 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoCFNet: Geometry-Aware Confidence Field Network for Robot-Assisted Endoscopic Submucosal Dissection
Jun 11, 2026Advanced surgical robotics has made robot-assisted endoscopic submucosal dissection (ESD) a promising approach for the en-bloc resection of large lesions, with the potential to reduce recurrence and improve long-term outcomes. However, the technical complexity and risk of complications in ESD demand stable and precise visual guidance to maintain an accurate dissection corridor and a safe tissue margin. Dense confidence fields provide an effective representation for this purpose by describing both the preferred dissection region and its spatial transition to surrounding tissue. However, reliable confidence field estimation remains challenging in dynamic endoscopic scenes due to smoke, specular highlights, tissue deformation, weak texture, and the thin geometric structure of the target region. To address these challenges, we formulate dissection guidance as a geometry-aware confidence field estimation problem and propose GeoCFNet, a geometry-aware confidence field network built on a pretrained DINOv3 backbone. GeoCFNet integrates a Token-Differentiated Fusion module to aggregate class-token context with dense patch representations, a SegFormer decoder for confidence regression, and Geometry-Aware Spatial Regularization (GASR) to preserve spatial coherence and local geometric transitions. Experimental results show that GeoCFNet achieves RMSE 0.0480, PSNR 27.1995, SSIM 0.3397, and CC 0.2466, indicating accurate and geometrically stable confidence field estimation for robot-assisted ESD guidance.
Rein3D: Reinforced 3D Indoor Scene Generation with Panoramic Video Diffusion Models
Apr 14, 2026The growing demand for Embodied AI and VR applications has highlighted the need for synthesizing high-quality 3D indoor scenes from sparse inputs. However, existing approaches struggle to infer massive amounts of missing geometry in large unseen areas while maintaining global consistency, often producing locally plausible but globally inconsistent reconstructions. We present Rein3D, a framework that reconstructs full 360-degree indoor environments by coupling explicit 3D Gaussian Splatting (3DGS) with temporally coherent priors from video diffusion models. Our approach follows a "restore-and-refine" paradigm: we employ a radial exploration strategy to render imperfect panoramic videos along trajectories starting from the origin, effectively uncovering occluded regions from a coarse 3DGS initialization. These sequences are restored by a panoramic video-to-video diffusion model and further enhanced via video super-resolution to synthesize high-fidelity geometry and textures. Finally, these refined videos serve as pseudo-ground truths to update the global 3D Gaussian field. To support this task, we construct PanoV2V-15K, a dataset of over 15K paired clean and degraded panoramic videos for diffusion-based scene restoration. Experiments demonstrate that Rein3D produces photorealistic and globally consistent 3D scenes and significantly improves long-range camera exploration compared with existing baselines.
SpatiaLQA: A Benchmark for Evaluating Spatial Logical Reasoning in Vision-Language Models
Feb 24, 2026Vision-Language Models (VLMs) have been increasingly applied in real-world scenarios due to their outstanding understanding and reasoning capabilities. Although VLMs have already demonstrated impressive capabilities in common visual question answering and logical reasoning, they still lack the ability to make reasonable decisions in complex real-world environments. We define this ability as spatial logical reasoning, which not only requires understanding the spatial relationships among objects in complex scenes, but also the logical dependencies between steps in multi-step tasks. To bridge this gap, we introduce Spatial Logical Question Answering (SpatiaLQA), a benchmark designed to evaluate the spatial logical reasoning capabilities of VLMs. SpatiaLQA consists of 9,605 question answer pairs derived from 241 real-world indoor scenes. We conduct extensive experiments on 41 mainstream VLMs, and the results show that even the most advanced models still struggle with spatial logical reasoning. To address this issue, we propose a method called recursive scene graph assisted reasoning, which leverages visual foundation models to progressively decompose complex scenes into task-relevant scene graphs, thereby enhancing the spatial logical reasoning ability of VLMs, outperforming all previous methods. Code and dataset are available at https://github.com/xieyc99/SpatiaLQA.
Large language models for spreading dynamics in complex systems
Feb 08, 2026Spreading dynamics is a central topic in the physics of complex systems and network science, providing a unified framework for understanding how information, behaviors, and diseases propagate through interactions among system units. In many propagation contexts, spreading processes are influenced by multiple interacting factors, such as information expression patterns, cultural contexts, living environments, cognitive preferences, and public policies, which are difficult to incorporate directly into classical modeling frameworks. Recently, large language models (LLMs) have exhibited strong capabilities in natural language understanding, reasoning, and generation, enabling explicit perception of semantic content and contextual cues in spreading processes, thereby supporting the analysis of the different influencing factors. Beyond serving as external analytical tools, LLMs can also act as interactive agents embedded in propagation systems, potentially influencing spreading pathways and feedback structures. Consequently, the roles and impacts of LLMs on spreading dynamics have become an active and rapidly growing research area across multiple research disciplines. This review provides a comprehensive overview of recent advances in applying LLMs to the study of spreading dynamics across two representative domains: digital epidemics, such as misinformation and rumors, and biological epidemics, including infectious disease outbreaks. We first examine the foundations of epidemic modeling from a complex-systems perspective and discuss how LLM-based approaches relate to traditional frameworks. We then systematically review recent studies from three key perspectives, which are epidemic modeling, epidemic detection and surveillance, and epidemic prediction and management, to clarify how LLMs enhance these areas. Finally, open challenges and potential research directions are discussed.
GeoLanG: Geometry-Aware Language-Guided Grasping with Unified RGB-D Multimodal Learning
Feb 04, 2026Language-guided grasping has emerged as a promising paradigm for enabling robots to identify and manipulate target objects through natural language instructions, yet it remains highly challenging in cluttered or occluded scenes. Existing methods often rely on multi-stage pipelines that separate object perception and grasping, which leads to limited cross-modal fusion, redundant computation, and poor generalization in cluttered, occluded, or low-texture scenes. To address these limitations, we propose GeoLanG, an end-to-end multi-task framework built upon the CLIP architecture that unifies visual and linguistic inputs into a shared representation space for robust semantic alignment and improved generalization. To enhance target discrimination under occlusion and low-texture conditions, we explore a more effective use of depth information through the Depth-guided Geometric Module (DGGM), which converts depth into explicit geometric priors and injects them into the attention mechanism without additional computational overhead. In addition, we propose Adaptive Dense Channel Integration, which adaptively balances the contributions of multi-layer features to produce more discriminative and generalizable visual representations. Extensive experiments on the OCID-VLG dataset, as well as in both simulation and real-world hardware, demonstrate that GeoLanG enables precise and robust language-guided grasping in complex, cluttered environments, paving the way toward more reliable multimodal robotic manipulation in real-world human-centric settings.
BaseCal: Unsupervised Confidence Calibration via Base Model Signals
Jan 08, 2026Reliable confidence is essential for trusting the outputs of LLMs, yet widely deployed post-trained LLMs (PoLLMs) typically compromise this trust with severe overconfidence. In contrast, we observe that their corresponding base LLMs often remain well-calibrated. This naturally motivates us to calibrate PoLLM confidence using the base LLM as a reference. This work proposes two ways to achieve this. A straightforward solution, BaseCal-ReEval, evaluates PoLLM's responses by feeding them into the base LLM to get average probabilities as confidence. While effective, this approach introduces additional inference overhead. To address this, we propose BaseCal-Proj, which trains a lightweight projection to map the final-layer hidden states of PoLLMs back to those of their base LLMs. These projected states are then processed by the base LLM's output layer to derive base-calibrated confidence for PoLLM's responses. Notably, BaseCal is an unsupervised, plug-and-play solution that operates without human labels or LLM modifications. Experiments across five datasets and three LLM families demonstrate the effectiveness of BaseCal, reducing Expected Calibration Error (ECE) by an average of 42.90\% compared to the best unsupervised baselines.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025
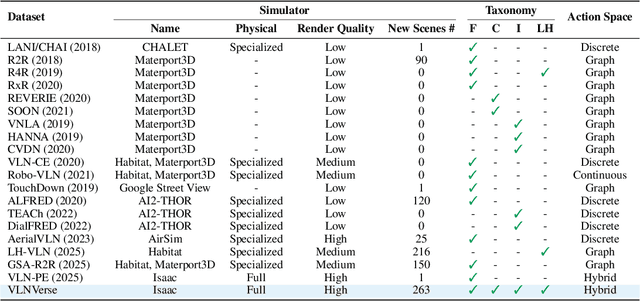
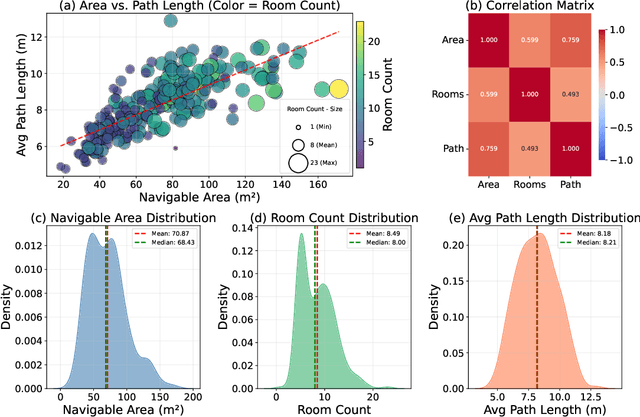

Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
Beyond Monotonicity: Revisiting Factorization Principles in Multi-Agent Q-Learning
Nov 12, 2025Value decomposition is a central approach in multi-agent reinforcement learning (MARL), enabling centralized training with decentralized execution by factorizing the global value function into local values. To ensure individual-global-max (IGM) consistency, existing methods either enforce monotonicity constraints, which limit expressive power, or adopt softer surrogates at the cost of algorithmic complexity. In this work, we present a dynamical systems analysis of non-monotonic value decomposition, modeling learning dynamics as continuous-time gradient flow. We prove that, under approximately greedy exploration, all zero-loss equilibria violating IGM consistency are unstable saddle points, while only IGM-consistent solutions are stable attractors of the learning dynamics. Extensive experiments on both synthetic matrix games and challenging MARL benchmarks demonstrate that unconstrained, non-monotonic factorization reliably recovers IGM-optimal solutions and consistently outperforms monotonic baselines. Additionally, we investigate the influence of temporal-difference targets and exploration strategies, providing actionable insights for the design of future value-based MARL algorithms.
Fine-tuning Done Right in Model Editing
Sep 26, 2025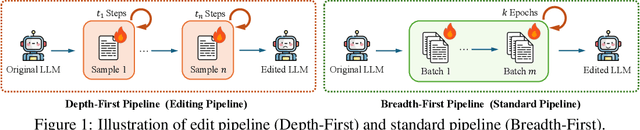
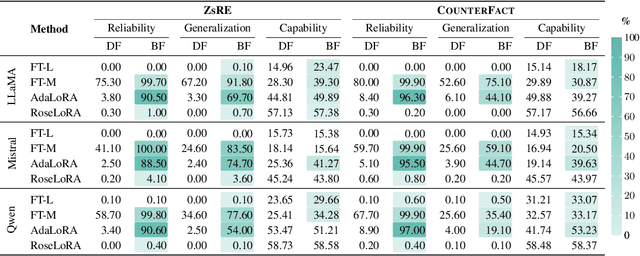
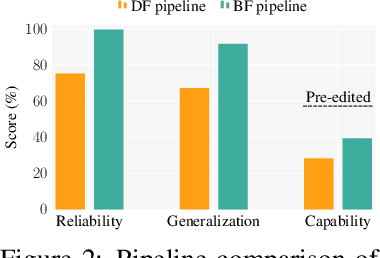

Fine-tuning, a foundational method for adapting large language models, has long been considered ineffective for model editing. Here, we challenge this belief, arguing that the reported failure arises not from the inherent limitation of fine-tuning itself, but from adapting it to the sequential nature of the editing task, a single-pass depth-first pipeline that optimizes each sample to convergence before moving on. While intuitive, this depth-first pipeline coupled with sample-wise updating over-optimizes each edit and induces interference across edits. Our controlled experiments reveal that simply restoring fine-tuning to the standard breadth-first (i.e., epoch-based) pipeline with mini-batch optimization substantially improves its effectiveness for model editing. Moreover, fine-tuning in editing also suffers from suboptimal tuning parameter locations inherited from prior methods. Through systematic analysis of tuning locations, we derive LocFT-BF, a simple and effective localized editing method built on the restored fine-tuning framework. Extensive experiments across diverse LLMs and datasets demonstrate that LocFT-BF outperforms state-of-the-art methods by large margins. Notably, to our knowledge, it is the first to sustain 100K edits and 72B-parameter models,10 x beyond prior practice, without sacrificing general capabilities. By clarifying a long-standing misconception and introducing a principled localized tuning strategy, we advance fine-tuning from an underestimated baseline to a leading method for model editing, establishing a solid foundation for future research.
SPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025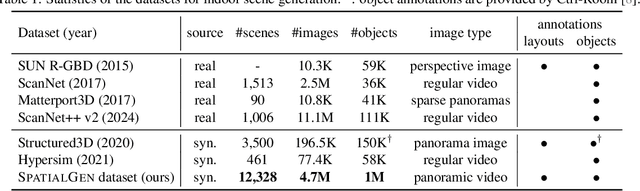
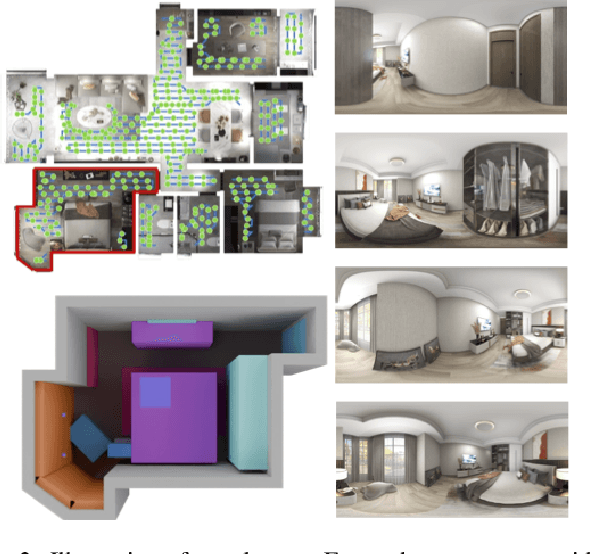
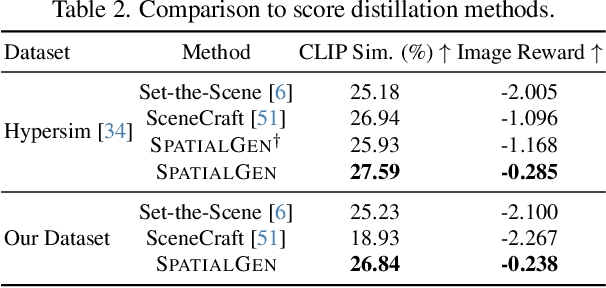
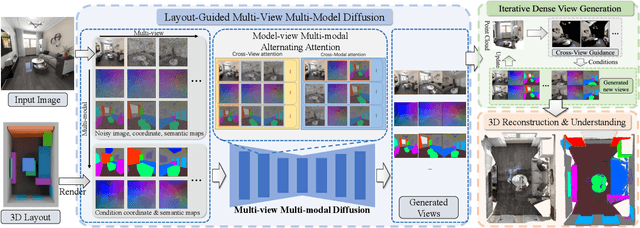
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.