 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealtime-VLA V2: Learning to Run VLAs Fast, Smooth, and Accurate
Mar 27, 2026In deployment of the VLA models to real-world robotic tasks, execution speed matters. In previous work arXiv:2510.26742 we analyze how to make neural computation of VLAs on GPU fast. However, we leave the question of how to actually deploy the VLA system on the real robots open. In this report we describe a set of practical techniques to achieve the end-to-end result of running a VLA-driven robot at an impressive speed in real world tasks that require both accuracy and dexterity. The stack of technology ranges across calibration, planning & control, and learning based method to identify optimal execution speed. In the tasks we show, the robot even executes in a speed on par with casual human operation and approaching the hardware limit of our lightweight arm. The unaccelerated videos and inference traces are provided in https://dexmal.github.io/realtime-vla-v2/.
Morphology-Consistent Humanoid Interaction through Robot-Centric Video Synthesis
Mar 20, 2026Equipping humanoid robots with versatile interaction skills typically requires either extensive policy training or explicit human-to-robot motion retargeting. However, learning-based policies face prohibitive data collection costs. Meanwhile, retargeting relies on human-centric pose estimation (e.g., SMPL), introducing a morphology gap. Skeletal scale mismatches result in severe spatial misalignments when mapped to robots, compromising interaction success. In this work, we propose Dream2Act, a robot-centric framework enabling zero-shot interaction through generative video synthesis. Given a third-person image of the robot and target object, our framework leverages video generation models to envision the robot completing the task with morphology-consistent motion. We employ a high-fidelity pose extraction system to recover physically feasible, robot-native joint trajectories from these synthesized dreams, subsequently executed via a general-purpose whole-body controller. Operating strictly within the robot-native coordinate space, Dream2Act avoids retargeting errors and eliminates task-specific policy training. We evaluate Dream2Act on the Unitree G1 across four whole-body mobile interaction tasks: ball kicking, sofa sitting, bag punching, and box hugging. Dream2Act achieves a 37.5% overall success rate, compared to 0% for conventional retargeting. While retargeting fails to establish correct physical contacts due to the morphology gap (with errors compounded during locomotion), Dream2Act maintains robot-consistent spatial alignment, enabling reliable contact formation and substantially higher task completion.
Spherical Latent Motion Prior for Physics-Based Simulated Humanoid Control
Mar 01, 2026Learning motion priors for physics-based humanoid control is an active research topic. Existing approaches mainly include variational autoencoders (VAE) and adversarial motion priors (AMP). VAE introduces information loss, and random latent sampling may sometimes produce invalid behaviors. AMP suffers from mode collapse and struggles to capture diverse motion skills. We present the Spherical Latent Motion Prior (SLMP), a two-stage method for learning motion priors. In the first stage, we train a high-quality motion tracking controller. In the second stage, we distill the tracking controller into a spherical latent space. A combination of distillation, a discriminator, and a discriminator-guided local semantic consistency constraint shapes a structured latent action space, allowing stable random sampling without information loss. To evaluate SLMP, we collect a two-hour human combat motion capture dataset and show that SLMP preserves fine motion detail without information loss, and random sampling yields semantically valid and stable behaviors. When applied to a two-agent physics-based combat task, SLMP produces human-like and physically plausible combat behaviors only using simple rule-based rewards. Furthermore, SLMP generalizes across different humanoid robot morphologies, demonstrating its transferability beyond a single simulated avatar.
T2MBench: A Benchmark for Out-of-Distribution Text-to-Motion Generation
Feb 14, 2026Most existing evaluations of text-to-motion generation focus on in-distribution textual inputs and a limited set of evaluation criteria, which restricts their ability to systematically assess model generalization and motion generation capabilities under complex out-of-distribution (OOD) textual conditions. To address this limitation, we propose a benchmark specifically designed for OOD text-to-motion evaluation, which includes a comprehensive analysis of 14 representative baseline models and the two datasets derived from evaluation results. Specifically, we construct an OOD prompt dataset consisting of 1,025 textual descriptions. Based on this prompt dataset, we introduce a unified evaluation framework that integrates LLM-based Evaluation, Multi-factor Motion evaluation, and Fine-grained Accuracy Evaluation. Our experimental results reveal that while different baseline models demonstrate strengths in areas such as text-to-motion semantic alignment, motion generalizability, and physical quality, most models struggle to achieve strong performance with Fine-grained Accuracy Evaluation. These findings highlight the limitations of existing methods in OOD scenarios and offer practical guidance for the design and evaluation of future production-level text-to-motion models.
Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
Jan 08, 2026We introduce Talk2Move, a reinforcement learning (RL) based diffusion framework for text-instructed spatial transformation of objects within scenes. Spatially manipulating objects in a scene through natural language poses a challenge for multimodal generation systems. While existing text-based manipulation methods can adjust appearance or style, they struggle to perform object-level geometric transformations-such as translating, rotating, or resizing objects-due to scarce paired supervision and pixel-level optimization limits. Talk2Move employs Group Relative Policy Optimization (GRPO) to explore geometric actions through diverse rollouts generated from input images and lightweight textual variations, removing the need for costly paired data. A spatial reward guided model aligns geometric transformations with linguistic description, while off-policy step evaluation and active step sampling improve learning efficiency by focusing on informative transformation stages. Furthermore, we design object-centric spatial rewards that evaluate displacement, rotation, and scaling behaviors directly, enabling interpretable and coherent transformations. Experiments on curated benchmarks demonstrate that Talk2Move achieves precise, consistent, and semantically faithful object transformations, outperforming existing text-guided editing approaches in both spatial accuracy and scene coherence.
SS4D: Native 4D Generative Model via Structured Spacetime Latents
Dec 16, 2025
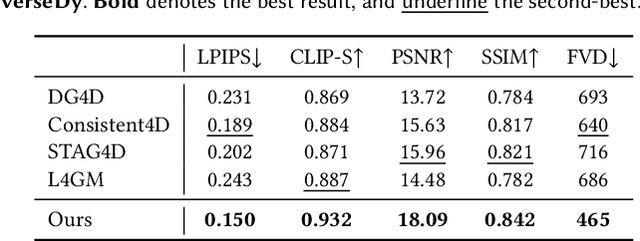
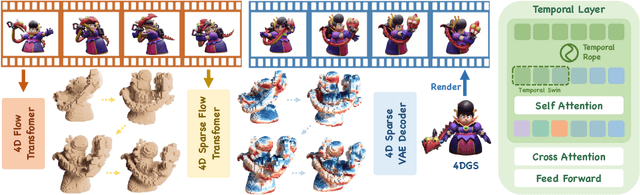
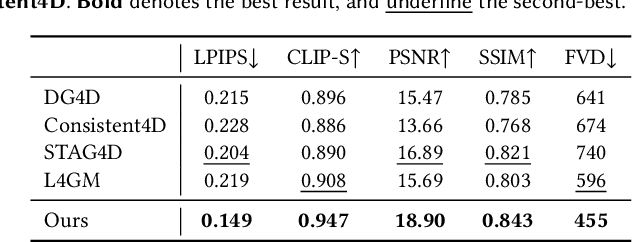
We present SS4D, a native 4D generative model that synthesizes dynamic 3D objects directly from monocular video. Unlike prior approaches that construct 4D representations by optimizing over 3D or video generative models, we train a generator directly on 4D data, achieving high fidelity, temporal coherence, and structural consistency. At the core of our method is a compressed set of structured spacetime latents. Specifically, (1) To address the scarcity of 4D training data, we build on a pre-trained single-image-to-3D model, preserving strong spatial consistency. (2) Temporal consistency is enforced by introducing dedicated temporal layers that reason across frames. (3) To support efficient training and inference over long video sequences, we compress the latent sequence along the temporal axis using factorized 4D convolutions and temporal downsampling blocks. In addition, we employ a carefully designed training strategy to enhance robustness against occlusion
* ToG(Siggraph Asia 2025)
GenDoP: Auto-regressive Camera Trajectory Generation as a Director of Photography
Apr 10, 2025Camera trajectory design plays a crucial role in video production, serving as a fundamental tool for conveying directorial intent and enhancing visual storytelling. In cinematography, Directors of Photography meticulously craft camera movements to achieve expressive and intentional framing. However, existing methods for camera trajectory generation remain limited: Traditional approaches rely on geometric optimization or handcrafted procedural systems, while recent learning-based methods often inherit structural biases or lack textual alignment, constraining creative synthesis. In this work, we introduce an auto-regressive model inspired by the expertise of Directors of Photography to generate artistic and expressive camera trajectories. We first introduce DataDoP, a large-scale multi-modal dataset containing 29K real-world shots with free-moving camera trajectories, depth maps, and detailed captions in specific movements, interaction with the scene, and directorial intent. Thanks to the comprehensive and diverse database, we further train an auto-regressive, decoder-only Transformer for high-quality, context-aware camera movement generation based on text guidance and RGBD inputs, named GenDoP. Extensive experiments demonstrate that compared to existing methods, GenDoP offers better controllability, finer-grained trajectory adjustments, and higher motion stability. We believe our approach establishes a new standard for learning-based cinematography, paving the way for future advancements in camera control and filmmaking. Our project website: https://kszpxxzmc.github.io/GenDoP/.
IDArb: Intrinsic Decomposition for Arbitrary Number of Input Views and Illuminations
Dec 16, 2024



Capturing geometric and material information from images remains a fundamental challenge in computer vision and graphics. Traditional optimization-based methods often require hours of computational time to reconstruct geometry, material properties, and environmental lighting from dense multi-view inputs, while still struggling with inherent ambiguities between lighting and material. On the other hand, learning-based approaches leverage rich material priors from existing 3D object datasets but face challenges with maintaining multi-view consistency. In this paper, we introduce IDArb, a diffusion-based model designed to perform intrinsic decomposition on an arbitrary number of images under varying illuminations. Our method achieves accurate and multi-view consistent estimation on surface normals and material properties. This is made possible through a novel cross-view, cross-domain attention module and an illumination-augmented, view-adaptive training strategy. Additionally, we introduce ARB-Objaverse, a new dataset that provides large-scale multi-view intrinsic data and renderings under diverse lighting conditions, supporting robust training. Extensive experiments demonstrate that IDArb outperforms state-of-the-art methods both qualitatively and quantitatively. Moreover, our approach facilitates a range of downstream tasks, including single-image relighting, photometric stereo, and 3D reconstruction, highlighting its broad applications in realistic 3D content creation.
Imagine360: Immersive 360 Video Generation from Perspective Anchor
Dec 04, 2024



$360^\circ$ videos offer a hyper-immersive experience that allows the viewers to explore a dynamic scene from full 360 degrees. To achieve more user-friendly and personalized content creation in $360^\circ$ video format, we seek to lift standard perspective videos into $360^\circ$ equirectangular videos. To this end, we introduce Imagine360, the first perspective-to-$360^\circ$ video generation framework that creates high-quality $360^\circ$ videos with rich and diverse motion patterns from video anchors. Imagine360 learns fine-grained spherical visual and motion patterns from limited $360^\circ$ video data with several key designs. 1) Firstly we adopt the dual-branch design, including a perspective and a panorama video denoising branch to provide local and global constraints for $360^\circ$ video generation, with motion module and spatial LoRA layers fine-tuned on extended web $360^\circ$ videos. 2) Additionally, an antipodal mask is devised to capture long-range motion dependencies, enhancing the reversed camera motion between antipodal pixels across hemispheres. 3) To handle diverse perspective video inputs, we propose elevation-aware designs that adapt to varying video masking due to changing elevations across frames. Extensive experiments show Imagine360 achieves superior graphics quality and motion coherence among state-of-the-art $360^\circ$ video generation methods. We believe Imagine360 holds promise for advancing personalized, immersive $360^\circ$ video creation.
LayerPano3D: Layered 3D Panorama for Hyper-Immersive Scene Generation
Aug 23, 2024



3D immersive scene generation is a challenging yet critical task in computer vision and graphics. A desired virtual 3D scene should 1) exhibit omnidirectional view consistency, and 2) allow for free exploration in complex scene hierarchies. Existing methods either rely on successive scene expansion via inpainting or employ panorama representation to represent large FOV scene environments. However, the generated scene suffers from semantic drift during expansion and is unable to handle occlusion among scene hierarchies. To tackle these challenges, we introduce LayerPano3D, a novel framework for full-view, explorable panoramic 3D scene generation from a single text prompt. Our key insight is to decompose a reference 2D panorama into multiple layers at different depth levels, where each layer reveals the unseen space from the reference views via diffusion prior. LayerPano3D comprises multiple dedicated designs: 1) we introduce a novel text-guided anchor view synthesis pipeline for high-quality, consistent panorama generation. 2) We pioneer the Layered 3D Panorama as underlying representation to manage complex scene hierarchies and lift it into 3D Gaussians to splat detailed 360-degree omnidirectional scenes with unconstrained viewing paths. Extensive experiments demonstrate that our framework generates state-of-the-art 3D panoramic scene in both full view consistency and immersive exploratory experience. We believe that LayerPano3D holds promise for advancing 3D panoramic scene creation with numerous applications.