 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential Paradigm Shift in Hazard Risk Management: AI-Based Weather Forecast for Tropical Cyclone Hazards
Apr 29, 2024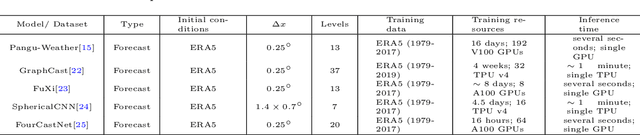
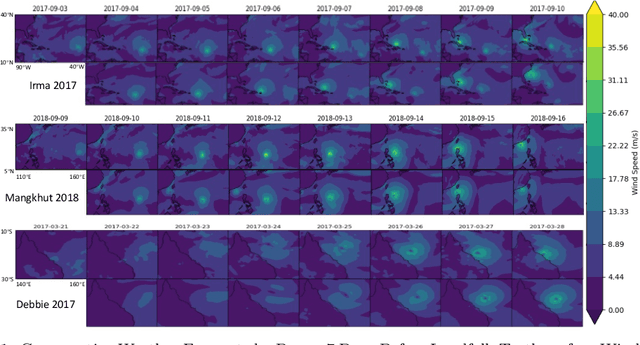
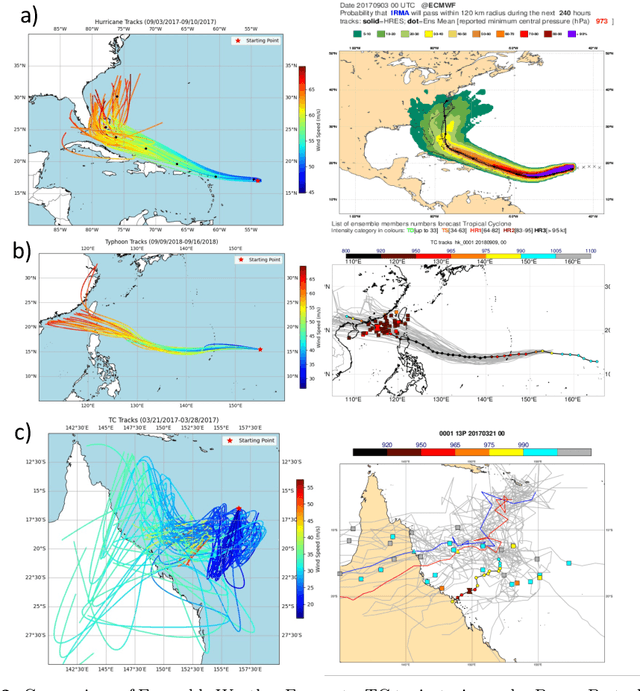
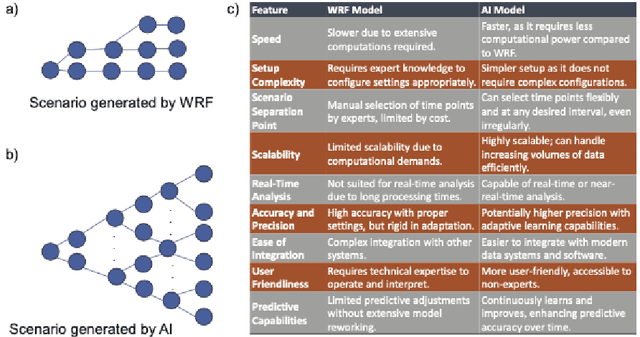
The advents of Artificial Intelligence (AI)-driven models marks a paradigm shift in risk management strategies for meteorological hazards. This study specifically employs tropical cyclones (TCs) as a focal example. We engineer a perturbation-based method to produce ensemble forecasts using the advanced Pangu AI weather model. Unlike traditional approaches that often generate fewer than 20 scenarios from Weather Research and Forecasting (WRF) simulations for one event, our method facilitates the rapid nature of AI-driven model to create thousands of scenarios. We offer open-source access to our model and evaluate its effectiveness through retrospective case studies of significant TC events: Hurricane Irma (2017), Typhoon Mangkhut (2018), and TC Debbie (2017), affecting regions across North America, East Asia, and Australia. Our findings indicate that the AI-generated ensemble forecasts align closely with the European Centre for Medium-Range Weather Forecasts (ECMWF) ensemble predictions up to seven days prior to landfall. This approach could substantially enhance the effectiveness of weather forecast-driven risk analysis and management, providing unprecedented operational speed, user-friendliness, and global applicability.
Deep Explainable Learning with Graph Based Data Assessing and Rule Reasoning
Nov 10, 2022
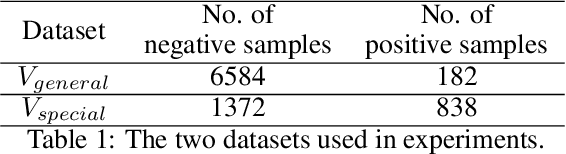


Learning an explainable classifier often results in low accuracy model or ends up with a huge rule set, while learning a deep model is usually more capable of handling noisy data at scale, but with the cost of hard to explain the result and weak at generalization. To mitigate this gap, we propose an end-to-end deep explainable learning approach that combines the advantage of deep model in noise handling and expert rule-based interpretability. Specifically, we propose to learn a deep data assessing model which models the data as a graph to represent the correlations among different observations, whose output will be used to extract key data features. The key features are then fed into a rule network constructed following predefined noisy expert rules with trainable parameters. As these models are correlated, we propose an end-to-end training framework, utilizing the rule classification loss to optimize the rule learning model and data assessing model at the same time. As the rule-based computation is none-differentiable, we propose a gradient linking search module to carry the gradient information from the rule learning model to the data assessing model. The proposed method is tested in an industry production system, showing comparable prediction accuracy, much higher generalization stability and better interpretability when compared with a decent deep ensemble baseline, and shows much better fitting power than pure rule-based approach.
Baconian: A Unified Opensource Framework for Model-Based Reinforcement Learning
Apr 23, 2019
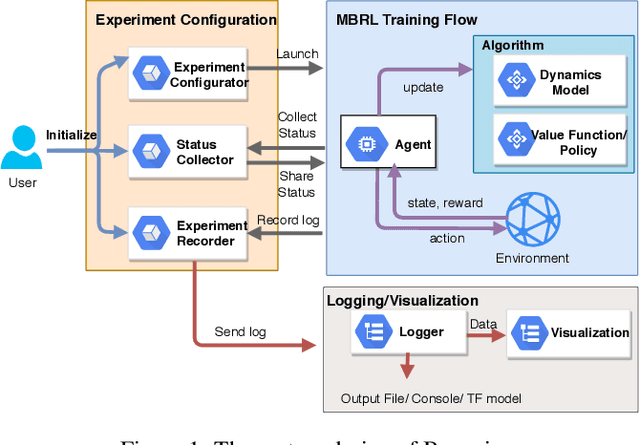
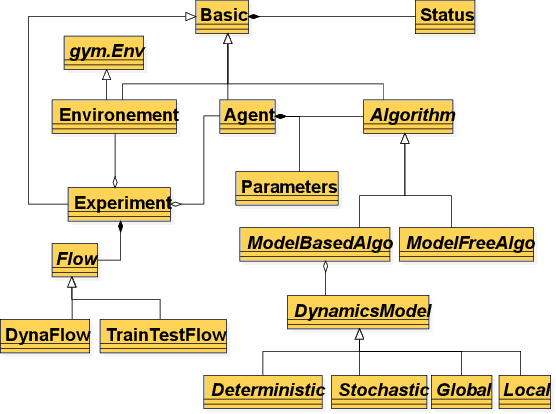
Model-Based Reinforcement Learning (MBRL) is one category of Reinforcement Learning (RL) methods which can improve sampling efficiency by modeling and approximating system dynamics. It has been widely adopted in the research of robotics, autonomous driving, etc. Despite its popularity, there still lacks some sophisticated and reusable opensource frameworks to facilitate MBRL research and experiments. To fill this gap, we develop a flexible and modularized framework, Baconian, which allows researchers to easily implement a MBRL testbed by customizing or building upon our provided modules and algorithms. Our framework can free the users from re-implementing popular MBRL algorithms from scratch thus greatly saves the users' efforts.
Transforming Cooling Optimization for Green Data Center via Deep Reinforcement Learning
Jul 18, 2018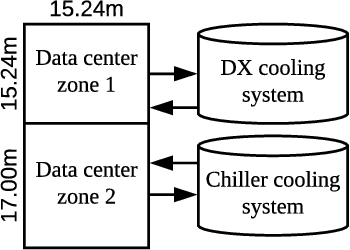
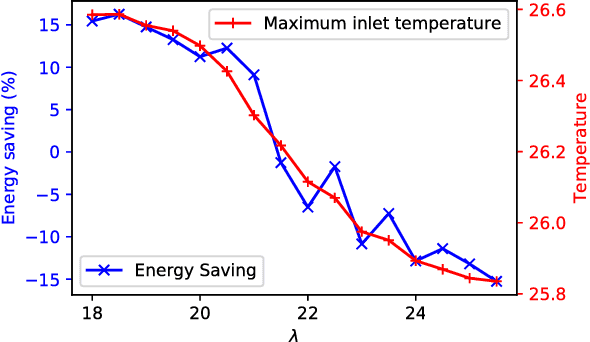
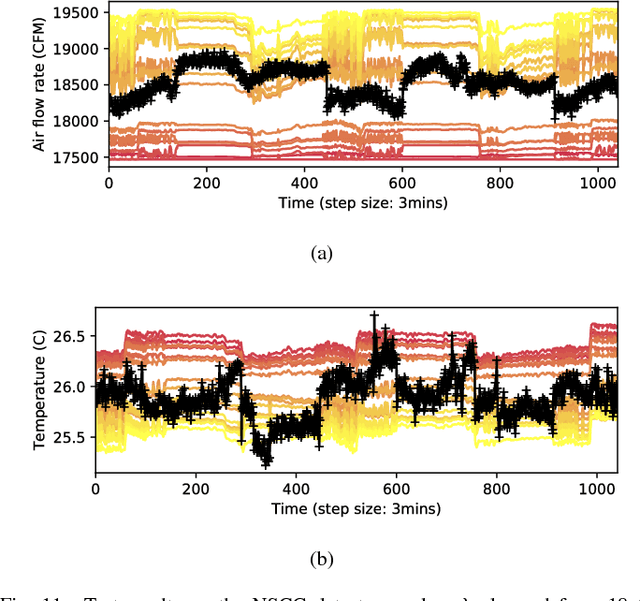
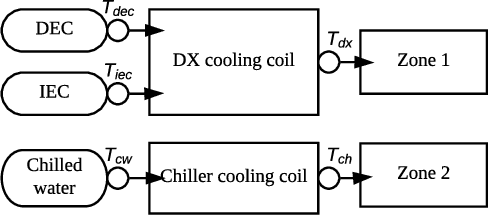
Cooling system plays a critical role in a modern data center (DC). Developing an optimal control policy for DC cooling system is a challenging task. The prevailing approaches often rely on approximating system models that are built upon the knowledge of mechanical cooling, electrical and thermal management, which is difficult to design and may lead to sub-optimal or unstable performances. In this paper, we propose utilizing the large amount of monitoring data in DC to optimize the control policy. To do so, we cast the cooling control policy design into an energy cost minimization problem with temperature constraints, and tap it into the emerging deep reinforcement learning (DRL) framework. Specifically, we propose an end-to-end cooling control algorithm (CCA) that is based on the actor-critic framework and an off-policy offline version of the deep deterministic policy gradient (DDPG) algorithm. In the proposed CCA, an evaluation network is trained to predict an energy cost counter penalized by the cooling status of the DC room, and a policy network is trained to predict optimized control settings when gave the current load and weather information. The proposed algorithm is evaluated on the EnergyPlus simulation platform and on a real data trace collected from the National Super Computing Centre (NSCC) of Singapore. Our results show that the proposed CCA can achieve about 11% cooling cost saving on the simulation platform compared with a manually configured baseline control algorithm. In the trace-based study, we propose a de-underestimation validation mechanism as we cannot directly test the algorithm on a real DC. Even though with DUE the results are conservative, we can still achieve about 15% cooling energy saving on the NSCC data trace if we set the inlet temperature threshold at 26.6 degree Celsius.
Intelligent Trainer for Model-Based Reinforcement Learning
May 29, 2018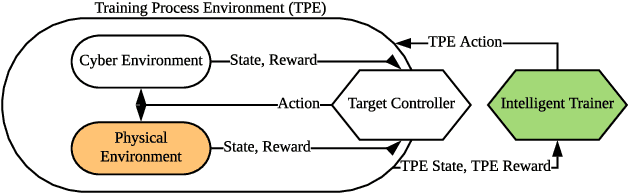

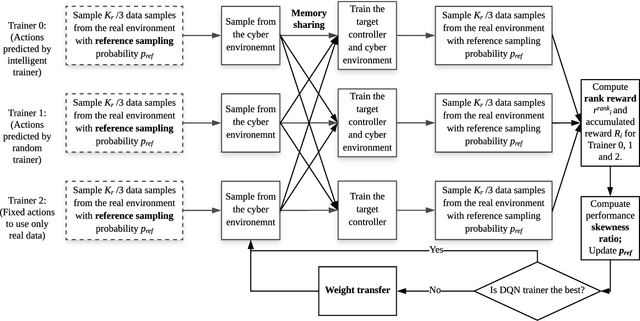
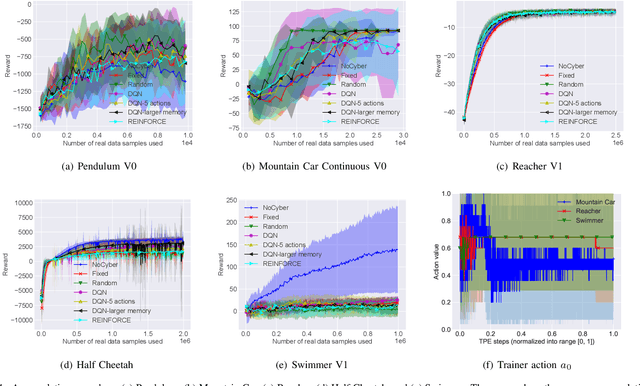
Model-based deep reinforcement learning (DRL) algorithm uses the sampled data from a real environment to learn the underlying system dynamics to construct an approximate cyber environment. By using the synthesized data generated from the cyber environment to train the target controller, the training cost can be reduced significantly. In current research, issues such as the applicability of approximate model and the strategy to sample and train from the real and cyber environment have not been fully investigated. To address these issues, we propose to utilize an intelligent trainer to properly use the approximate model and control the sampling and training procedure in the model-based DRL. To do so, we package the training process of a model-based DRL as a standard RL environment, and design an RL trainer to control the training process. The trainer has three control actions: the first action controls where to sample in the real and cyber environment; the second action determines how many data should be sampled from the cyber environment and the third action controls how many times the cyber data should be used to train the target controller. These actions would be controlled manually if without the trainer. The proposed framework is evaluated on five different tasks of OpenAI gym and the test results show that the proposed trainer achieves significant better performance than a fixed parameter model-based RL baseline algorithm. In addition, we compare the performance of the intelligent trainer to a random trainer and prove that the intelligent trainer can indeed learn on the fly. The proposed training framework can be extended to more control actions with more sophisticated trainer design to further reduce the tweak cost of model-based RL algorithms.
Power Data Classification: A Hybrid of a Novel Local Time Warping and LSTM
Jun 07, 2017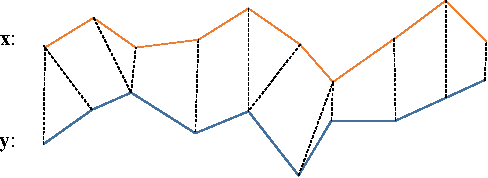
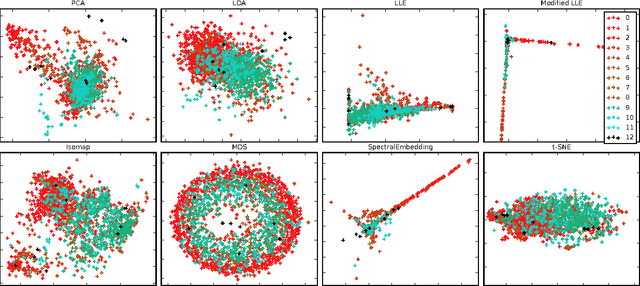
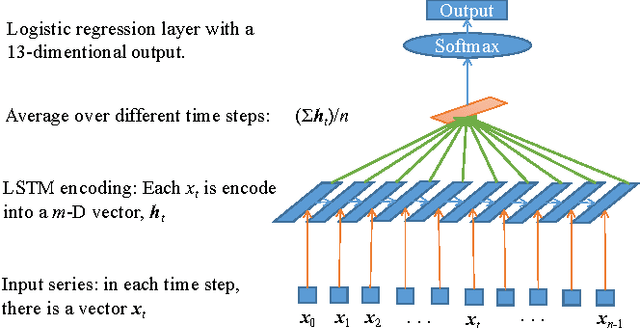
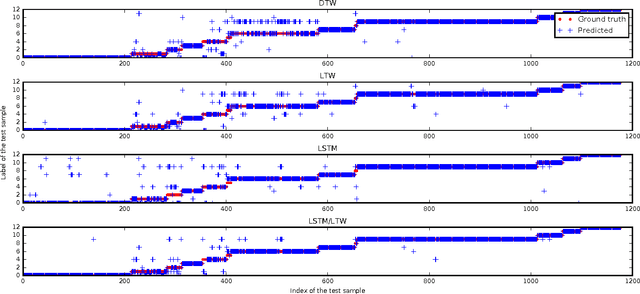
In this paper, for the purpose of data centre energy consumption monitoring and analysis, we propose to detect the running programs in a server by classifying the observed power consumption series. Time series classification problem has been extensively studied with various distance measurements developed; also recently the deep learning based sequence models have been proved to be promising. In this paper, we propose a novel distance measurement and build a time series classification algorithm hybridizing nearest neighbour and long short term memory (LSTM) neural network. More specifically, first we propose a new distance measurement termed as Local Time Warping (LTW), which utilizes a user-specified set for local warping, and is designed to be non-commutative and non-dynamic programming. Second we hybridize the 1NN-LTW and LSTM together. In particular, we combine the prediction probability vector of 1NN-LTW and LSTM to determine the label of the test cases. Finally, using the power consumption data from a real data center, we show that the proposed LTW can improve the classification accuracy of DTW from about 84% to 90%. Our experimental results prove that the proposed LTW is competitive on our data set compared with existed DTW variants and its non-commutative feature is indeed beneficial. We also test a linear version of LTW and it can significantly outperform existed linear runtime lower bound methods like LB_Keogh. Furthermore, with the hybrid algorithm, for the power series classification task we achieve an accuracy up to about 93%. Our research can inspire more studies on time series distance measurement and the hybrid of the deep learning models with other traditional models.