 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR-ESI: Feature Adaptive Importance Refinement for Electrophysiological Source Imaging
Jan 22, 2026An essential technique for diagnosing brain disorders is electrophysiological source imaging (ESI). While model-based optimization and deep learning methods have achieved promising results in this field, the accurate selection and refinement of features remains a central challenge for precise ESI. This paper proposes FAIR-ESI, a novel framework that adaptively refines feature importance across different views, including FFT-based spectral feature refinement, weighted temporal feature refinement, and self-attention-based patch-wise feature refinement. Extensive experiments on two simulation datasets with diverse configurations and two real-world clinical datasets validate our framework's efficacy, highlighting its potential to advance brain disorder diagnosis and offer new insights into brain function.
BaseCal: Unsupervised Confidence Calibration via Base Model Signals
Jan 08, 2026Reliable confidence is essential for trusting the outputs of LLMs, yet widely deployed post-trained LLMs (PoLLMs) typically compromise this trust with severe overconfidence. In contrast, we observe that their corresponding base LLMs often remain well-calibrated. This naturally motivates us to calibrate PoLLM confidence using the base LLM as a reference. This work proposes two ways to achieve this. A straightforward solution, BaseCal-ReEval, evaluates PoLLM's responses by feeding them into the base LLM to get average probabilities as confidence. While effective, this approach introduces additional inference overhead. To address this, we propose BaseCal-Proj, which trains a lightweight projection to map the final-layer hidden states of PoLLMs back to those of their base LLMs. These projected states are then processed by the base LLM's output layer to derive base-calibrated confidence for PoLLM's responses. Notably, BaseCal is an unsupervised, plug-and-play solution that operates without human labels or LLM modifications. Experiments across five datasets and three LLM families demonstrate the effectiveness of BaseCal, reducing Expected Calibration Error (ECE) by an average of 42.90\% compared to the best unsupervised baselines.
Fine-tuning Done Right in Model Editing
Sep 26, 2025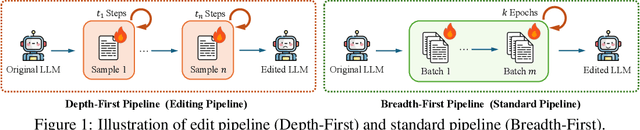
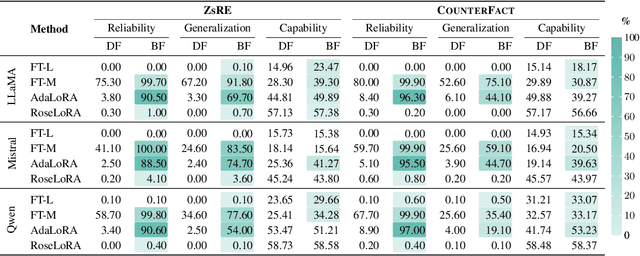
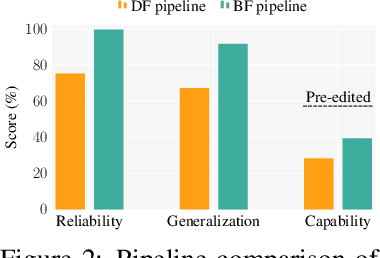

Fine-tuning, a foundational method for adapting large language models, has long been considered ineffective for model editing. Here, we challenge this belief, arguing that the reported failure arises not from the inherent limitation of fine-tuning itself, but from adapting it to the sequential nature of the editing task, a single-pass depth-first pipeline that optimizes each sample to convergence before moving on. While intuitive, this depth-first pipeline coupled with sample-wise updating over-optimizes each edit and induces interference across edits. Our controlled experiments reveal that simply restoring fine-tuning to the standard breadth-first (i.e., epoch-based) pipeline with mini-batch optimization substantially improves its effectiveness for model editing. Moreover, fine-tuning in editing also suffers from suboptimal tuning parameter locations inherited from prior methods. Through systematic analysis of tuning locations, we derive LocFT-BF, a simple and effective localized editing method built on the restored fine-tuning framework. Extensive experiments across diverse LLMs and datasets demonstrate that LocFT-BF outperforms state-of-the-art methods by large margins. Notably, to our knowledge, it is the first to sustain 100K edits and 72B-parameter models,10 x beyond prior practice, without sacrificing general capabilities. By clarifying a long-standing misconception and introducing a principled localized tuning strategy, we advance fine-tuning from an underestimated baseline to a leading method for model editing, establishing a solid foundation for future research.
IEFS-GMB: Gradient Memory Bank-Guided Feature Selection Based on Information Entropy for EEG Classification of Neurological Disorders
Sep 18, 2025Deep learning-based EEG classification is crucial for the automated detection of neurological disorders, improving diagnostic accuracy and enabling early intervention. However, the low signal-to-noise ratio of EEG signals limits model performance, making feature selection (FS) vital for optimizing representations learned by neural network encoders. Existing FS methods are seldom designed specifically for EEG diagnosis; many are architecture-dependent and lack interpretability, limiting their applicability. Moreover, most rely on single-iteration data, resulting in limited robustness to variability. To address these issues, we propose IEFS-GMB, an Information Entropy-based Feature Selection method guided by a Gradient Memory Bank. This approach constructs a dynamic memory bank storing historical gradients, computes feature importance via information entropy, and applies entropy-based weighting to select informative EEG features. Experiments on four public neurological disease datasets show that encoders enhanced with IEFS-GMB achieve accuracy improvements of 0.64% to 6.45% over baseline models. The method also outperforms four competing FS techniques and improves model interpretability, supporting its practical use in clinical settings.
LV-CadeNet: Long View Feature Convolution-Attention Fusion Encoder-Decoder Network for Clinical MEG Spike Detection
Dec 12, 2024



It is widely acknowledged that the epileptic foci can be pinpointed by source localizing interictal epileptic discharges (IEDs) via Magnetoencephalography (MEG). However, manual detection of IEDs, which appear as spikes in MEG data, is extremely labor intensive and requires considerable professional expertise, limiting the broader adoption of MEG technology. Numerous studies have focused on automatic detection of MEG spikes to overcome this challenge, but these efforts often validate their models on synthetic datasets with balanced positive and negative samples. In contrast, clinical MEG data is highly imbalanced, raising doubts on the real-world efficacy of these models. To address this issue, we introduce LV-CadeNet, a Long View feature Convolution-Attention fusion Encoder-Decoder Network, designed for automatic MEG spike detection in real-world clinical scenarios. Beyond addressing the disparity between training data distribution and clinical test data through semi-supervised learning, our approach also mimics human specialists by constructing long view morphological input data. Moreover, we propose an advanced convolution-attention module to extract temporal and spatial features from the input data. LV-CadeNet significantly improves the accuracy of MEG spike detection, boosting it from 42.31\% to 54.88\% on a novel clinical dataset sourced from Sanbo Brain Hospital Capital Medical University. This dataset, characterized by a highly imbalanced distribution of positive and negative samples, accurately represents real-world clinical scenarios.
The Fall of ROME: Understanding the Collapse of LLMs in Model Editing
Jun 17, 2024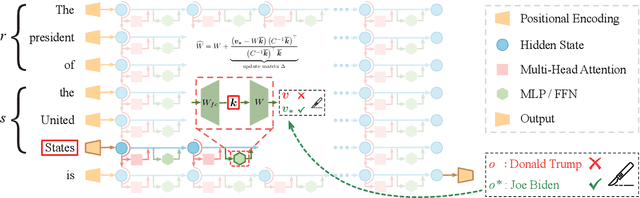
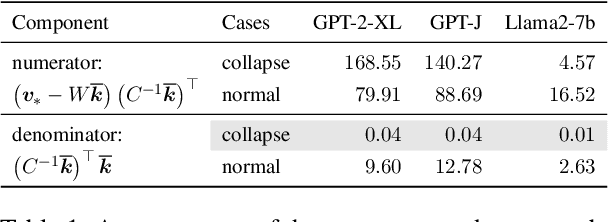
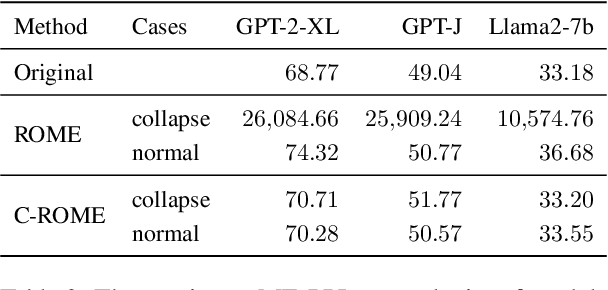
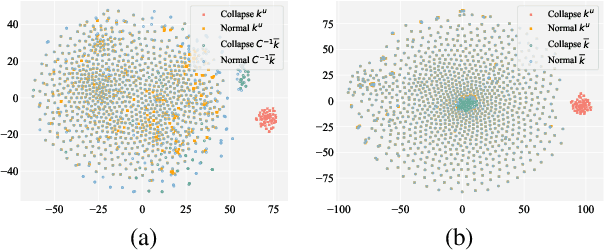
Despite significant progress in model editing methods, their application in real-world scenarios remains challenging as they often cause large language models (LLMs) to collapse. Among them, ROME is particularly concerning, as it could disrupt LLMs with only a single edit. In this paper, we study the root causes of such collapse. Through extensive analysis, we identify two primary factors that contribute to the collapse: i) inconsistent handling of prefixed and unprefixed keys in the parameter update equation may result in very small denominators, causing excessively large parameter updates; ii) the subject of collapse cases is usually the first token, whose unprefixed key distribution significantly differs from the prefixed key distribution in autoregressive transformers, causing the aforementioned issue to materialize. To validate our analysis, we propose a simple yet effective approach: uniformly using prefixed keys during editing phase and adding prefixes during the testing phase. The experimental results show that the proposed solution can prevent model collapse while maintaining the effectiveness of the edits.
The Butterfly Effect of Model Editing: Few Edits Can Trigger Large Language Models Collapse
Feb 18, 2024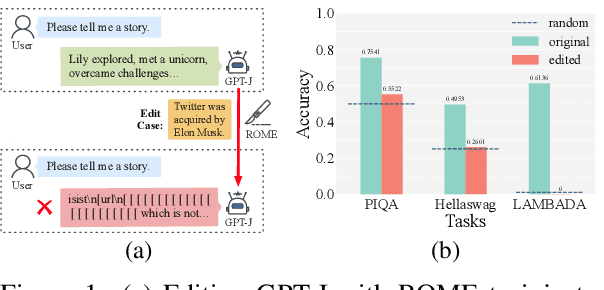
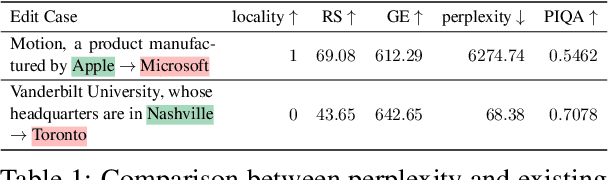
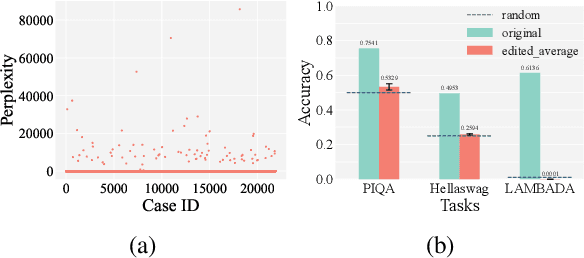

Although model editing has shown promise in revising knowledge in Large Language Models (LLMs), its impact on the inherent capabilities of LLMs is often overlooked. In this work, we reveal a critical phenomenon: even a single edit can trigger model collapse, manifesting as significant performance degradation in various benchmark tasks. However, benchmarking LLMs after each edit, while necessary to prevent such collapses, is impractically time-consuming and resource-intensive. To mitigate this, we propose using perplexity as a surrogate metric, validated by extensive experiments demonstrating its strong correlation with downstream tasks performance. We further conduct an in-depth study on sequential editing, a practical setting for real-world scenarios, across various editing methods and LLMs, focusing on hard cases from our previous single edit studies. The results indicate that nearly all examined editing methods result in model collapse after only few edits. To facilitate further research, we have utilized GPT-3.5 to develop a new dataset, HardEdit, based on those hard cases. This dataset aims to establish the foundation for pioneering research in reliable model editing and the mechanisms underlying editing-induced model collapse. We hope this work can draw the community's attention to the potential risks inherent in model editing practices.
Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts for Open-Domain QA?
Jan 22, 2024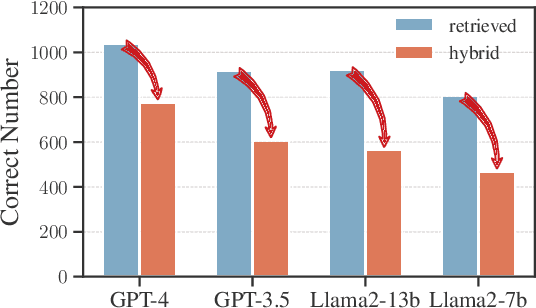
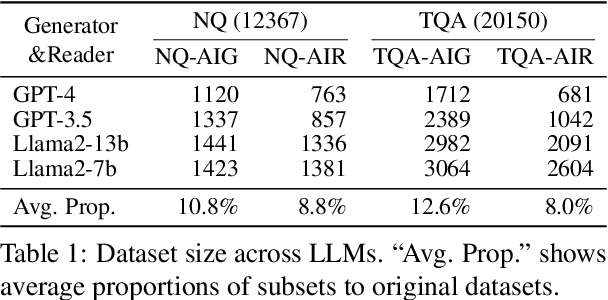
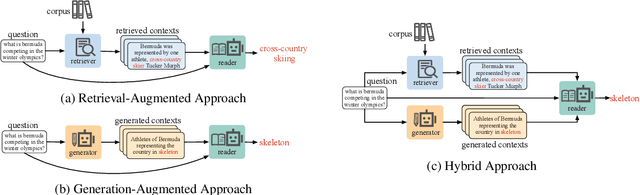
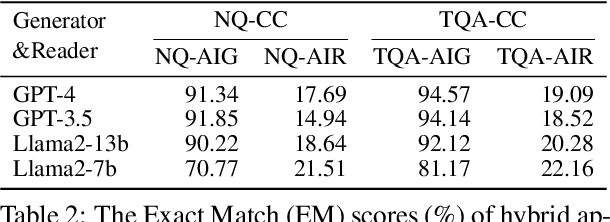
While auxiliary information has become a key to enhance Large Language Models (LLMs), relatively little is known about how well LLMs merge these contexts, specifically generated and retrieved. To study this, we formulate a task specifically designed to identify whether the answers, derived from the integration of generated and retrieved contexts, are attributed to either generated or retrieved contexts. To support this task, we develop a methodology to construct datasets with conflicting contexts, where each question is paired with both generated and retrieved contexts, yet only one of them contains the correct answer. Our experiments reveal a significant bias in LLMs towards generated contexts, as evidenced across state-of-the-art open (Llama2-7b/13b) and closed (GPT 3.5/4) systems. We further identify two key factors contributing to this bias: i) Contexts generated by LLMs typically show greater similarity to the questions, increasing their likelihood of selection; ii) The segmentation process used in retrieved contexts disrupts their completeness, thereby hindering their full utilization in LLMs. Our analysis enhances the understanding of how LLMs merge diverse contexts, offering valuable insights for advancing current augmentation methods for LLMs.