 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Piecewise Curves Estimation for Photo Enhancement
Oct 26, 2020
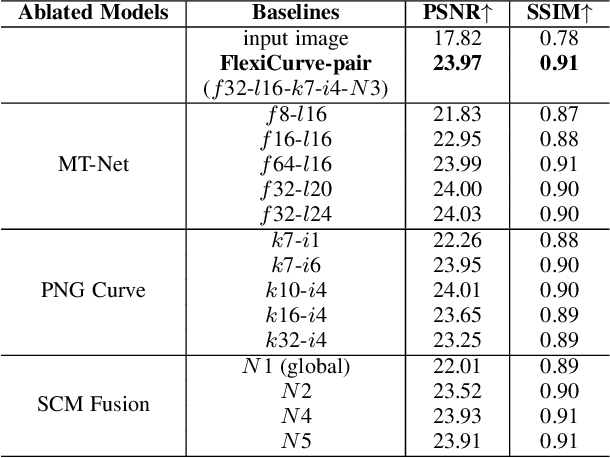


This paper presents a new method, called FlexiCurve, for photo enhancement. Unlike most existing methods that perform image-to-image mapping, which requires expensive pixel-wise reconstruction, FlexiCurve takes an input image and estimates global curves to adjust the image. The adjustment curves are specially designed for performing piecewise mapping, taking nonlinear adjustment and differentiability into account. To cope with challenging and diverse illumination properties in real-world images, FlexiCurve is formulated as a multi-task framework to produce diverse estimations and the associated confidence maps. These estimations are adaptively fused to improve local enhancements of different regions. Thanks to the image-to-curve formulation, for an image with a size of 512*512*3, FlexiCurve only needs a lightweight network (150K trainable parameters) and it has a fast inference speed (83FPS on a single NVIDIA 2080Ti GPU). The proposed method improves efficiency without compromising the enhancement quality and losing details in the original image. The method is also appealing as it is not limited to paired training data, thus it can flexibly learn rich enhancement styles from unpaired data. Extensive experiments demonstrate that our method achieves state-of-the-art performance on photo enhancement quantitively and qualitatively.
Hysia: Serving DNN-Based Video-to-Retail Applications in Cloud
Jun 09, 2020

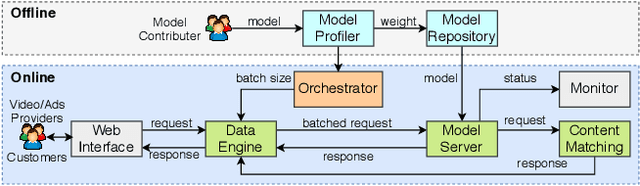
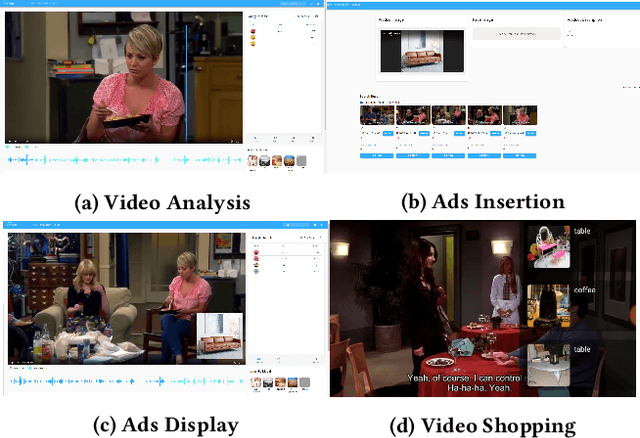
Combining \underline{v}ideo streaming and online \underline{r}etailing (V2R) has been a growing trend recently. In this paper, we provide practitioners and researchers in multimedia with a cloud-based platform named Hysia for easy development and deployment of V2R applications. The system consists of: 1) a back-end infrastructure providing optimized V2R related services including data engine, model repository, model serving and content matching; and 2) an application layer which enables rapid V2R application prototyping. Hysia addresses industry and academic needs in large-scale multimedia by: 1) seamlessly integrating state-of-the-art libraries including NVIDIA video SDK, Facebook faiss, and gRPC; 2) efficiently utilizing GPU computation; and 3) allowing developers to bind new models easily to meet the rapidly changing deep learning (DL) techniques. On top of that, we implement an orchestrator for further optimizing DL model serving performance. Hysia has been released as an open source project on GitHub, and attracted considerable attention. We have published Hysia to DockerHub as an official image for seamless integration and deployment in current cloud environments.
Look, Read and Feel: Benchmarking Ads Understanding with Multimodal Multitask Learning
Jan 03, 2020

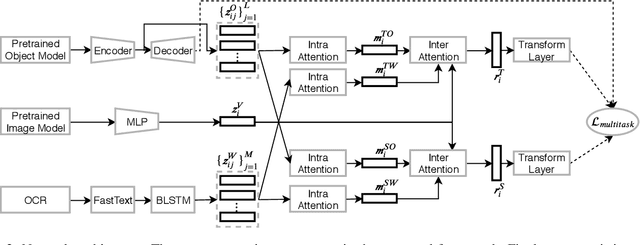
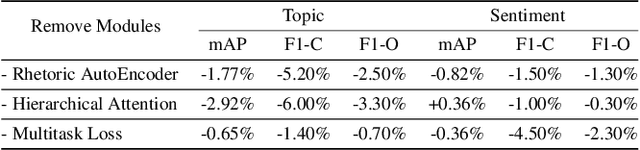
Given the massive market of advertising and the sharply increasing online multimedia content (such as videos), it is now fashionable to promote advertisements (ads) together with the multimedia content. It is exhausted to find relevant ads to match the provided content manually, and hence, some automatic advertising techniques are developed. Since ads are usually hard to understand only according to its visual appearance due to the contained visual metaphor, some other modalities, such as the contained texts, should be exploited for understanding. To further improve user experience, it is necessary to understand both the topic and sentiment of the ads. This motivates us to develop a novel deep multimodal multitask framework to integrate multiple modalities to achieve effective topic and sentiment prediction simultaneously for ads understanding. In particular, our model first extracts multimodal information from ads and learn high-level and comparable representations. The visual metaphor of the ad is decoded in an unsupervised manner. The obtained representations are then fed into the proposed hierarchical multimodal attention modules to learn task-specific representations for final prediction. A multitask loss function is also designed to train both the topic and sentiment prediction models jointly in an end-to-end manner. We conduct extensive experiments on the latest and large advertisement dataset and achieve state-of-the-art performance for both prediction tasks. The obtained results could be utilized as a benchmark for ads understanding.