 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorHub: Scalable and Elastic Weight Transfer for LLM RL Training
Apr 10, 2026Modern LLM reinforcement learning (RL) workloads require a highly efficient weight transfer system to scale training across heterogeneous computational resources. However, existing weight transfer approaches either fail to provide flexibility for dynamically scaling clusters or incur fundamental data movement overhead, resulting in poor performance. We introduce Reference-Oriented Storage (ROS), a new storage abstraction for RL weight transfer that exploits the highly replicated model weights in place. ROS presents the illusion that certain versions of the model weights are stored and can be fetched on demand. Underneath, ROS does not physically store any copies of the weights; instead, it tracks the workers that hold these weights on GPUs for inference. Upon request, ROS directly uses them to serve reads. We build TensorHub, a production-quality system that extends the ROS idea with topology-optimized transfer, strong consistency, and fault tolerance. Evaluation shows that TensorHub fully saturates RDMA bandwidth and adapts to three distinct rollout workloads with minimal engineering effort. Specifically, TensorHub reduces total GPU stall time by up to 6.7x for standalone rollouts, accelerates weight update for elastic rollout by 4.8x, and cuts cross-datacenter rollout stall time by 19x. TensorHub has been deployed in production to support cutting-edge RL training.
PRIOR: Personalized Prior for Reactivating the Information Overlooked in Federated Learning
Oct 13, 2023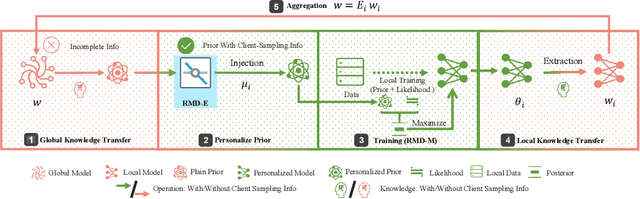
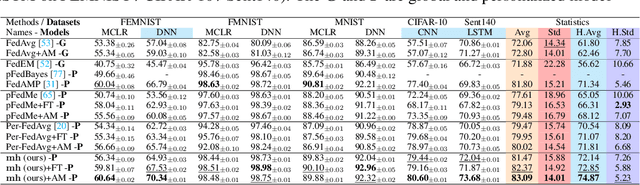
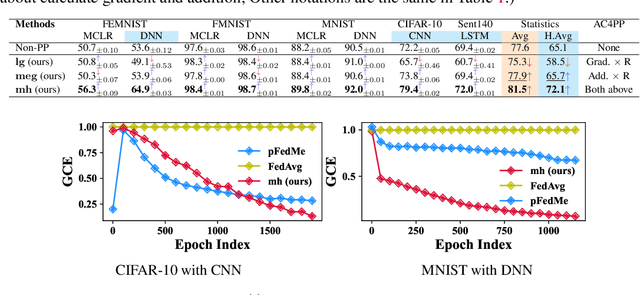
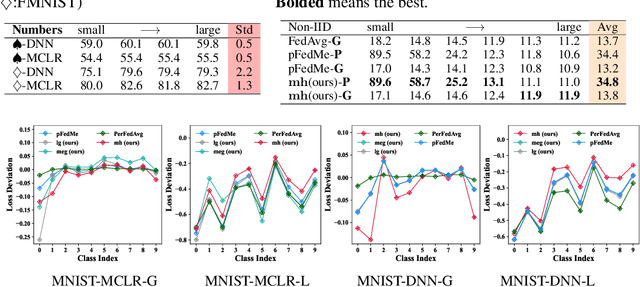
Classical federated learning (FL) enables training machine learning models without sharing data for privacy preservation, but heterogeneous data characteristic degrades the performance of the localized model. Personalized FL (PFL) addresses this by synthesizing personalized models from a global model via training on local data. Such a global model may overlook the specific information that the clients have been sampled. In this paper, we propose a novel scheme to inject personalized prior knowledge into the global model in each client, which attempts to mitigate the introduced incomplete information problem in PFL. At the heart of our proposed approach is a framework, the PFL with Bregman Divergence (pFedBreD), decoupling the personalized prior from the local objective function regularized by Bregman divergence for greater adaptability in personalized scenarios. We also relax the mirror descent (RMD) to extract the prior explicitly to provide optional strategies. Additionally, our pFedBreD is backed up by a convergence analysis. Sufficient experiments demonstrate that our method reaches the state-of-the-art performances on 5 datasets and outperforms other methods by up to 3.5% across 8 benchmarks. Extensive analyses verify the robustness and necessity of proposed designs.
DataCI: A Platform for Data-Centric AI on Streaming Data
Jul 03, 2023



We introduce DataCI, a comprehensive open-source platform designed specifically for data-centric AI in dynamic streaming data settings. DataCI provides 1) an infrastructure with rich APIs for seamless streaming dataset management, data-centric pipeline development and evaluation on streaming scenarios, 2) an carefully designed versioning control function to track the pipeline lineage, and 3) an intuitive graphical interface for a better interactive user experience. Preliminary studies and demonstrations attest to the easy-to-use and effectiveness of DataCI, highlighting its potential to revolutionize the practice of data-centric AI in streaming data contexts.
MIGPerf: A Comprehensive Benchmark for Deep Learning Training and Inference Workloads on Multi-Instance GPUs
Jan 01, 2023New architecture GPUs like A100 are now equipped with multi-instance GPU (MIG) technology, which allows the GPU to be partitioned into multiple small, isolated instances. This technology provides more flexibility for users to support both deep learning training and inference workloads, but efficiently utilizing it can still be challenging. The vision of this paper is to provide a more comprehensive and practical benchmark study for MIG in order to eliminate the need for tedious manual benchmarking and tuning efforts. To achieve this vision, the paper presents MIGPerf, an open-source tool that streamlines the benchmark study for MIG. Using MIGPerf, the authors conduct a series of experiments, including deep learning training and inference characterization on MIG, GPU sharing characterization, and framework compatibility with MIG. The results of these experiments provide new insights and guidance for users to effectively employ MIG, and lay the foundation for further research on the orchestration of hybrid training and inference workloads on MIGs. The code and results are released on https://github.com/MLSysOps/MIGProfiler. This work is still in progress and more results will be published soon.
Spatial-Temporal Federated Learning for Lifelong Person Re-identification on Distributed Edges
Jul 24, 2022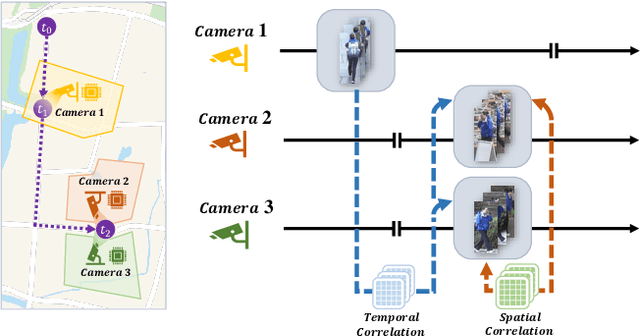
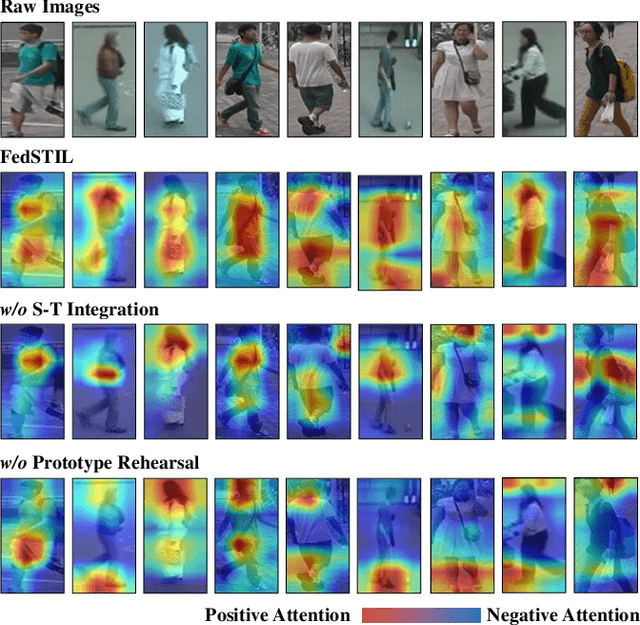
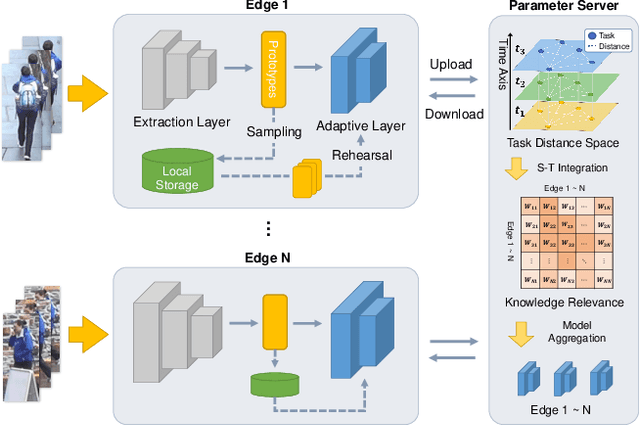
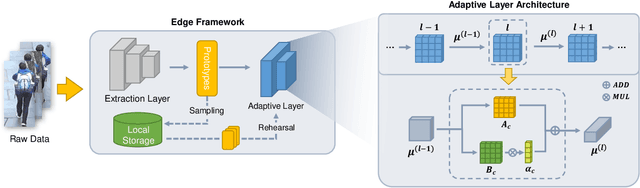
Data drift is a thorny challenge when deploying person re-identification (ReID) models into real-world devices, where the data distribution is significantly different from that of the training environment and keeps changing. To tackle this issue, we propose a federated spatial-temporal incremental learning approach, named FedSTIL, which leverages both lifelong learning and federated learning to continuously optimize models deployed on many distributed edge clients. Unlike previous efforts, FedSTIL aims to mine spatial-temporal correlations among the knowledge learnt from different edge clients. Specifically, the edge clients first periodically extract general representations of drifted data to optimize their local models. Then, the learnt knowledge from edge clients will be aggregated by centralized parameter server, where the knowledge will be selectively and attentively distilled from spatial- and temporal-dimension with carefully designed mechanisms. Finally, the distilled informative spatial-temporal knowledge will be sent back to correlated edge clients to further improve the recognition accuracy of each edge client with a lifelong learning method. Extensive experiments on a mixture of five real-world datasets demonstrate that our method outperforms others by nearly 4% in Rank-1 accuracy, while reducing communication cost by 62%. All implementation codes are publicly available on https://github.com/MSNLAB/Federated-Lifelong-Person-ReID
Active-Learning-as-a-Service: An Efficient MLOps System for Data-Centric AI
Jul 19, 2022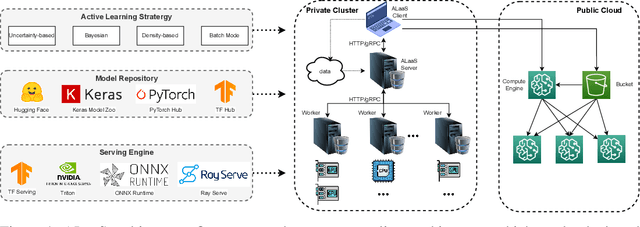
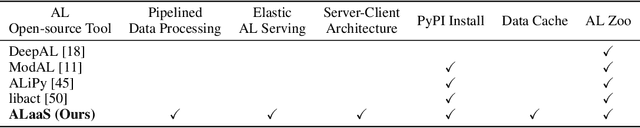
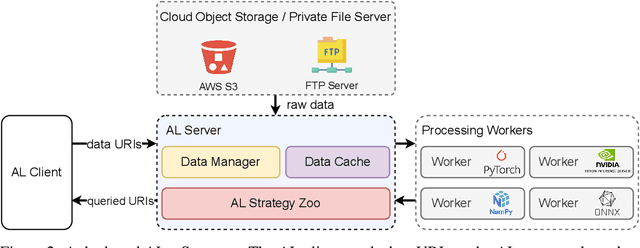

The success of today's AI applications requires not only model training (Model-centric) but also data engineering (Data-centric). In data-centric AI, active learning (AL) plays a vital role, but current AL tools can not perform AL tasks efficiently. To this end, this paper presents an efficient MLOps system for AL, named ALaaS (Active-Learning-as-a-Service). Specifically, ALaaS adopts a server-client architecture to support an AL pipeline and implements stage-level parallelism for high efficiency. Meanwhile, caching and batching techniques are employed to further accelerate the AL process. In addition to efficiency, ALaaS ensures accessibility with the help of the design philosophy of configuration-as-a-service. It also abstracts an AL process to several components and provides rich APIs for advanced users to extend the system to new scenarios. Extensive experiments show that ALaaS outperforms all other baselines in terms of latency and throughput. Further ablation studies demonstrate the effectiveness of our design as well as ALaaS's ease to use. Our code is available at \url{https://github.com/MLSysOps/alaas}.
ModelCI-e: Enabling Continual Learning in Deep Learning Serving Systems
Jun 06, 2021
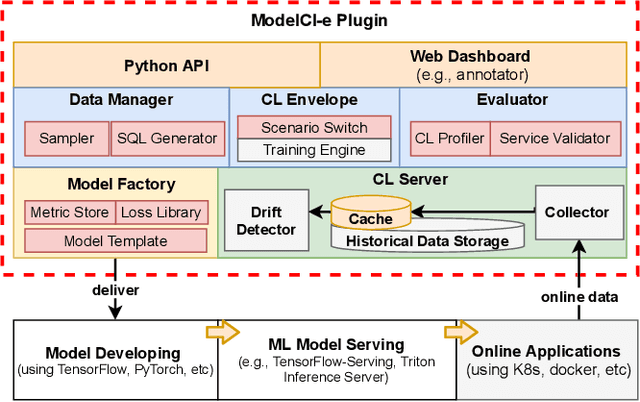
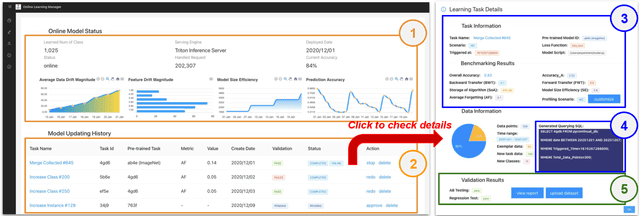

MLOps is about taking experimental ML models to production, i.e., serving the models to actual users. Unfortunately, existing ML serving systems do not adequately handle the dynamic environments in which online data diverges from offline training data, resulting in tedious model updating and deployment works. This paper implements a lightweight MLOps plugin, termed ModelCI-e (continuous integration and evolution), to address the issue. Specifically, it embraces continual learning (CL) and ML deployment techniques, providing end-to-end supports for model updating and validation without serving engine customization. ModelCI-e includes 1) a model factory that allows CL researchers to prototype and benchmark CL models with ease, 2) a CL backend to automate and orchestrate the model updating efficiently, and 3) a web interface for an ML team to manage CL service collaboratively. Our preliminary results demonstrate the usability of ModelCI-e, and indicate that eliminating the interference between model updating and inference workloads is crucial for higher system efficiency.
ModelPS: An Interactive and Collaborative Platform for Editing Pre-trained Models at Scale
May 26, 2021
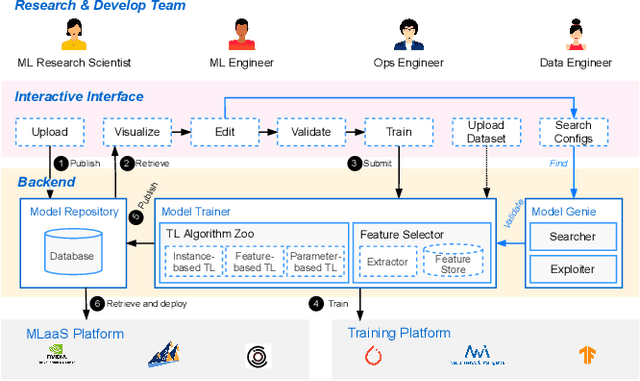
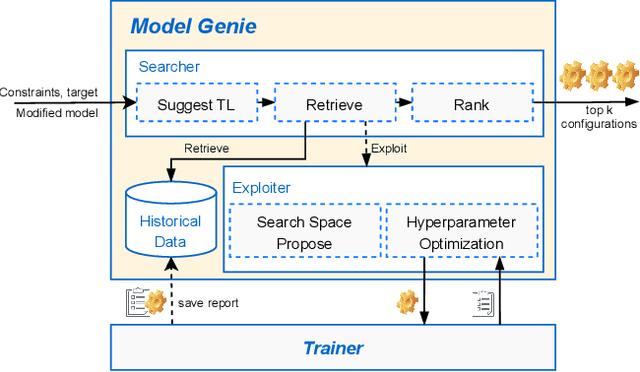
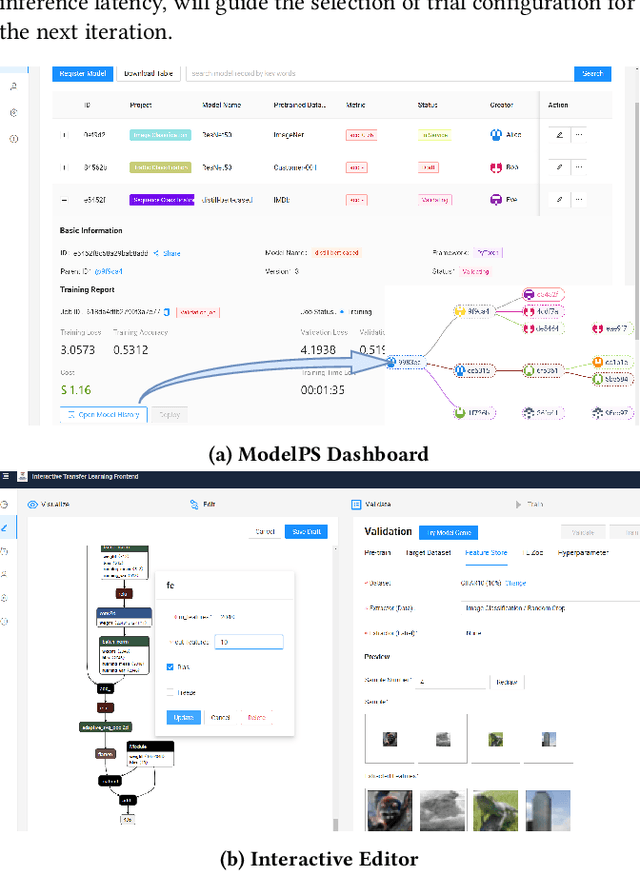
AI engineering has emerged as a crucial discipline to democratize deep neural network (DNN) models among software developers with a diverse background. In particular, altering these DNN models in the deployment stage posits a tremendous challenge. In this research, we propose and develop a low-code solution, ModelPS (an acronym for "Model Photoshop"), to enable and empower collaborative DNN model editing and intelligent model serving. The ModelPS solution embodies two transformative features: 1) a user-friendly web interface for a developer team to share and edit DNN models pictorially, in a low-code fashion, and 2) a model genie engine in the backend to aid developers in customizing model editing configurations for given deployment requirements or constraints. Our case studies with a wide range of deep learning (DL) models show that the system can tremendously reduce both development and communication overheads with improved productivity. The code has been released as an open-source package at GitHub.
A Serverless Cloud-Fog Platform for DNN-Based Video Analytics with Incremental Learning
Feb 05, 2021
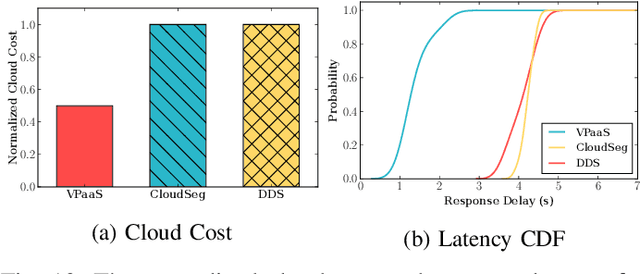
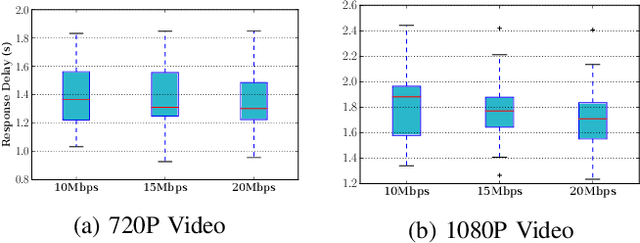
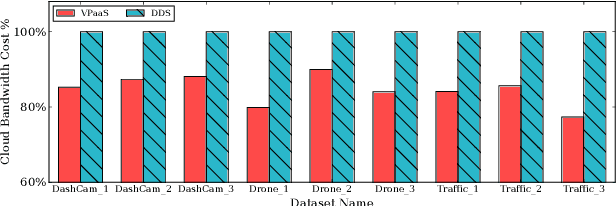
DNN-based video analytics have empowered many new applications (e.g., automated retail). Meanwhile, the proliferation of fog devices provides developers with more design options to improve performance and save cost. To the best of our knowledge, this paper presents the first serverless system that takes full advantage of the client-fog-cloud synergy to better serve the DNN-based video analytics. Specifically, the system aims to achieve two goals: 1) Provide the optimal analytics results under the constraints of lower bandwidth usage and shorter round-trip time (RTT) by judiciously managing the computational and bandwidth resources deployed in the client, fog, and cloud environment. 2) Free developers from tedious administration and operation tasks, including DNN deployment, cloud and fog's resource management. To this end, we implement a holistic cloud-fog system referred to as VPaaS (Video-Platform-as-a-Service). VPaaS adopts serverless computing to enable developers to build a video analytics pipeline by simply programming a set of functions (e.g., model inference), which are then orchestrated to process videos through carefully designed modules. To save bandwidth and reduce RTT, VPaaS provides a new video streaming protocol that only sends low-quality video to the cloud. The state-of-the-art (SOTA) DNNs deployed at the cloud can identify regions of video frames that need further processing at the fog ends. At the fog ends, misidentified labels in these regions can be corrected using a light-weight DNN model. To address the data drift issues, we incorporate limited human feedback into the system to verify the results and adopt incremental learning to improve our system continuously. The evaluation demonstrates that VPaaS is superior to several SOTA systems: it maintains high accuracy while reducing bandwidth usage by up to 21%, RTT by up to 62.5%, and cloud monetary cost by up to 50%.
No more 996: Understanding Deep Learning Inference Serving with an Automatic Benchmarking System
Nov 12, 2020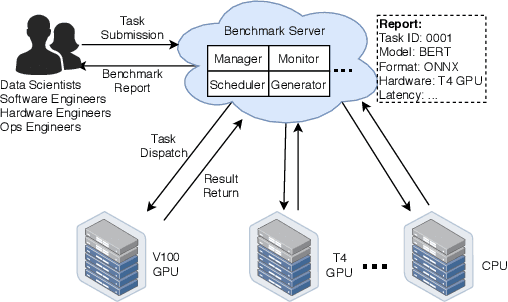

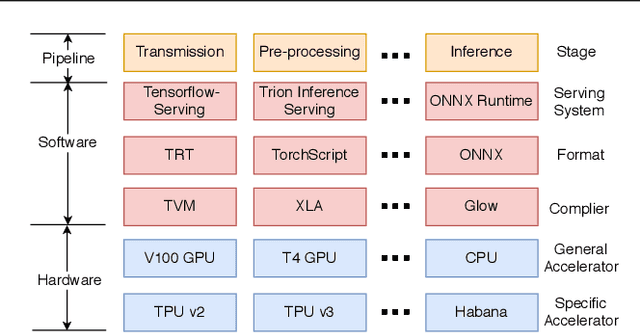
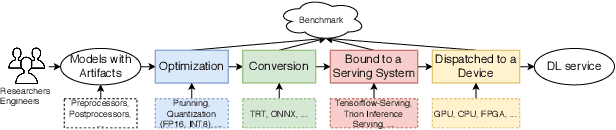
Deep learning (DL) models have become core modules for many applications. However, deploying these models without careful performance benchmarking that considers both hardware and software's impact often leads to poor service and costly operational expenditure. To facilitate DL models' deployment, we implement an automatic and comprehensive benchmark system for DL developers. To accomplish benchmark-related tasks, the developers only need to prepare a configuration file consisting of a few lines of code. Our system, deployed to a leader server in DL clusters, will dispatch users' benchmark jobs to follower workers. Next, the corresponding requests, workload, and even models can be generated automatically by the system to conduct DL serving benchmarks. Finally, developers can leverage many analysis tools and models in our system to gain insights into the trade-offs of different system configurations. In addition, a two-tier scheduler is incorporated to avoid unnecessary interference and improve average job compilation time by up to 1.43x (equivalent of 30\% reduction). Our system design follows the best practice in DL clusters operations to expedite day-to-day DL service evaluation efforts by the developers. We conduct many benchmark experiments to provide in-depth and comprehensive evaluations. We believe these results are of great values as guidelines for DL service configuration and resource allocation.