 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Loop Control in DCVerse: Advancing Reliable Deployment of AI in Data Centers via Digital Twins
Apr 08, 2026The growing scale and complexity of modern data centers present major challenges in balancing energy efficiency with outage risk. Although Deep Reinforcement Learning (DRL) shows strong potential for intelligent control, its deployment in mission-critical systems is limited by data scarcity and the lack of real-time pre-evaluation mechanisms. This paper introduces the Dual-Loop Control Framework (DLCF), a digital twin-based architecture designed to overcome these challenges. The framework comprises three core entities: the physical system, a digital twin, and a policy reservoir of diverse DRL agents. These components interact through a dual-loop mechanism involving real-time data acquisition, data assimilation, DRL policy training, pre-evaluation, and expert verification. Theoretical analysis shows how DLCF can improve sample efficiency, generalization, safety, and optimality. Leveraging DLCF, we implemented the DCVerse platform and validated it through case studies on a real-world data center cooling system. The evaluation shows that our approach achieves up to 4.09% energy savings over conventional control strategies without violating SLA requirements. Additionally, the framework improves policy interpretability and supports more trustworthy DRL deployment. This work provides a foundation for reliable AI-based control in data centers and points toward future extensions for holistic, system-wide optimization.
SpecForge: A Flexible and Efficient Open-Source Training Framework for Speculative Decoding
Mar 19, 2026Large language models incur high inference latency due to sequential autoregressive decoding. Speculative decoding alleviates this bottleneck by using a lightweight draft model to propose multiple tokens for batched verification. However, its adoption has been limited by the lack of high-quality draft models and scalable training infrastructure. We introduce SpecForge, an open-source, production-oriented framework for training speculative decoding models with full support for EAGLE-3. SpecForge incorporates target-draft decoupling, hybrid parallelism, optimized training kernels, and integration with production-grade inference engines, enabling up to 9.9x faster EAGLE-3 training for Qwen3-235B-A22B. In addition, we release SpecBundle, a suite of production-grade EAGLE-3 draft models trained with SpecForge for mainstream open-source LLMs. Through a systematic study of speculative decoding training recipes, SpecBundle addresses the scarcity of high-quality drafts in the community, and our draft models achieve up to 4.48x end-to-end inference speedup on SGLang, establishing SpecForge as a practical foundation for real-world speculative decoding deployment.
DSB: Dynamic Sliding Block Scheduling for Diffusion LLMs
Feb 05, 2026Diffusion large language models (dLLMs) have emerged as a promising alternative for text generation, distinguished by their native support for parallel decoding. In practice, block inference is crucial for avoiding order misalignment in global bidirectional decoding and improving output quality. However, the widely-used fixed, predefined block (naive) schedule is agnostic to semantic difficulty, making it a suboptimal strategy for both quality and efficiency: it can force premature commitments to uncertain positions while delaying easy positions near block boundaries. In this work, we analyze the limitations of naive block scheduling and disclose the importance of dynamically adapting the schedule to semantic difficulty for reliable and efficient inference. Motivated by this, we propose Dynamic Sliding Block (DSB), a training-free block scheduling method that uses a sliding block with a dynamic size to overcome the rigidity of the naive block. To further improve efficiency, we introduce DSB Cache, a training-free KV-cache mechanism tailored to DSB. Extensive experiments across multiple models and benchmarks demonstrate that DSB, together with DSB Cache, consistently improves both generation quality and inference efficiency for dLLMs. Code is released at https://github.com/lizhuo-luo/DSB.
DCoPilot: Generative AI-Empowered Policy Adaptation for Dynamic Data Center Operations
Feb 03, 2026Modern data centers (DCs) hosting artificial intelligence (AI)-dedicated devices operate at high power densities with rapidly varying workloads, making minute-level adaptation essential for safe and energy-efficient operation. However, manually designing piecewise deep reinforcement learning (DRL) agents cannot keep pace with frequent dynamics shifts and service-level agreement (SLA) changes of an evolving DC. This specification-to-policy lag causes a lack of timely, effective control policies, which may lead to service outages. To bridge the gap, we present DCoPilot, a hybrid framework for generative control policies in dynamic DC operation. DCoPilot synergizes two distinct generative paradigms, i.e., a large language model (LLM) that performs symbolic generation of structured reward forms, and a hypernetwork that conducts parametric generation of policy weights. DCoPilot operates through three coordinated phases: (i) simulation scale-up, which stress-tests reward candidates across diverse simulation-ready (SimReady) scenes; (ii) meta policy distillation, where a hypernetwork is trained to output policy weights conditioned on SLA and scene embeddings; and (iii) online adaptation, enabling zero-shot policy generation in response to updated specifications. Evaluated across five control task families spanning diverse DC components, DCoPilot achieves near-zero constraint violations and outperforms all baselines across specification variations. Ablation studies validate the effectiveness of LLM-based unified reward generation in enabling stable hypernetwork convergence.
SOPRAG: Multi-view Graph Experts Retrieval for Industrial Standard Operating Procedures
Feb 02, 2026Standard Operating Procedures (SOPs) are essential for ensuring operational safety and consistency in industrial environments. However, retrieving and following these procedures presents unique challenges, such as rigid proprietary structures, condition-dependent relevance, and actionable execution requirement, which standard semantic-driven Retrieval-Augmented Generation (RAG) paradigms fail to address. Inspired by the Mixture-of-Experts (MoE) paradigm, we propose SOPRAG, a novel framework specifically designed to address the above pain points in SOP retrieval. SOPRAG replaces flat chunking with specialized Entity, Causal, and Flow graph experts to resolve industrial structural and logical complexities. To optimize and coordinate these experts, we propose a Procedure Card layer that prunes the search space to eliminate computational noise, and an LLM-Guided gating mechanism that dynamically weights these experts to align retrieval with operator intent. To address the scarcity of domain-specific data, we also introduce an automated, multi-agent workflow for benchmark construction. Extensive experiments across four industrial domains demonstrate that SOPRAG significantly outperforms strong lexical, dense, and graph-based RAG baselines in both retrieval accuracy and response utility, achieving perfect execution scores in real-world critical tasks.
Phythesis: Physics-Guided Evolutionary Scene Synthesis for Energy-Efficient Data Center Design via LLMs
Dec 15, 2025Data center (DC) infrastructure serves as the backbone to support the escalating demand for computing capacity. Traditional design methodologies that blend human expertise with specialized simulation tools scale poorly with the increasing system complexity. Recent studies adopt generative artificial intelligence to design plausible human-centric indoor layouts. However, they do not consider the underlying physics, making them unsuitable for the DC design that sets quantifiable operational objectives and strict physical constraints. To bridge the gap, we propose Phythesis, a novel framework that synergizes large language models (LLMs) and physics-guided evolutionary optimization to automate simulation-ready (SimReady) scene synthesis for energy-efficient DC design. Phythesis employs an iterative bi-level optimization architecture, where (i) the LLM-driven optimization level generates physically plausible three-dimensional layouts and self-criticizes them to refine the scene topology, and (ii) the physics-informed optimization level identifies the optimal asset parameters and selects the best asset combination. Experiments on three generation scales show that Phythesis achieves 57.3% generation success rate increase and 11.5% power usage effectiveness (PUE) improvement, compared with the vanilla LLM-based solution.
ReSpec: Towards Optimizing Speculative Decoding in Reinforcement Learning Systems
Oct 30, 2025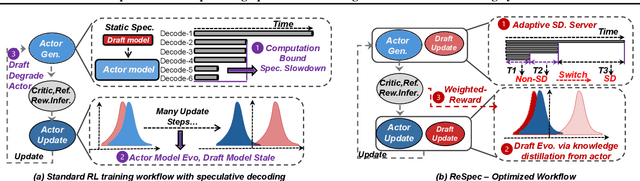


Adapting large language models (LLMs) via reinforcement learning (RL) is often bottlenecked by the generation stage, which can consume over 75\% of the training time. Speculative decoding (SD) accelerates autoregressive generation in serving systems, but its behavior under RL training remains largely unexplored. We identify three critical gaps that hinder the naive integration of SD into RL systems: diminishing speedups at large batch sizes, drafter staleness under continual actor updates, and drafter-induced policy degradation. To address these gaps, we present ReSpec, a system that adapts SD to RL through three complementary mechanisms: dynamically tuning SD configurations, evolving the drafter via knowledge distillation, and weighting updates by rollout rewards. On Qwen models (3B--14B), ReSpec achieves up to 4.5x speedup while preserving reward convergence and training stability, providing a practical solution for efficient RL-based LLM adaptation.
Toward Physics-Informed Machine Learning for Data Center Operations: A Tropical Case Study
May 26, 2025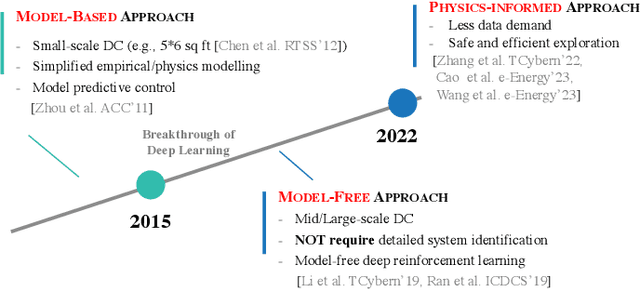
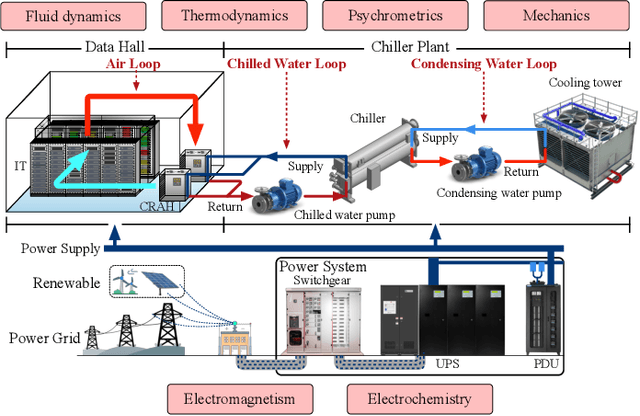
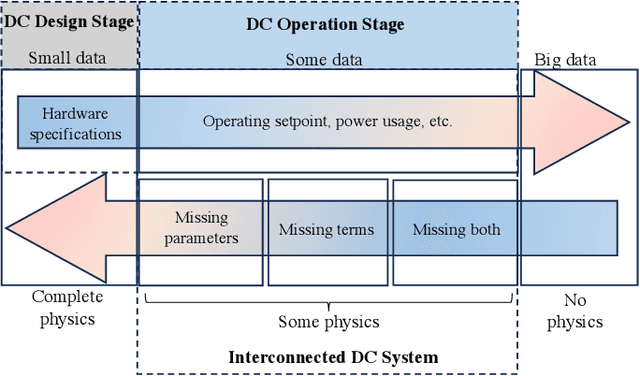
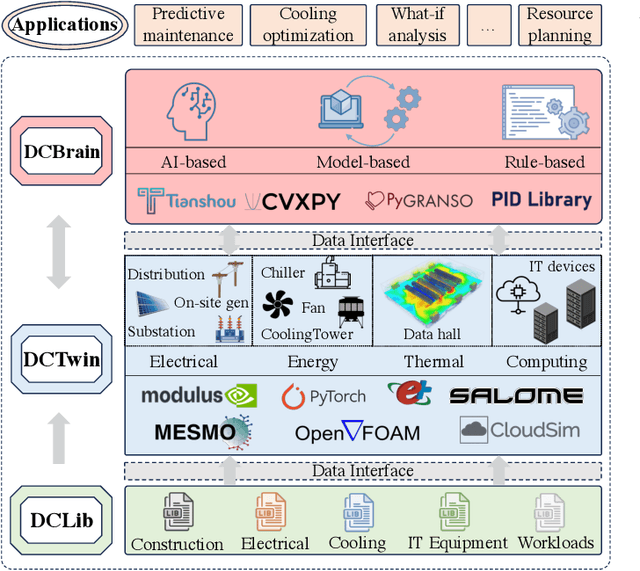
Data centers are the backbone of computing capacity. Operating data centers in the tropical regions faces unique challenges due to consistently high ambient temperature and elevated relative humidity throughout the year. These conditions result in increased cooling costs to maintain the reliability of the computing systems. While existing machine learning-based approaches have demonstrated potential to elevate operations to a more proactive and intelligent level, their deployment remains dubious due to concerns about model extrapolation capabilities and associated system safety issues. To address these concerns, this article proposes incorporating the physical characteristics of data centers into traditional data-driven machine learning solutions. We begin by introducing the data center system, including the relevant multiphysics processes and the data-physics availability. Next, we outline the associated modeling and optimization problems and propose an integrated, physics-informed machine learning system to address them. Using the proposed system, we present relevant applications across varying levels of operational intelligence. A case study on an industry-grade tropical data center is provided to demonstrate the effectiveness of our approach. Finally, we discuss key challenges and highlight potential future directions.
Fusion Intelligence for Digital Twinning AI Data Centers: A Synergistic GenAI-PhyAI Approach
May 26, 2025The explosion in artificial intelligence (AI) applications is pushing the development of AI-dedicated data centers (AIDCs), creating management challenges that traditional methods and standalone AI solutions struggle to address. While digital twins are beneficial for AI-based design validation and operational optimization, current AI methods for their creation face limitations. Specifically, physical AI (PhyAI) aims to capture the underlying physical laws, which demands extensive, case-specific customization, and generative AI (GenAI) can produce inaccurate or hallucinated results. We propose Fusion Intelligence, a novel framework synergizing GenAI's automation with PhyAI's domain grounding. In this dual-agent collaboration, GenAI interprets natural language prompts to generate tokenized AIDC digital twins. Subsequently, PhyAI optimizes these generated twins by enforcing physical constraints and assimilating real-time data. Case studies demonstrate the advantages of our framework in automating the creation and validation of AIDC digital twins. These twins deliver predictive analytics to support power usage effectiveness (PUE) optimization in the design stage. With operational data collected, the digital twin accuracy is further improved compared with pure physics-based models developed by human experts. Fusion Intelligence offers a promising pathway to accelerate digital transformation. It enables more reliable and efficient AI-driven digital transformation for a broad range of mission-critical infrastructures.
Low-Precision Training of Large Language Models: Methods, Challenges, and Opportunities
May 02, 2025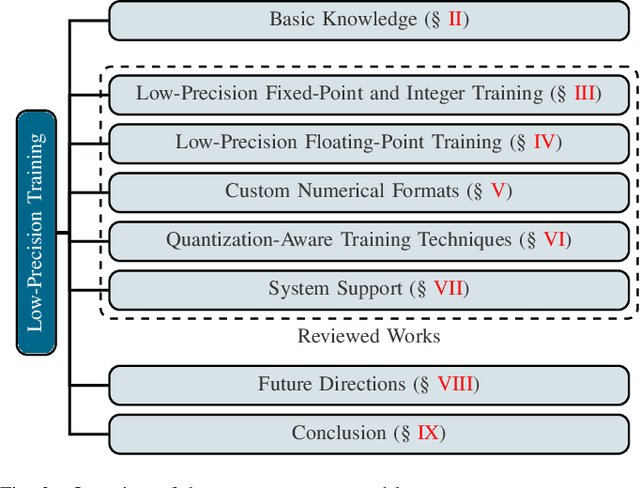
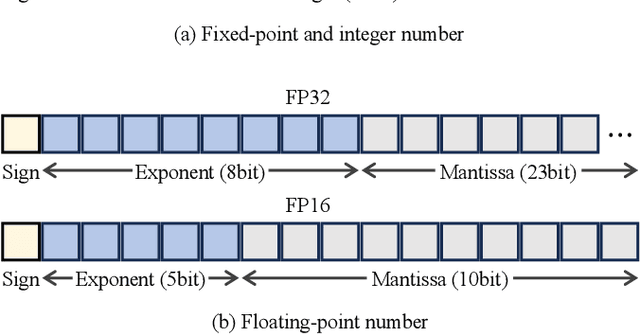
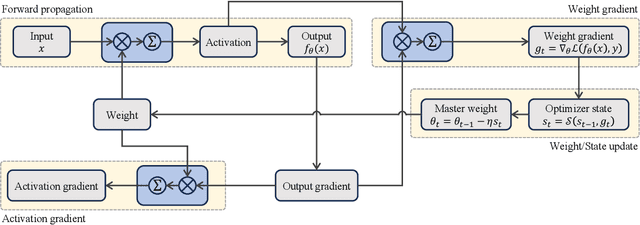
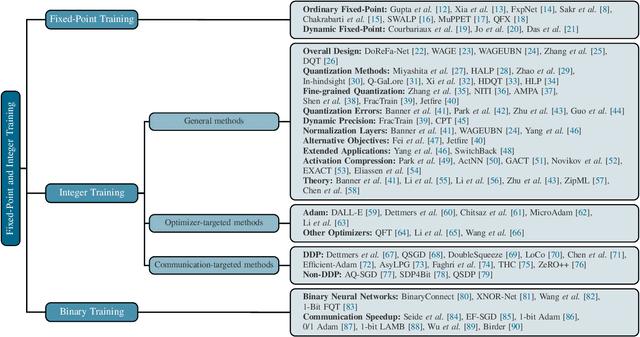
Large language models (LLMs) have achieved impressive performance across various domains. However, the substantial hardware resources required for their training present a significant barrier to efficiency and scalability. To mitigate this challenge, low-precision training techniques have been widely adopted, leading to notable advancements in training efficiency. Despite these gains, low-precision training involves several components$\unicode{x2013}$such as weights, activations, and gradients$\unicode{x2013}$each of which can be represented in different numerical formats. The resulting diversity has created a fragmented landscape in low-precision training research, making it difficult for researchers to gain a unified overview of the field. This survey provides a comprehensive review of existing low-precision training methods. To systematically organize these approaches, we categorize them into three primary groups based on their underlying numerical formats, which is a key factor influencing hardware compatibility, computational efficiency, and ease of reference for readers. The categories are: (1) fixed-point and integer-based methods, (2) floating-point-based methods, and (3) customized format-based methods. Additionally, we discuss quantization-aware training approaches, which share key similarities with low-precision training during forward propagation. Finally, we highlight several promising research directions to advance this field. A collection of papers discussed in this survey is provided in https://github.com/Hao840/Awesome-Low-Precision-Training.