 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Decomposition for Multimodal Interaction Learning
Jun 10, 2026Multimodal learning hinges on capturing redundant, unique, and synergistic information across modalities, which collectively constitute multimodal interactions. A critical yet underexplored challenge is that these implicit interactions vary dynamically across samples. In this work, we present the first systematic, information-theoretic analysis highlighting why learning these dynamic, sample-specific interactions is critical for effective multimodal learning. Our analysis further reveals deficits in conventional paradigms at learning these distinct interaction types: modality ensemble approaches struggle to capture synergy, while joint learning paradigms often under-utilize redundant information. This highlights the need for an approach that can adaptively learn from different interaction types on a per-sample basis. To this end, we propose Decomposition-based Multimodal Interaction Learning (DMIL), a novel paradigm that explicitly models and learns from sample-specific interactions. First, we design a variational decomposition architecture to isolate the constituent interaction components. Second, we employ a new learning strategy that leverages these explicit interaction components in a fine-tuning process to achieve comprehensive interaction learning. Extensive experiments across diverse tasks and architectures demonstrate that DMIL consistently achieves superior performance by adapting to holistic sample-specific interactions. Our framework is flexible and broadly applicable, establishing an interaction-centric paradigm for multimodal learning. The code is available at https://github.com/GeWu-Lab/DMIL.
MIBench: Evaluating LMMs on Multimodal Interaction
Mar 13, 2026In different multimodal scenarios, it needs to integrate and utilize information across modalities in a specific way based on the demands of the task. Different integration ways between modalities are referred to as "multimodal interaction". How well a model handles various multimodal interactions largely characterizes its multimodal ability. In this paper, we introduce MIBench, a comprehensive benchmark designed to evaluate the multimodal interaction capabilities of Large Multimodal Models (LMMs), which formulates each instance as a (con_v , con_t, task) triplet with contexts from vision and text, necessitating that LMMs employ correct forms of multimodal interaction to effectively complete the task. MIBench assesses models from three key aspects: the ability to source information from vision-centric or text-centric cues, and the ability to generate new information from their joint synergy. Each interaction capability is evaluated hierarchically across three cognitive levels: Recognition, Understanding, and Reasoning. MIBench comprises over 10,000 vision-text context pairs spanning 32 distinct tasks. Evaluation of state-of-the-art LMMs show that: (1) LMMs' ability on multimodal interaction remains constrained, despite the scaling of model parameters and training data; (2) they are easily distracted by textual modalities when processing vision information; (3) they mostly possess a basic capacity for multimodal synergy; and (4) natively trained multimodal models show noticeable deficits in fundamental interaction ability. We expect that these observations can serve as a reference for developing LMMs with more enhanced multimodal ability in the future.
Crab$^{+}$: A Scalable and Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
Mar 04, 2026Developing Audio-Visual Large Language Models (AV-LLMs) for unified scene understanding is pivotal in multimodal intelligence. While instruction tuning enables pre-trained models with multi-task abilities, we observe that conventional multi-task unification methods often suffer from severe negative transfer, where nearly 55% of tasks degrade compared to single-task training. We attribute this phenomenon to audio-visual task heterogeneity, characterized by disparate task granularity and divergent capability demands, which lead to negative interference under joint training. To tackle this, we present Crab$^{+}$, a scalable and unified audio-visual scene understanding model that addresses task heterogeneity through explicit cooperation from both data and model perspectives. On the data side, we introduce AV-UIE v2, a comprehensive Audio-Visual Unified Instruction-tuning dataset with Explicit reasoning processes. It contains approximately 222K samples spanning 17 datasets and 7 tasks, enabling the model to capture cross-task relationships at different levels of granularity. On the model side, we design a unified interface to align heterogeneous task formulations, and propose Interaction-aware LoRA (I-LoRA), which explicitly models inter-task relationships via dynamic routing to coordinate distinct audio-visual interaction patterns, mitigating parameter interference. Extensive experiments show Crab$^{+}$ covers broader tasks than existing unified models while outperforming specialized models on various benchmarks. We successfully reverse the negative transfer trend, achieving positive transfer where multi-task learning surpasses single-task baselines in nearly 88% of tasks. These results hold across diverse AV-LLM paradigms and are validated through in-depth visualization, positioning Crab$^{+}$ as a robust step towards holistic audio-visual scene understanding.
APPO: Attention-guided Perception Policy Optimization for Video Reasoning
Mar 03, 2026Complex video reasoning, actually, relies excessively on fine-grained perception rather than on expert (e.g., Ph.D, Science)-level reasoning. Through extensive empirical observation, we have recognized the critical impact of perception. In particular, when perception ability is almost fixed, enhancing reasoning from Qwen3-8B to OpenAI-o3 yields only 0.7% performance improvement. Conversely, even minimal change in perception model scale (from 7B to 32B) boosts performance by 1.4%, indicating enhancing perception, rather than reasoning, is more critical to improve performance. Therefore, exploring how to enhance perception ability through reasoning without the need for expensive fine-grained annotation information is worthwhile. To achieve this goal, we specially propose APPO, the Attention-guided Perception Policy Optimization algorithm that leverages token-level dense rewards to improve model's fine-grained perception. The core idea behind APPO is to optimize those tokens from different responses that primarily focus on the same crucial video frame (called intra-group perception tokens). Experimental results on diverse video benchmarks and models with different scales (3/7B) demonstrate APPO consistently outperforms GRPO and DAPO (0.5%~4%). We hope our work provides a promising approach to effectively enhance model's perception abilities through reasoning in a low-cost manner, serving diverse scenarios and demands.
GeCo-SRT: Geometry-aware Continual Adaptation for Robotic Cross-Task Sim-to-Real Transfer
Feb 25, 2026Bridging the sim-to-real gap is important for applying low-cost simulation data to real-world robotic systems. However, previous methods are severely limited by treating each transfer as an isolated endeavor, demanding repeated, costly tuning and wasting prior transfer experience. To move beyond isolated sim-to-real, we build a continual cross-task sim-to-real transfer paradigm centered on knowledge accumulation across iterative transfers, thereby enabling effective and efficient adaptation to novel tasks. Thus, we propose GeCo-SRT, a geometry-aware continual adaptation method. It utilizes domain-invariant and task-invariant knowledge from local geometric features as a transferable foundation to accelerate adaptation during subsequent sim-to-real transfers. This method starts with a geometry-aware mixture-of-experts module, which dynamically activates experts to specialize in distinct geometric knowledge to bridge observation sim-to-real gap. Further, the geometry-expert-guided prioritized experience replay module preferentially samples from underutilized experts, refreshing specialized knowledge to combat forgetting and maintain robust cross-task performance. Leveraging knowledge accumulated during iterative transfer, GeCo-SRT method not only achieves 52% average performance improvement over the baseline, but also demonstrates significant data efficiency for new task adaptation with only 1/6 data. We hope this work inspires approaches for efficient, low-cost cross-task sim-to-real transfer.
When would Vision-Proprioception Policies Fail in Robotic Manipulation?
Feb 12, 2026Proprioceptive information is critical for precise servo control by providing real-time robotic states. Its collaboration with vision is highly expected to enhance performances of the manipulation policy in complex tasks. However, recent studies have reported inconsistent observations on the generalization of vision-proprioception policies. In this work, we investigate this by conducting temporally controlled experiments. We found that during task sub-phases that robot's motion transitions, which require target localization, the vision modality of the vision-proprioception policy plays a limited role. Further analysis reveals that the policy naturally gravitates toward concise proprioceptive signals that offer faster loss reduction when training, thereby dominating the optimization and suppressing the learning of the visual modality during motion-transition phases. To alleviate this, we propose the Gradient Adjustment with Phase-guidance (GAP) algorithm that adaptively modulates the optimization of proprioception, enabling dynamic collaboration within the vision-proprioception policy. Specifically, we leverage proprioception to capture robotic states and estimate the probability of each timestep in the trajectory belonging to motion-transition phases. During policy learning, we apply fine-grained adjustment that reduces the magnitude of proprioception's gradient based on estimated probabilities, leading to robust and generalizable vision-proprioception policies. The comprehensive experiments demonstrate GAP is applicable in both simulated and real-world environments, across one-arm and dual-arm setups, and compatible with both conventional and Vision-Language-Action models. We believe this work can offer valuable insights into the development of vision-proprioception policies in robotic manipulation.
AnyTouch 2: General Optical Tactile Representation Learning For Dynamic Tactile Perception
Feb 10, 2026Real-world contact-rich manipulation demands robots to perceive temporal tactile feedback, capture subtle surface deformations, and reason about object properties as well as force dynamics. Although optical tactile sensors are uniquely capable of providing such rich information, existing tactile datasets and models remain limited. These resources primarily focus on object-level attributes (e.g., material) while largely overlooking fine-grained tactile temporal dynamics during physical interactions. We consider that advancing dynamic tactile perception requires a systematic hierarchy of dynamic perception capabilities to guide both data collection and model design. To address the lack of tactile data with rich dynamic information, we present ToucHD, a large-scale hierarchical tactile dataset spanning tactile atomic actions, real-world manipulations, and touch-force paired data. Beyond scale, ToucHD establishes a comprehensive tactile dynamic data ecosystem that explicitly supports hierarchical perception capabilities from the data perspective. Building on it, we propose AnyTouch 2, a general tactile representation learning framework for diverse optical tactile sensors that unifies object-level understanding with fine-grained, force-aware dynamic perception. The framework captures both pixel-level and action-specific deformations across frames, while explicitly modeling physical force dynamics, thereby learning multi-level dynamic perception capabilities from the model perspective. We evaluate our model on benchmarks that covers static object properties and dynamic physical attributes, as well as real-world manipulation tasks spanning multiple tiers of dynamic perception capabilities-from basic object-level understanding to force-aware dexterous manipulation. Experimental results demonstrate consistent and strong performance across sensors and tasks.
Video Detective: Seek Critical Clues Recurrently to Answer Question from Long Videos
Dec 19, 2025Long Video Question-Answering (LVQA) presents a significant challenge for Multi-modal Large Language Models (MLLMs) due to immense context and overloaded information, which could also lead to prohibitive memory consumption. While existing methods attempt to address these issues by reducing visual tokens or extending model's context length, they may miss useful information or take considerable computation. In fact, when answering given questions, only a small amount of crucial information is required. Therefore, we propose an efficient question-aware memory mechanism, enabling MLLMs to recurrently seek these critical clues. Our approach, named VideoDetective, simplifies this task by iteratively processing video sub-segments. For each sub-segment, a question-aware compression strategy is employed by introducing a few special memory tokens to achieve purposefully compression. This allows models to effectively seek critical clues while reducing visual tokens. Then, due to history context could have a significant impact, we recurrently aggregate and store these memory tokens to update history context, which would be reused for subsequent sub-segments. Furthermore, to more effectively measure model's long video understanding ability, we introduce GLVC (Grounding Long Video Clues), a long video question-answering dataset, which features grounding critical and concrete clues scattered throughout entire videos. Experimental results demonstrate our method enables MLLMs with limited context length of 32K to efficiently process 100K tokens (3600 frames, an hour-long video sampled at 1fps), requiring only 2 minutes and 37GB GPU memory usage. Evaluation results across multiple long video benchmarks illustrate our method can more effectively seek critical clues from massive information.
Understanding Stigmatizing Language Lexicons: A Comparative Analysis in Clinical Contexts
Sep 09, 2025Stigmatizing language results in healthcare inequities, yet there is no universally accepted or standardized lexicon defining which words, terms, or phrases constitute stigmatizing language in healthcare. We conducted a systematic search of the literature to identify existing stigmatizing language lexicons and then analyzed them comparatively to examine: 1) similarities and discrepancies between these lexicons, and 2) the distribution of positive, negative, or neutral terms based on an established sentiment dataset. Our search identified four lexicons. The analysis results revealed moderate semantic similarity among them, and that most stigmatizing terms are related to judgmental expressions by clinicians to describe perceived negative behaviors. Sentiment analysis showed a predominant proportion of negatively classified terms, though variations exist across lexicons. Our findings underscore the need for a standardized lexicon and highlight challenges in defining stigmatizing language in clinical texts.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025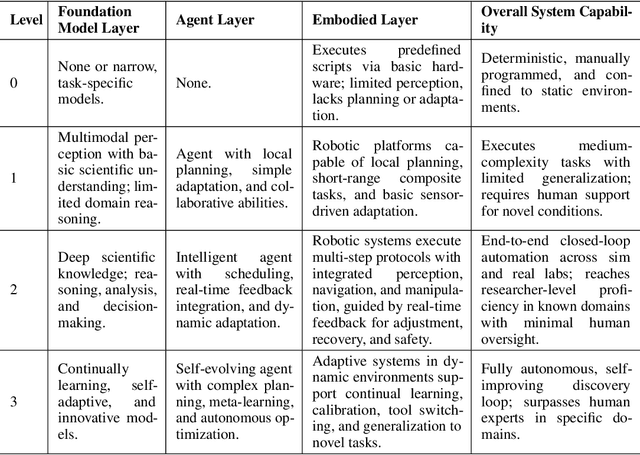
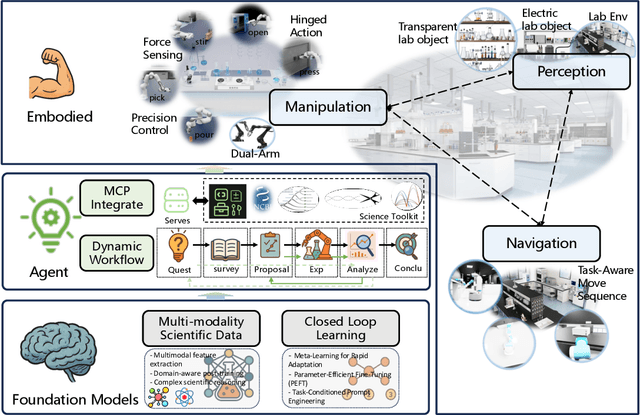
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.