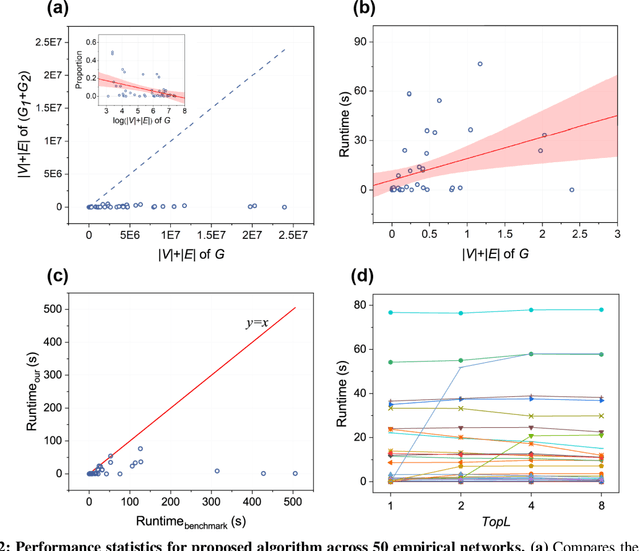
Finding maximum cliques in large networks is a challenging combinatorial problem with many real-world applications. We present a fast algorithm to achieve the exact solution for the maximum clique problem in large sparse networks based on efficient graph decomposition. A bunch of effective techniques is being used to greatly prune the graph and a novel concept called Complete-Upper-Bound-Induced Subgraph (CUBIS) is proposed to ensure that the structures with the potential to form the maximum clique are retained in the process of graph decomposition. Our algorithm first pre-prunes peripheral nodes, subsequently, one or two small-scale CUBISs are constructed guided by the core number and current maximum clique size. Bron-Kerbosch search is performed on each CUBIS to find the maximum clique. Experiments on 50 empirical networks with a scale of up to 20 million show the CUBIS scales are largely independent of the original network scale. This enables an approximately linear runtime, making our algorithm amenable for large networks. Our work provides a new framework for effectively solving maximum clique problems on massive sparse graphs, which not only makes the graph scale no longer the bottleneck but also shows some light on solving other clique-related problems.
Predicting missing links via correlation between nodes
Sep 30, 2014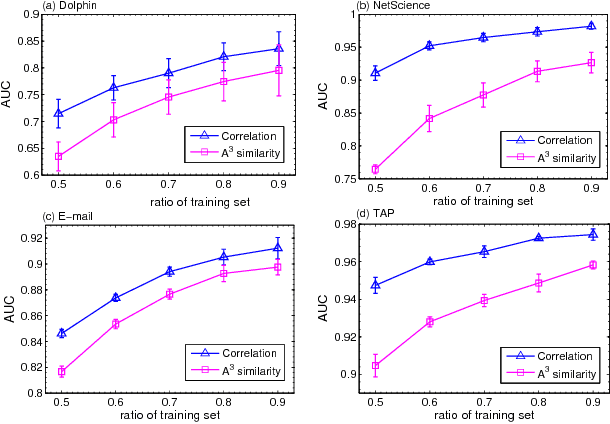
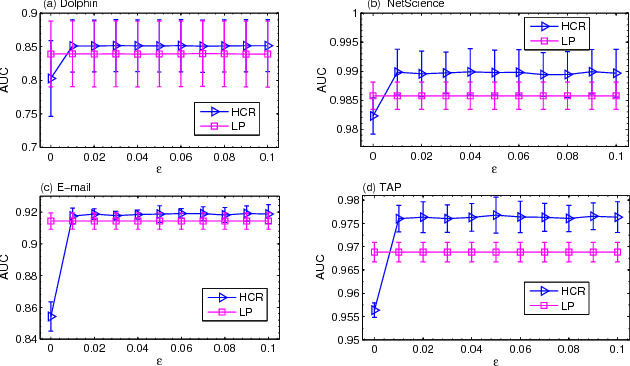
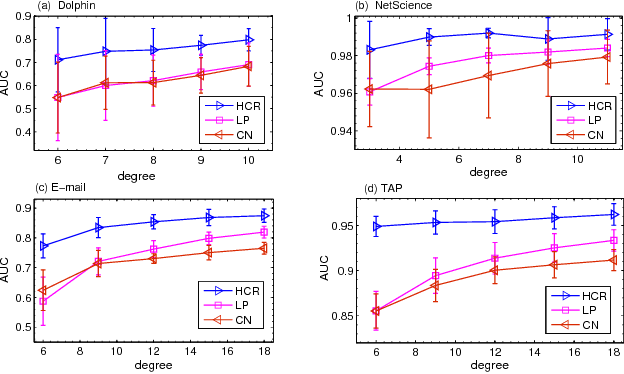
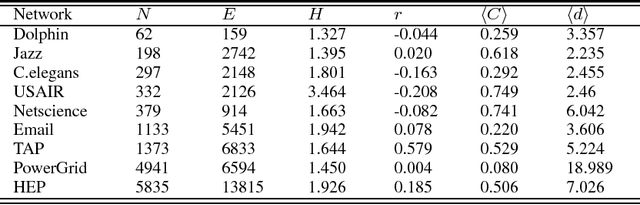
As a fundamental problem in many different fields, link prediction aims to estimate the likelihood of an existing link between two nodes based on the observed information. Since this problem is related to many applications ranging from uncovering missing data to predicting the evolution of networks, link prediction has been intensively investigated recently and many methods have been proposed so far. The essential challenge of link prediction is to estimate the similarity between nodes. Most of the existing methods are based on the common neighbor index and its variants. In this paper, we propose to calculate the similarity between nodes by the correlation coefficient. This method is found to be very effective when applied to calculate similarity based on high order paths. We finally fuse the correlation-based method with the resource allocation method, and find that the combined method can substantially outperform the existing methods, especially in sparse networks.