 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaconian: A Unified Opensource Framework for Model-Based Reinforcement Learning
Apr 23, 2019
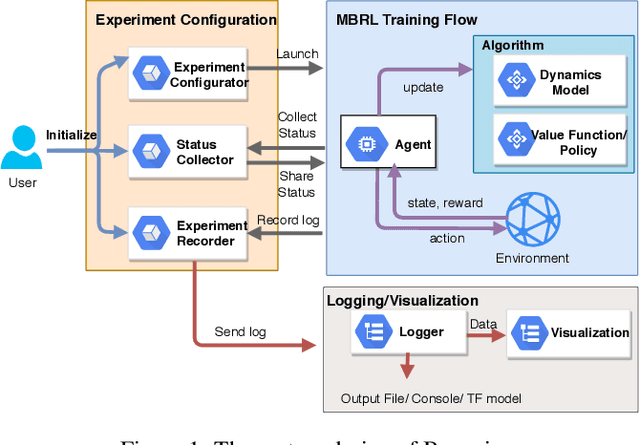
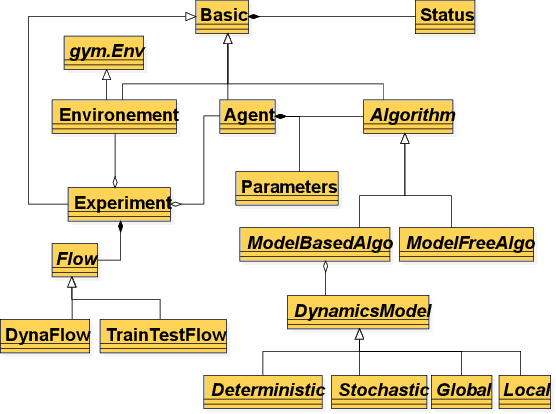
Model-Based Reinforcement Learning (MBRL) is one category of Reinforcement Learning (RL) methods which can improve sampling efficiency by modeling and approximating system dynamics. It has been widely adopted in the research of robotics, autonomous driving, etc. Despite its popularity, there still lacks some sophisticated and reusable opensource frameworks to facilitate MBRL research and experiments. To fill this gap, we develop a flexible and modularized framework, Baconian, which allows researchers to easily implement a MBRL testbed by customizing or building upon our provided modules and algorithms. Our framework can free the users from re-implementing popular MBRL algorithms from scratch thus greatly saves the users' efforts.
Intelligent Trainer for Model-Based Reinforcement Learning
May 29, 2018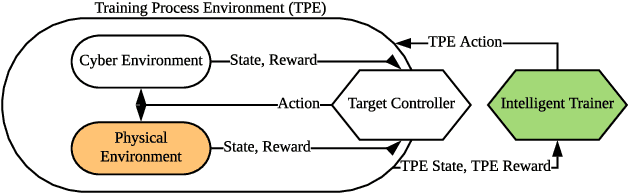

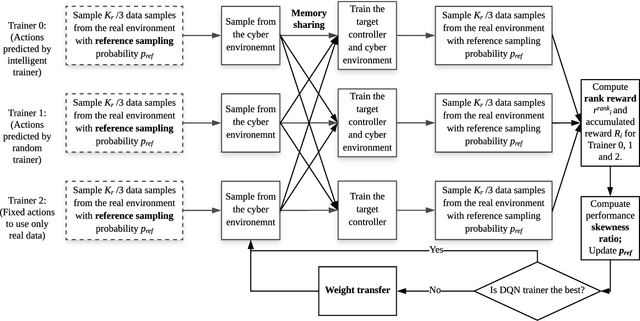
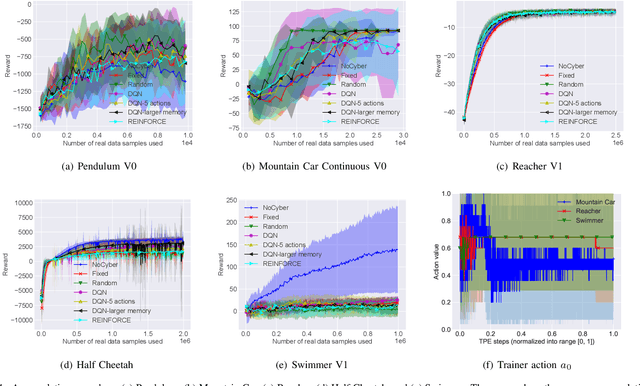
Model-based deep reinforcement learning (DRL) algorithm uses the sampled data from a real environment to learn the underlying system dynamics to construct an approximate cyber environment. By using the synthesized data generated from the cyber environment to train the target controller, the training cost can be reduced significantly. In current research, issues such as the applicability of approximate model and the strategy to sample and train from the real and cyber environment have not been fully investigated. To address these issues, we propose to utilize an intelligent trainer to properly use the approximate model and control the sampling and training procedure in the model-based DRL. To do so, we package the training process of a model-based DRL as a standard RL environment, and design an RL trainer to control the training process. The trainer has three control actions: the first action controls where to sample in the real and cyber environment; the second action determines how many data should be sampled from the cyber environment and the third action controls how many times the cyber data should be used to train the target controller. These actions would be controlled manually if without the trainer. The proposed framework is evaluated on five different tasks of OpenAI gym and the test results show that the proposed trainer achieves significant better performance than a fixed parameter model-based RL baseline algorithm. In addition, we compare the performance of the intelligent trainer to a random trainer and prove that the intelligent trainer can indeed learn on the fly. The proposed training framework can be extended to more control actions with more sophisticated trainer design to further reduce the tweak cost of model-based RL algorithms.