 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Future Data Center Operations and Management via Physical AI
Apr 07, 2025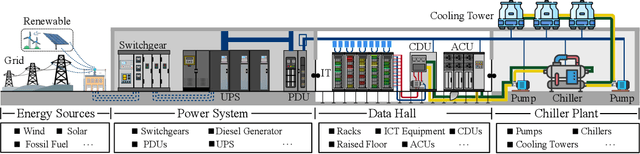
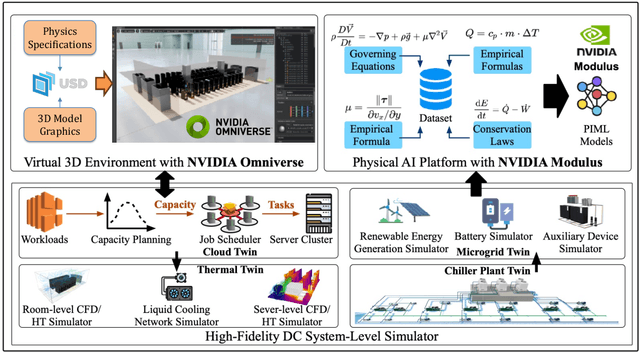
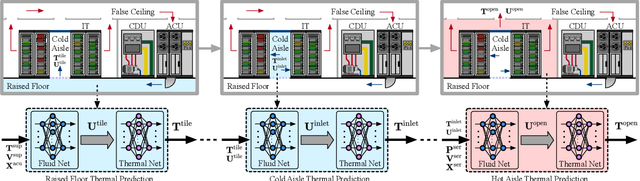
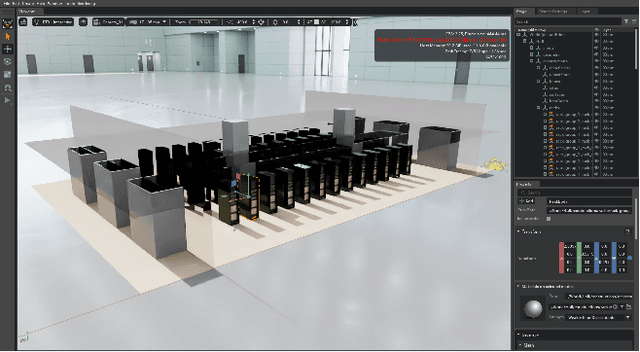
Data centers (DCs) as mission-critical infrastructures are pivotal in powering the growth of artificial intelligence (AI) and the digital economy. The evolution from Internet DC to AI DC has introduced new challenges in operating and managing data centers for improved business resilience and reduced total cost of ownership. As a result, new paradigms, beyond the traditional approaches based on best practices, must be in order for future data centers. In this research, we propose and develop a novel Physical AI (PhyAI) framework for advancing DC operations and management. Our system leverages the emerging capabilities of state-of-the-art industrial products and our in-house research and development. Specifically, it presents three core modules, namely: 1) an industry-grade in-house simulation engine to simulate DC operations in a highly accurate manner, 2) an AI engine built upon NVIDIA PhysicsNemo for the training and evaluation of physics-informed machine learning (PIML) models, and 3) a digital twin platform built upon NVIDIA Omniverse for our proposed 5-tier digital twin framework. This system presents a scalable and adaptable solution to digitalize, optimize, and automate future data center operations and management, by enabling real-time digital twins for future data centers. To illustrate its effectiveness, we present a compelling case study on building a surrogate model for predicting the thermal and airflow profiles of a large-scale DC in a real-time manner. Our results demonstrate its superior performance over traditional time-consuming Computational Fluid Dynamics/Heat Transfer (CFD/HT) simulation, with a median absolute temperature prediction error of 0.18 {\deg}C. This emerging approach would open doors to several potential research directions for advancing Physical AI in future DC operations.
Unified Locomotion Transformer with Simultaneous Sim-to-Real Transfer for Quadrupeds
Mar 12, 2025



Quadrupeds have gained rapid advancement in their capability of traversing across complex terrains. The adoption of deep Reinforcement Learning (RL), transformers and various knowledge transfer techniques can greatly reduce the sim-to-real gap. However, the classical teacher-student framework commonly used in existing locomotion policies requires a pre-trained teacher and leverages the privilege information to guide the student policy. With the implementation of large-scale models in robotics controllers, especially transformers-based ones, this knowledge distillation technique starts to show its weakness in efficiency, due to the requirement of multiple supervised stages. In this paper, we propose Unified Locomotion Transformer (ULT), a new transformer-based framework to unify the processes of knowledge transfer and policy optimization in a single network while still taking advantage of privilege information. The policies are optimized with reinforcement learning, next state-action prediction, and action imitation, all in just one training stage, to achieve zero-shot deployment. Evaluation results demonstrate that with ULT, optimal teacher and student policies can be obtained at the same time, greatly easing the difficulty in knowledge transfer, even with complex transformer-based models.
Enhancing Modality Representation and Alignment for Multimodal Cold-start Active Learning
Dec 12, 2024Training multimodal models requires a large amount of labeled data. Active learning (AL) aim to reduce labeling costs. Most AL methods employ warm-start approaches, which rely on sufficient labeled data to train a well-calibrated model that can assess the uncertainty and diversity of unlabeled data. However, when assembling a dataset, labeled data are often scarce initially, leading to a cold-start problem. Additionally, most AL methods seldom address multimodal data, highlighting a research gap in this field. Our research addresses these issues by developing a two-stage method for Multi-Modal Cold-Start Active Learning (MMCSAL). Firstly, we observe the modality gap, a significant distance between the centroids of representations from different modalities, when only using cross-modal pairing information as self-supervision signals. This modality gap affects data selection process, as we calculate both uni-modal and cross-modal distances. To address this, we introduce uni-modal prototypes to bridge the modality gap. Secondly, conventional AL methods often falter in multimodal scenarios where alignment between modalities is overlooked. Therefore, we propose enhancing cross-modal alignment through regularization, thereby improving the quality of selected multimodal data pairs in AL. Finally, our experiments demonstrate MMCSAL's efficacy in selecting multimodal data pairs across three multimodal datasets.
Masked Sensory-Temporal Attention for Sensor Generalization in Quadruped Locomotion
Sep 05, 2024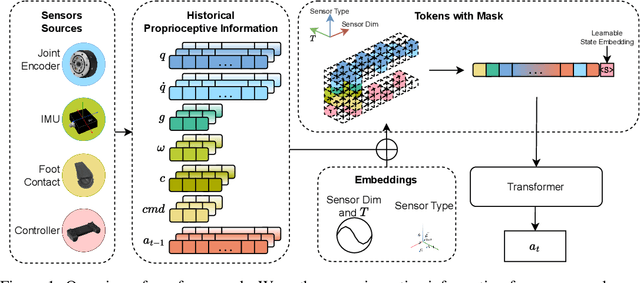
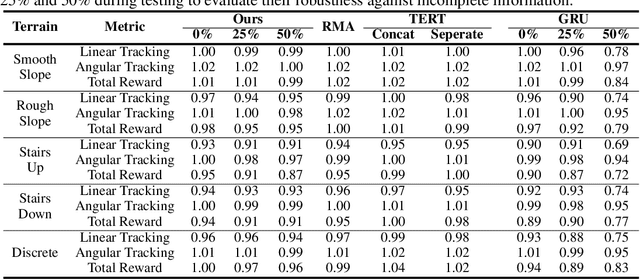
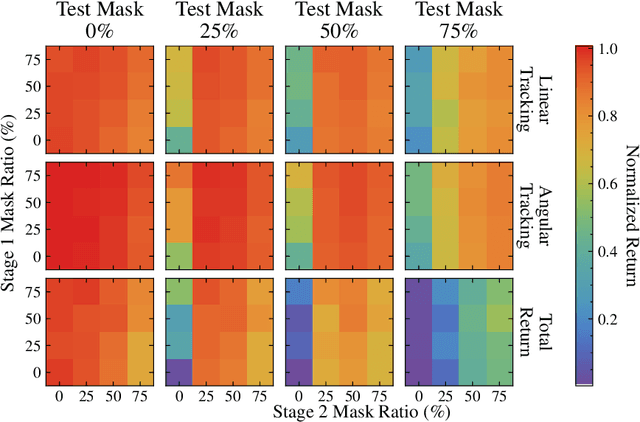

With the rising focus on quadrupeds, a generalized policy capable of handling different robot models and sensory inputs will be highly beneficial. Although several methods have been proposed to address different morphologies, it remains a challenge for learning-based policies to manage various combinations of proprioceptive information. This paper presents Masked Sensory-Temporal Attention (MSTA), a novel transformer-based model with masking for quadruped locomotion. It employs direct sensor-level attention to enhance sensory-temporal understanding and handle different combinations of sensor data, serving as a foundation for incorporating unseen information. This model can effectively understand its states even with a large portion of missing information, and is flexible enough to be deployed on a physical system despite the long input sequence.
Learning Gabor Texture Features for Fine-Grained Recognition
Aug 10, 2023Extracting and using class-discriminative features is critical for fine-grained recognition. Existing works have demonstrated the possibility of applying deep CNNs to exploit features that distinguish similar classes. However, CNNs suffer from problems including frequency bias and loss of detailed local information, which restricts the performance of recognizing fine-grained categories. To address the challenge, we propose a novel texture branch as complimentary to the CNN branch for feature extraction. We innovatively utilize Gabor filters as a powerful extractor to exploit texture features, motivated by the capability of Gabor filters in effectively capturing multi-frequency features and detailed local information. We implement several designs to enhance the effectiveness of Gabor filters, including imposing constraints on parameter values and developing a learning method to determine the optimal parameters. Moreover, we introduce a statistical feature extractor to utilize informative statistical information from the signals captured by Gabor filters, and a gate selection mechanism to enable efficient computation by only considering qualified regions as input for texture extraction. Through the integration of features from the Gabor-filter-based texture branch and CNN-based semantic branch, we achieve comprehensive information extraction. We demonstrate the efficacy of our method on multiple datasets, including CUB-200-2011, NA-bird, Stanford Dogs, and GTOS-mobile. State-of-the-art performance is achieved using our approach.
Towards Building AI-CPS with NVIDIA Isaac Sim: An Industrial Benchmark and Case Study for Robotics Manipulation
Jul 31, 2023



As a representative cyber-physical system (CPS), robotic manipulator has been widely adopted in various academic research and industrial processes, indicating its potential to act as a universal interface between the cyber and the physical worlds. Recent studies in robotics manipulation have started employing artificial intelligence (AI) approaches as controllers to achieve better adaptability and performance. However, the inherent challenge of explaining AI components introduces uncertainty and unreliability to these AI-enabled robotics systems, necessitating a reliable development platform for system design and performance assessment. As a foundational step towards building reliable AI-enabled robotics systems, we propose a public industrial benchmark for robotics manipulation in this paper. It leverages NVIDIA Omniverse Isaac Sim as the simulation platform, encompassing eight representative manipulation tasks and multiple AI software controllers. An extensive evaluation is conducted to analyze the performance of AI controllers in solving robotics manipulation tasks, enabling a thorough understanding of their effectiveness. To further demonstrate the applicability of our benchmark, we develop a falsification framework that is compatible with physical simulators and OpenAI Gym environments. This framework bridges the gap between traditional testing methods and modern physics engine-based simulations. The effectiveness of different optimization methods in falsifying AI-enabled robotics manipulation with physical simulators is examined via a falsification test. Our work not only establishes a foundation for the design and development of AI-enabled robotics systems but also provides practical experience and guidance to practitioners in this field, promoting further research in this critical academic and industrial domain.
Towards Balanced Active Learning for Multimodal Classification
Jun 14, 2023



Training multimodal networks requires a vast amount of data due to their larger parameter space compared to unimodal networks. Active learning is a widely used technique for reducing data annotation costs by selecting only those samples that could contribute to improving model performance. However, current active learning strategies are mostly designed for unimodal tasks, and when applied to multimodal data, they often result in biased sample selection from the dominant modality. This unfairness hinders balanced multimodal learning, which is crucial for achieving optimal performance. To address this issue, we propose three guidelines for designing a more balanced multimodal active learning strategy. Following these guidelines, a novel approach is proposed to achieve more fair data selection by modulating the gradient embedding with the dominance degree among modalities. Our studies demonstrate that the proposed method achieves more balanced multimodal learning by avoiding greedy sample selection from the dominant modality. Our approach outperforms existing active learning strategies on a variety of multimodal classification tasks. Overall, our work highlights the importance of balancing sample selection in multimodal active learning and provides a practical solution for achieving more balanced active learning for multimodal classification.
Continual Semantic Segmentation with Automatic Memory Sample Selection
Apr 11, 2023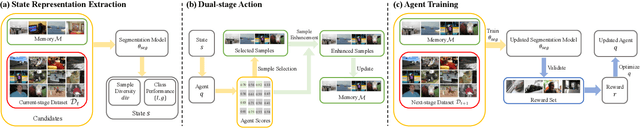
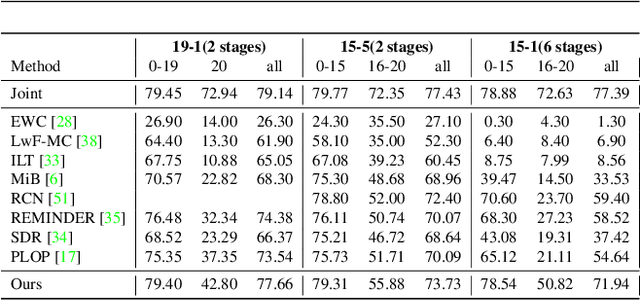
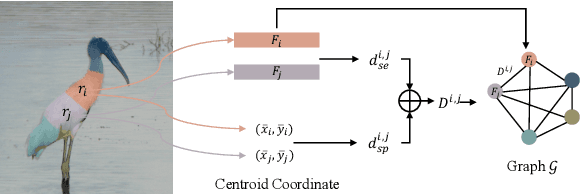
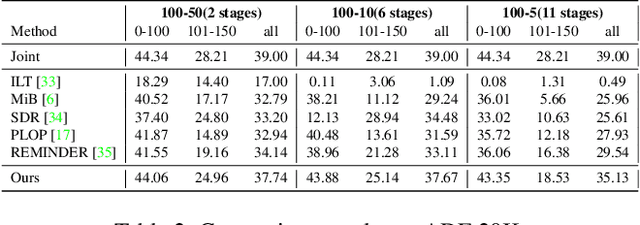
Continual Semantic Segmentation (CSS) extends static semantic segmentation by incrementally introducing new classes for training. To alleviate the catastrophic forgetting issue in CSS, a memory buffer that stores a small number of samples from the previous classes is constructed for replay. However, existing methods select the memory samples either randomly or based on a single-factor-driven handcrafted strategy, which has no guarantee to be optimal. In this work, we propose a novel memory sample selection mechanism that selects informative samples for effective replay in a fully automatic way by considering comprehensive factors including sample diversity and class performance. Our mechanism regards the selection operation as a decision-making process and learns an optimal selection policy that directly maximizes the validation performance on a reward set. To facilitate the selection decision, we design a novel state representation and a dual-stage action space. Our extensive experiments on Pascal-VOC 2012 and ADE 20K datasets demonstrate the effectiveness of our approach with state-of-the-art (SOTA) performance achieved, outperforming the second-place one by 12.54% for the 6stage setting on Pascal-VOC 2012.
MIGPerf: A Comprehensive Benchmark for Deep Learning Training and Inference Workloads on Multi-Instance GPUs
Jan 01, 2023New architecture GPUs like A100 are now equipped with multi-instance GPU (MIG) technology, which allows the GPU to be partitioned into multiple small, isolated instances. This technology provides more flexibility for users to support both deep learning training and inference workloads, but efficiently utilizing it can still be challenging. The vision of this paper is to provide a more comprehensive and practical benchmark study for MIG in order to eliminate the need for tedious manual benchmarking and tuning efforts. To achieve this vision, the paper presents MIGPerf, an open-source tool that streamlines the benchmark study for MIG. Using MIGPerf, the authors conduct a series of experiments, including deep learning training and inference characterization on MIG, GPU sharing characterization, and framework compatibility with MIG. The results of these experiments provide new insights and guidance for users to effectively employ MIG, and lay the foundation for further research on the orchestration of hybrid training and inference workloads on MIGs. The code and results are released on https://github.com/MLSysOps/MIGProfiler. This work is still in progress and more results will be published soon.
Saving the Limping: Fault-tolerant Quadruped Locomotion via Reinforcement Learning
Oct 02, 2022
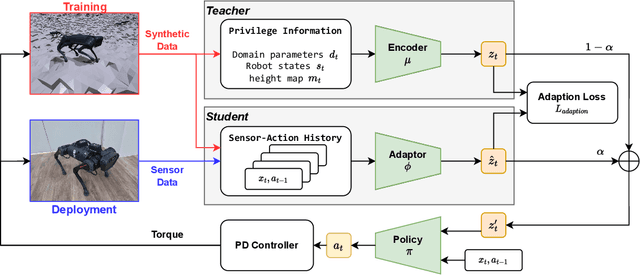

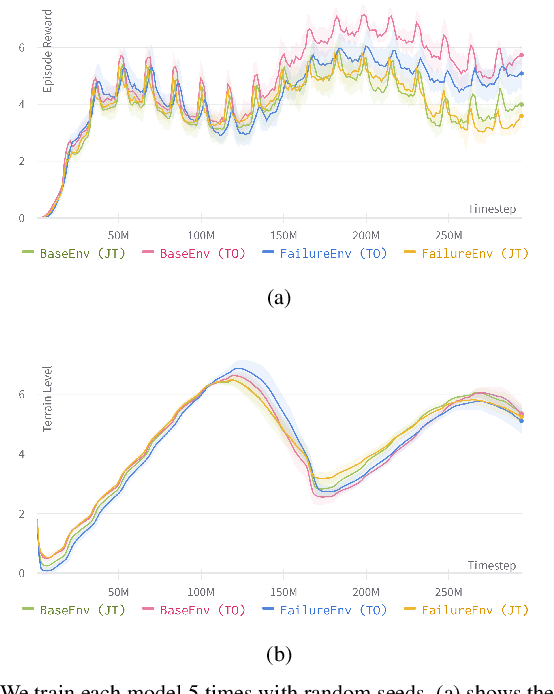
Quadruped locomotion now has acquired the skill to traverse or even sprint on uneven terrains in remote uncontrolled environment. However, surviving in the wild requires not only the maneuverability, but also the ability to handle unexpected hardware failures. We present the first deep reinforcement learning based methodology to train fault-tolerant controllers, which can bring an injured quadruped back home safely and speedily. We adopt the teacher-student framework to train the controller with close-to-reality joint-locking failure in the simulation, which can be zero-shot transferred to the physical robot without any fine-tuning. Extensive simulation and real-world experiments demonstrate that our fault-tolerant controller can efficiently lead a quadruped stably when it faces joint failure during locomotion.