 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS4D: Native 4D Generative Model via Structured Spacetime Latents
Dec 16, 2025
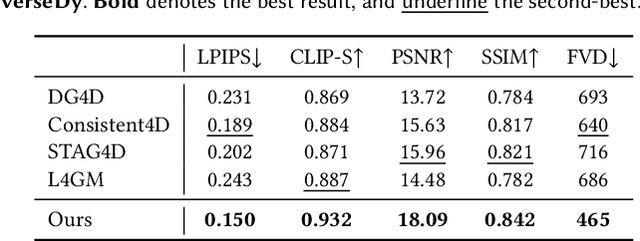
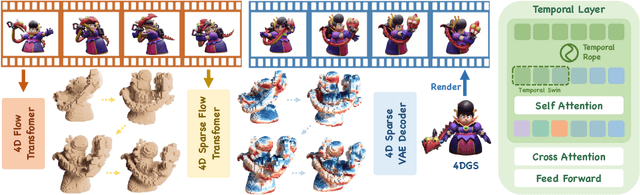
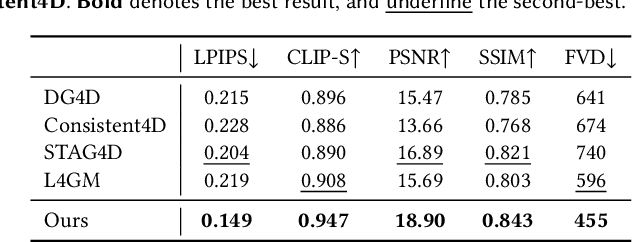
We present SS4D, a native 4D generative model that synthesizes dynamic 3D objects directly from monocular video. Unlike prior approaches that construct 4D representations by optimizing over 3D or video generative models, we train a generator directly on 4D data, achieving high fidelity, temporal coherence, and structural consistency. At the core of our method is a compressed set of structured spacetime latents. Specifically, (1) To address the scarcity of 4D training data, we build on a pre-trained single-image-to-3D model, preserving strong spatial consistency. (2) Temporal consistency is enforced by introducing dedicated temporal layers that reason across frames. (3) To support efficient training and inference over long video sequences, we compress the latent sequence along the temporal axis using factorized 4D convolutions and temporal downsampling blocks. In addition, we employ a carefully designed training strategy to enhance robustness against occlusion
* ToG(Siggraph Asia 2025)
Hi3DEval: Advancing 3D Generation Evaluation with Hierarchical Validity
Aug 07, 2025



Despite rapid advances in 3D content generation, quality assessment for the generated 3D assets remains challenging. Existing methods mainly rely on image-based metrics and operate solely at the object level, limiting their ability to capture spatial coherence, material authenticity, and high-fidelity local details. 1) To address these challenges, we introduce Hi3DEval, a hierarchical evaluation framework tailored for 3D generative content. It combines both object-level and part-level evaluation, enabling holistic assessments across multiple dimensions as well as fine-grained quality analysis. Additionally, we extend texture evaluation beyond aesthetic appearance by explicitly assessing material realism, focusing on attributes such as albedo, saturation, and metallicness. 2) To support this framework, we construct Hi3DBench, a large-scale dataset comprising diverse 3D assets and high-quality annotations, accompanied by a reliable multi-agent annotation pipeline. We further propose a 3D-aware automated scoring system based on hybrid 3D representations. Specifically, we leverage video-based representations for object-level and material-subject evaluations to enhance modeling of spatio-temporal consistency and employ pretrained 3D features for part-level perception. Extensive experiments demonstrate that our approach outperforms existing image-based metrics in modeling 3D characteristics and achieves superior alignment with human preference, providing a scalable alternative to manual evaluations. The project page is available at https://zyh482.github.io/Hi3DEval/.
IDArb: Intrinsic Decomposition for Arbitrary Number of Input Views and Illuminations
Dec 16, 2024



Capturing geometric and material information from images remains a fundamental challenge in computer vision and graphics. Traditional optimization-based methods often require hours of computational time to reconstruct geometry, material properties, and environmental lighting from dense multi-view inputs, while still struggling with inherent ambiguities between lighting and material. On the other hand, learning-based approaches leverage rich material priors from existing 3D object datasets but face challenges with maintaining multi-view consistency. In this paper, we introduce IDArb, a diffusion-based model designed to perform intrinsic decomposition on an arbitrary number of images under varying illuminations. Our method achieves accurate and multi-view consistent estimation on surface normals and material properties. This is made possible through a novel cross-view, cross-domain attention module and an illumination-augmented, view-adaptive training strategy. Additionally, we introduce ARB-Objaverse, a new dataset that provides large-scale multi-view intrinsic data and renderings under diverse lighting conditions, supporting robust training. Extensive experiments demonstrate that IDArb outperforms state-of-the-art methods both qualitatively and quantitatively. Moreover, our approach facilitates a range of downstream tasks, including single-image relighting, photometric stereo, and 3D reconstruction, highlighting its broad applications in realistic 3D content creation.
GPT-4V is a Human-Aligned Evaluator for Text-to-3D Generation
Jan 09, 2024



Despite recent advances in text-to-3D generative methods, there is a notable absence of reliable evaluation metrics. Existing metrics usually focus on a single criterion each, such as how well the asset aligned with the input text. These metrics lack the flexibility to generalize to different evaluation criteria and might not align well with human preferences. Conducting user preference studies is an alternative that offers both adaptability and human-aligned results. User studies, however, can be very expensive to scale. This paper presents an automatic, versatile, and human-aligned evaluation metric for text-to-3D generative models. To this end, we first develop a prompt generator using GPT-4V to generate evaluating prompts, which serve as input to compare text-to-3D models. We further design a method instructing GPT-4V to compare two 3D assets according to user-defined criteria. Finally, we use these pairwise comparison results to assign these models Elo ratings. Experimental results suggest our metric strongly align with human preference across different evaluation criteria.
HyperDreamer: Hyper-Realistic 3D Content Generation and Editing from a Single Image
Dec 07, 20233D content creation from a single image is a long-standing yet highly desirable task. Recent advances introduce 2D diffusion priors, yielding reasonable results. However, existing methods are not hyper-realistic enough for post-generation usage, as users cannot view, render and edit the resulting 3D content from a full range. To address these challenges, we introduce HyperDreamer with several key designs and appealing properties: 1) Viewable: 360 degree mesh modeling with high-resolution textures enables the creation of visually compelling 3D models from a full range of observation points. 2) Renderable: Fine-grained semantic segmentation and data-driven priors are incorporated as guidance to learn reasonable albedo, roughness, and specular properties of the materials, enabling semantic-aware arbitrary material estimation. 3) Editable: For a generated model or their own data, users can interactively select any region via a few clicks and efficiently edit the texture with text-based guidance. Extensive experiments demonstrate the effectiveness of HyperDreamer in modeling region-aware materials with high-resolution textures and enabling user-friendly editing. We believe that HyperDreamer holds promise for advancing 3D content creation and finding applications in various domains.
Inadequately Pre-trained Models are Better Feature Extractors
Mar 09, 2022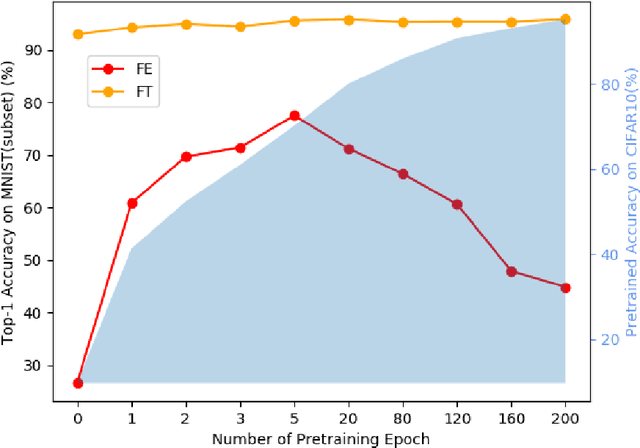
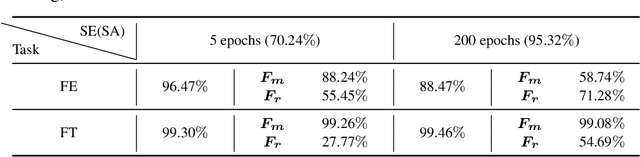
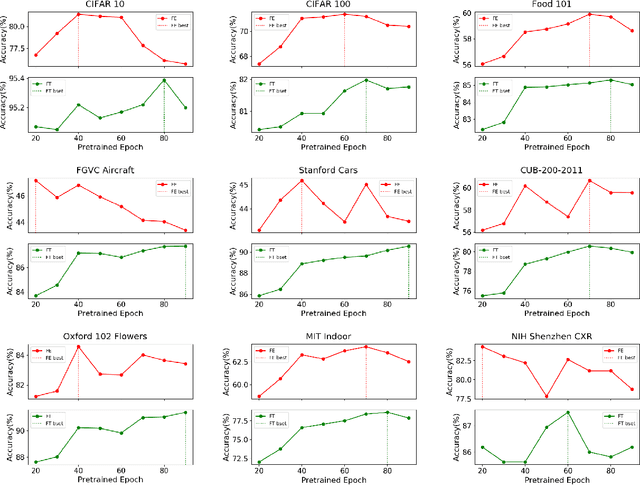
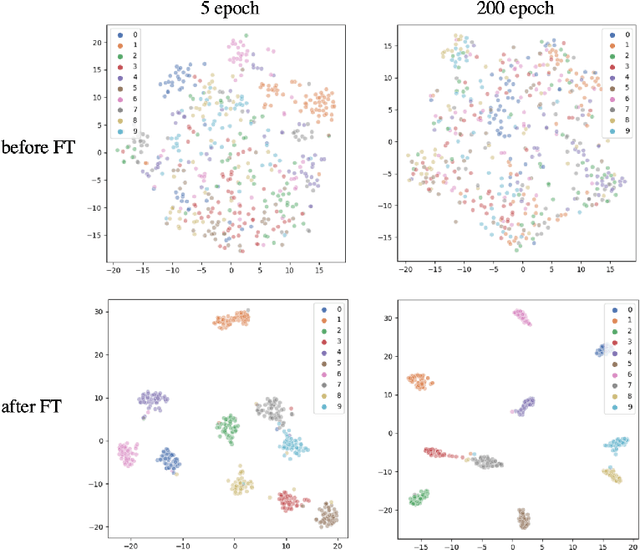
Pre-training has been a popular learning paradigm in deep learning era, especially in annotation-insufficient scenario. Better ImageNet pre-trained models have been demonstrated, from the perspective of architecture, by previous research to have better transferability to downstream tasks. However, in this paper, we found that during the same pre-training process, models at middle epochs, which is inadequately pre-trained, can outperform fully trained models when used as feature extractors (FE), while the fine-tuning (FT) performance still grows with the source performance. This reveals that there is not a solid positive correlation between top-1 accuracy on ImageNet and the transferring result on target data. Based on the contradictory phenomenon between FE and FT that better feature extractor fails to be fine-tuned better accordingly, we conduct comprehensive analyses on features before softmax layer to provide insightful explanations. Our discoveries suggest that, during pre-training, models tend to first learn spectral components corresponding to large singular values and the residual components contribute more when fine-tuning.