 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR-ESI: Feature Adaptive Importance Refinement for Electrophysiological Source Imaging
Jan 22, 2026An essential technique for diagnosing brain disorders is electrophysiological source imaging (ESI). While model-based optimization and deep learning methods have achieved promising results in this field, the accurate selection and refinement of features remains a central challenge for precise ESI. This paper proposes FAIR-ESI, a novel framework that adaptively refines feature importance across different views, including FFT-based spectral feature refinement, weighted temporal feature refinement, and self-attention-based patch-wise feature refinement. Extensive experiments on two simulation datasets with diverse configurations and two real-world clinical datasets validate our framework's efficacy, highlighting its potential to advance brain disorder diagnosis and offer new insights into brain function.
IEFS-GMB: Gradient Memory Bank-Guided Feature Selection Based on Information Entropy for EEG Classification of Neurological Disorders
Sep 18, 2025Deep learning-based EEG classification is crucial for the automated detection of neurological disorders, improving diagnostic accuracy and enabling early intervention. However, the low signal-to-noise ratio of EEG signals limits model performance, making feature selection (FS) vital for optimizing representations learned by neural network encoders. Existing FS methods are seldom designed specifically for EEG diagnosis; many are architecture-dependent and lack interpretability, limiting their applicability. Moreover, most rely on single-iteration data, resulting in limited robustness to variability. To address these issues, we propose IEFS-GMB, an Information Entropy-based Feature Selection method guided by a Gradient Memory Bank. This approach constructs a dynamic memory bank storing historical gradients, computes feature importance via information entropy, and applies entropy-based weighting to select informative EEG features. Experiments on four public neurological disease datasets show that encoders enhanced with IEFS-GMB achieve accuracy improvements of 0.64% to 6.45% over baseline models. The method also outperforms four competing FS techniques and improves model interpretability, supporting its practical use in clinical settings.
LV-CadeNet: Long View Feature Convolution-Attention Fusion Encoder-Decoder Network for Clinical MEG Spike Detection
Dec 12, 2024



It is widely acknowledged that the epileptic foci can be pinpointed by source localizing interictal epileptic discharges (IEDs) via Magnetoencephalography (MEG). However, manual detection of IEDs, which appear as spikes in MEG data, is extremely labor intensive and requires considerable professional expertise, limiting the broader adoption of MEG technology. Numerous studies have focused on automatic detection of MEG spikes to overcome this challenge, but these efforts often validate their models on synthetic datasets with balanced positive and negative samples. In contrast, clinical MEG data is highly imbalanced, raising doubts on the real-world efficacy of these models. To address this issue, we introduce LV-CadeNet, a Long View feature Convolution-Attention fusion Encoder-Decoder Network, designed for automatic MEG spike detection in real-world clinical scenarios. Beyond addressing the disparity between training data distribution and clinical test data through semi-supervised learning, our approach also mimics human specialists by constructing long view morphological input data. Moreover, we propose an advanced convolution-attention module to extract temporal and spatial features from the input data. LV-CadeNet significantly improves the accuracy of MEG spike detection, boosting it from 42.31\% to 54.88\% on a novel clinical dataset sourced from Sanbo Brain Hospital Capital Medical University. This dataset, characterized by a highly imbalanced distribution of positive and negative samples, accurately represents real-world clinical scenarios.
Local Context Attention for Salient Object Segmentation
Sep 24, 2020


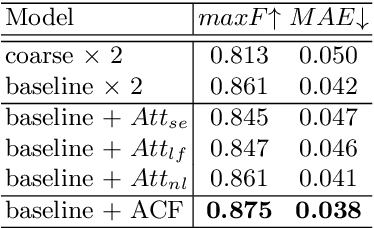
Salient object segmentation aims at distinguishing various salient objects from backgrounds. Despite the lack of semantic consistency, salient objects often have obvious texture and location characteristics in local area. Based on this priori, we propose a novel Local Context Attention Network (LCANet) to generate locally reinforcement feature maps in a uniform representational architecture. The proposed network introduces an Attentional Correlation Filter (ACF) module to generate explicit local attention by calculating the correlation feature map between coarse prediction and global context. Then it is expanded to a Local Context Block(LCB). Furthermore, an one-stage coarse-to-fine structure is implemented based on LCB to adaptively enhance the local context description ability. Comprehensive experiments are conducted on several salient object segmentation datasets, demonstrating the superior performance of the proposed LCANet against the state-of-the-art methods, especially with 0.883 max F-score and 0.034 MAE on DUTS-TE dataset.