 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion Intelligence for Digital Twinning AI Data Centers: A Synergistic GenAI-PhyAI Approach
May 26, 2025The explosion in artificial intelligence (AI) applications is pushing the development of AI-dedicated data centers (AIDCs), creating management challenges that traditional methods and standalone AI solutions struggle to address. While digital twins are beneficial for AI-based design validation and operational optimization, current AI methods for their creation face limitations. Specifically, physical AI (PhyAI) aims to capture the underlying physical laws, which demands extensive, case-specific customization, and generative AI (GenAI) can produce inaccurate or hallucinated results. We propose Fusion Intelligence, a novel framework synergizing GenAI's automation with PhyAI's domain grounding. In this dual-agent collaboration, GenAI interprets natural language prompts to generate tokenized AIDC digital twins. Subsequently, PhyAI optimizes these generated twins by enforcing physical constraints and assimilating real-time data. Case studies demonstrate the advantages of our framework in automating the creation and validation of AIDC digital twins. These twins deliver predictive analytics to support power usage effectiveness (PUE) optimization in the design stage. With operational data collected, the digital twin accuracy is further improved compared with pure physics-based models developed by human experts. Fusion Intelligence offers a promising pathway to accelerate digital transformation. It enables more reliable and efficient AI-driven digital transformation for a broad range of mission-critical infrastructures.
A Serverless Cloud-Fog Platform for DNN-Based Video Analytics with Incremental Learning
Feb 05, 2021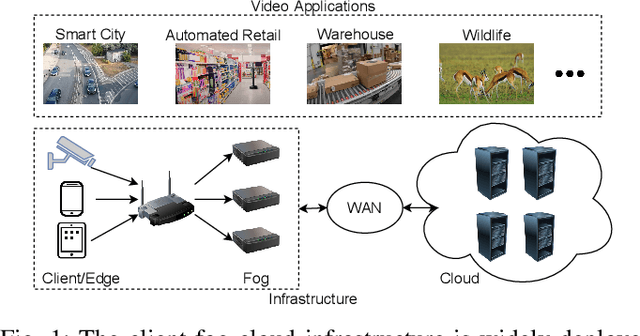
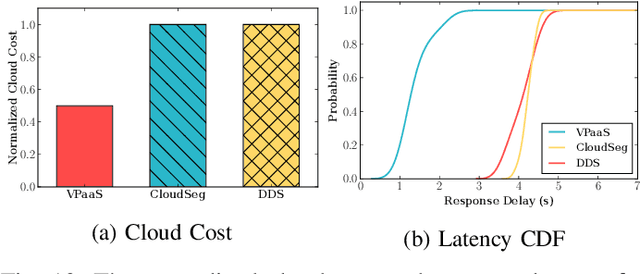
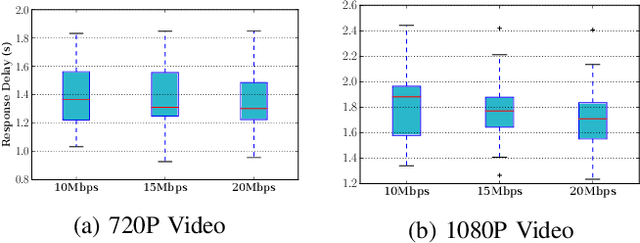
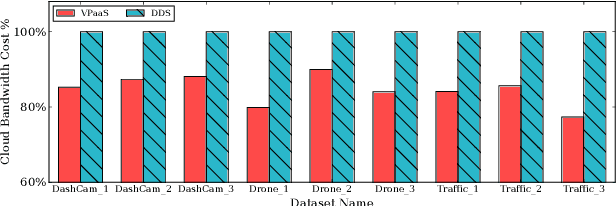
DNN-based video analytics have empowered many new applications (e.g., automated retail). Meanwhile, the proliferation of fog devices provides developers with more design options to improve performance and save cost. To the best of our knowledge, this paper presents the first serverless system that takes full advantage of the client-fog-cloud synergy to better serve the DNN-based video analytics. Specifically, the system aims to achieve two goals: 1) Provide the optimal analytics results under the constraints of lower bandwidth usage and shorter round-trip time (RTT) by judiciously managing the computational and bandwidth resources deployed in the client, fog, and cloud environment. 2) Free developers from tedious administration and operation tasks, including DNN deployment, cloud and fog's resource management. To this end, we implement a holistic cloud-fog system referred to as VPaaS (Video-Platform-as-a-Service). VPaaS adopts serverless computing to enable developers to build a video analytics pipeline by simply programming a set of functions (e.g., model inference), which are then orchestrated to process videos through carefully designed modules. To save bandwidth and reduce RTT, VPaaS provides a new video streaming protocol that only sends low-quality video to the cloud. The state-of-the-art (SOTA) DNNs deployed at the cloud can identify regions of video frames that need further processing at the fog ends. At the fog ends, misidentified labels in these regions can be corrected using a light-weight DNN model. To address the data drift issues, we incorporate limited human feedback into the system to verify the results and adopt incremental learning to improve our system continuously. The evaluation demonstrates that VPaaS is superior to several SOTA systems: it maintains high accuracy while reducing bandwidth usage by up to 21%, RTT by up to 62.5%, and cloud monetary cost by up to 50%.
No more 996: Understanding Deep Learning Inference Serving with an Automatic Benchmarking System
Nov 12, 2020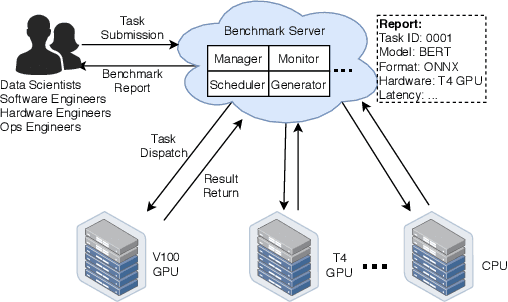

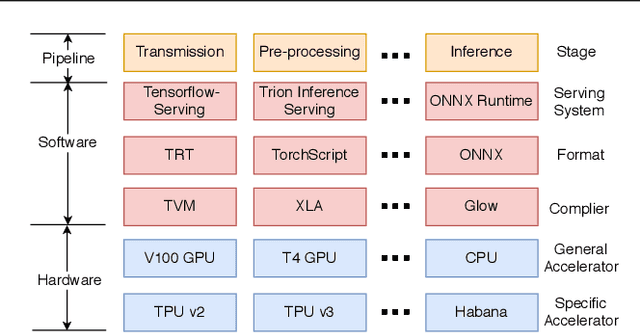
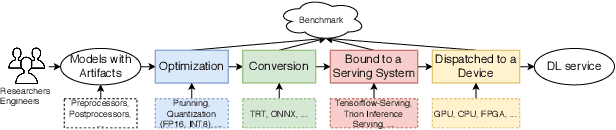
Deep learning (DL) models have become core modules for many applications. However, deploying these models without careful performance benchmarking that considers both hardware and software's impact often leads to poor service and costly operational expenditure. To facilitate DL models' deployment, we implement an automatic and comprehensive benchmark system for DL developers. To accomplish benchmark-related tasks, the developers only need to prepare a configuration file consisting of a few lines of code. Our system, deployed to a leader server in DL clusters, will dispatch users' benchmark jobs to follower workers. Next, the corresponding requests, workload, and even models can be generated automatically by the system to conduct DL serving benchmarks. Finally, developers can leverage many analysis tools and models in our system to gain insights into the trade-offs of different system configurations. In addition, a two-tier scheduler is incorporated to avoid unnecessary interference and improve average job compilation time by up to 1.43x (equivalent of 30\% reduction). Our system design follows the best practice in DL clusters operations to expedite day-to-day DL service evaluation efforts by the developers. We conduct many benchmark experiments to provide in-depth and comprehensive evaluations. We believe these results are of great values as guidelines for DL service configuration and resource allocation.
MLModelCI: An Automatic Cloud Platform for Efficient MLaaS
Jun 09, 2020



MLModelCI provides multimedia researchers and developers with a one-stop platform for efficient machine learning (ML) services. The system leverages DevOps techniques to optimize, test, and manage models. It also containerizes and deploys these optimized and validated models as cloud services (MLaaS). In its essence, MLModelCI serves as a housekeeper to help users publish models. The models are first automatically converted to optimized formats for production purpose and then profiled under different settings (e.g., batch size and hardware). The profiling information can be used as guidelines for balancing the trade-off between performance and cost of MLaaS. Finally, the system dockerizes the models for ease of deployment to cloud environments. A key feature of MLModelCI is the implementation of a controller, which allows elastic evaluation which only utilizes idle workers while maintaining online service quality. Our system bridges the gap between current ML training and serving systems and thus free developers from manual and tedious work often associated with service deployment. We release the platform as an open-source project on GitHub under Apache 2.0 license, with the aim that it will facilitate and streamline more large-scale ML applications and research projects.
Transforming Cooling Optimization for Green Data Center via Deep Reinforcement Learning
Jul 18, 2018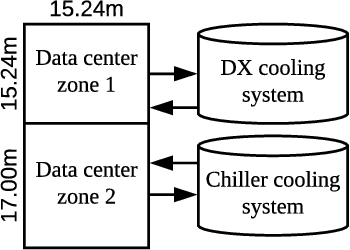
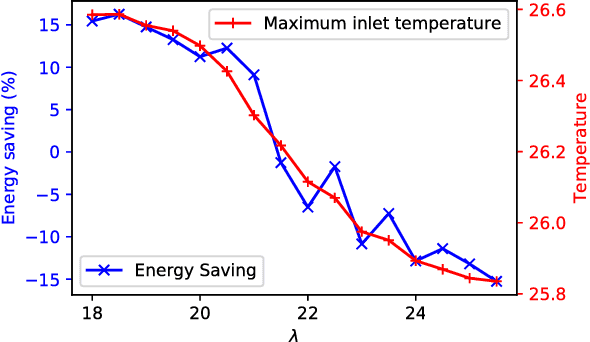
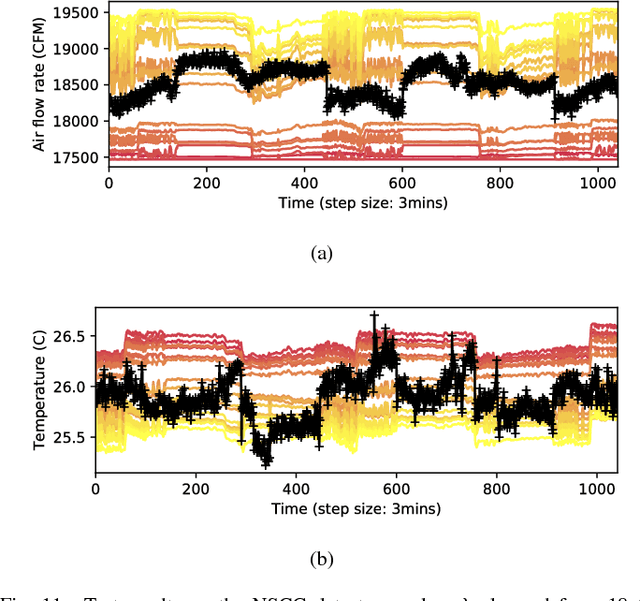
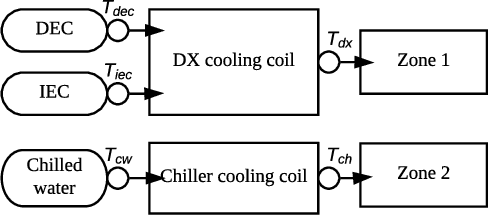
Cooling system plays a critical role in a modern data center (DC). Developing an optimal control policy for DC cooling system is a challenging task. The prevailing approaches often rely on approximating system models that are built upon the knowledge of mechanical cooling, electrical and thermal management, which is difficult to design and may lead to sub-optimal or unstable performances. In this paper, we propose utilizing the large amount of monitoring data in DC to optimize the control policy. To do so, we cast the cooling control policy design into an energy cost minimization problem with temperature constraints, and tap it into the emerging deep reinforcement learning (DRL) framework. Specifically, we propose an end-to-end cooling control algorithm (CCA) that is based on the actor-critic framework and an off-policy offline version of the deep deterministic policy gradient (DDPG) algorithm. In the proposed CCA, an evaluation network is trained to predict an energy cost counter penalized by the cooling status of the DC room, and a policy network is trained to predict optimized control settings when gave the current load and weather information. The proposed algorithm is evaluated on the EnergyPlus simulation platform and on a real data trace collected from the National Super Computing Centre (NSCC) of Singapore. Our results show that the proposed CCA can achieve about 11% cooling cost saving on the simulation platform compared with a manually configured baseline control algorithm. In the trace-based study, we propose a de-underestimation validation mechanism as we cannot directly test the algorithm on a real DC. Even though with DUE the results are conservative, we can still achieve about 15% cooling energy saving on the NSCC data trace if we set the inlet temperature threshold at 26.6 degree Celsius.
Intelligent Trainer for Model-Based Reinforcement Learning
May 29, 2018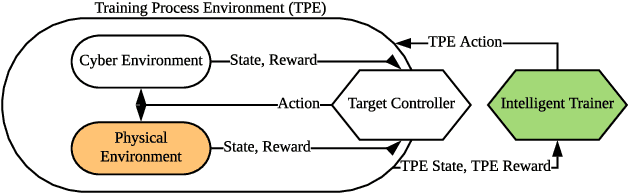

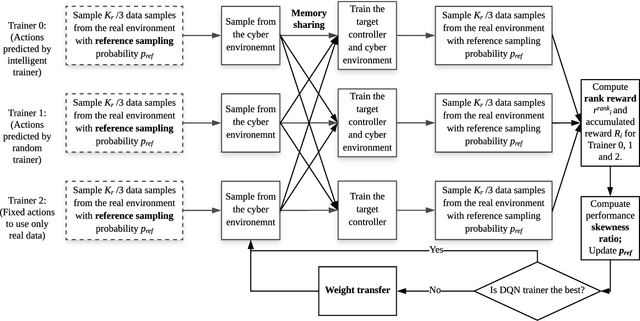
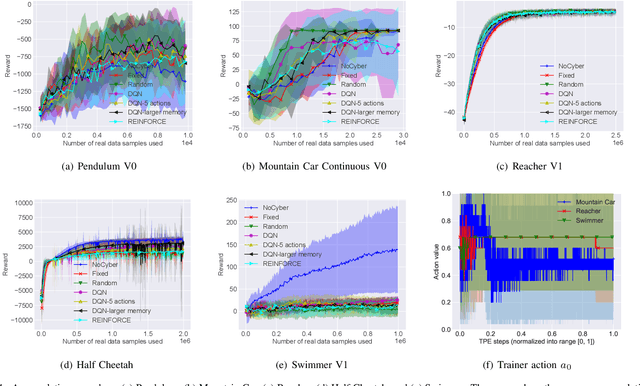
Model-based deep reinforcement learning (DRL) algorithm uses the sampled data from a real environment to learn the underlying system dynamics to construct an approximate cyber environment. By using the synthesized data generated from the cyber environment to train the target controller, the training cost can be reduced significantly. In current research, issues such as the applicability of approximate model and the strategy to sample and train from the real and cyber environment have not been fully investigated. To address these issues, we propose to utilize an intelligent trainer to properly use the approximate model and control the sampling and training procedure in the model-based DRL. To do so, we package the training process of a model-based DRL as a standard RL environment, and design an RL trainer to control the training process. The trainer has three control actions: the first action controls where to sample in the real and cyber environment; the second action determines how many data should be sampled from the cyber environment and the third action controls how many times the cyber data should be used to train the target controller. These actions would be controlled manually if without the trainer. The proposed framework is evaluated on five different tasks of OpenAI gym and the test results show that the proposed trainer achieves significant better performance than a fixed parameter model-based RL baseline algorithm. In addition, we compare the performance of the intelligent trainer to a random trainer and prove that the intelligent trainer can indeed learn on the fly. The proposed training framework can be extended to more control actions with more sophisticated trainer design to further reduce the tweak cost of model-based RL algorithms.