 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven solar forecasting enables near-optimal economic decisions
Sep 08, 2025Solar energy adoption is critical to achieving net-zero emissions. However, it remains difficult for many industrial and commercial actors to decide on whether they should adopt distributed solar-battery systems, which is largely due to the unavailability of fast, low-cost, and high-resolution irradiance forecasts. Here, we present SunCastNet, a lightweight data-driven forecasting system that provides 0.05$^\circ$, 10-minute resolution predictions of surface solar radiation downwards (SSRD) up to 7 days ahead. SunCastNet, coupled with reinforcement learning (RL) for battery scheduling, reduces operational regret by 76--93\% compared to robust decision making (RDM). In 25-year investment backtests, it enables up to five of ten high-emitting industrial sectors per region to cross the commercial viability threshold of 12\% Internal Rate of Return (IRR). These results show that high-resolution, long-horizon solar forecasts can directly translate into measurable economic gains, supporting near-optimal energy operations and accelerating renewable deployment.
FastAvatar: Towards Unified Fast High-Fidelity 3D Avatar Reconstruction with Large Gaussian Reconstruction Transformers
Aug 27, 2025Despite significant progress in 3D avatar reconstruction, it still faces challenges such as high time complexity, sensitivity to data quality, and low data utilization. We propose FastAvatar, a feedforward 3D avatar framework capable of flexibly leveraging diverse daily recordings (e.g., a single image, multi-view observations, or monocular video) to reconstruct a high-quality 3D Gaussian Splatting (3DGS) model within seconds, using only a single unified model. FastAvatar's core is a Large Gaussian Reconstruction Transformer featuring three key designs: First, a variant VGGT-style transformer architecture aggregating multi-frame cues while injecting initial 3D prompt to predict an aggregatable canonical 3DGS representation; Second, multi-granular guidance encoding (camera pose, FLAME expression, head pose) mitigating animation-induced misalignment for variable-length inputs; Third, incremental Gaussian aggregation via landmark tracking and sliced fusion losses. Integrating these features, FastAvatar enables incremental reconstruction, i.e., improving quality with more observations, unlike prior work wasting input data. This yields a quality-speed-tunable paradigm for highly usable avatar modeling. Extensive experiments show that FastAvatar has higher quality and highly competitive speed compared to existing methods.
RAGDiffusion: Faithful Cloth Generation via External Knowledge Assimilation
Nov 29, 2024



Standard clothing asset generation involves creating forward-facing flat-lay garment images displayed on a clear background by extracting clothing information from diverse real-world contexts, which presents significant challenges due to highly standardized sampling distributions and precise structural requirements in the generated images. Existing models have limited spatial perception and often exhibit structural hallucinations in this high-specification generative task. To address this issue, we propose a novel Retrieval-Augmented Generation (RAG) framework, termed RAGDiffusion, to enhance structure determinacy and mitigate hallucinations by assimilating external knowledge from LLM and databases. RAGDiffusion consists of two core processes: (1) Retrieval-based structure aggregation, which employs contrastive learning and a Structure Locally Linear Embedding (SLLE) to derive global structure and spatial landmarks, providing both soft and hard guidance to counteract structural ambiguities; and (2) Omni-level faithful garment generation, which introduces a three-level alignment that ensures fidelity in structural, pattern, and decoding components within the diffusing. Extensive experiments on challenging real-world datasets demonstrate that RAGDiffusion synthesizes structurally and detail-faithful clothing assets with significant performance improvements, representing a pioneering effort in high-specification faithful generation with RAG to confront intrinsic hallucinations and enhance fidelity.
AnyFit: Controllable Virtual Try-on for Any Combination of Attire Across Any Scenario
May 28, 2024



While image-based virtual try-on has made significant strides, emerging approaches still fall short of delivering high-fidelity and robust fitting images across various scenarios, as their models suffer from issues of ill-fitted garment styles and quality degrading during the training process, not to mention the lack of support for various combinations of attire. Therefore, we first propose a lightweight, scalable, operator known as Hydra Block for attire combinations. This is achieved through a parallel attention mechanism that facilitates the feature injection of multiple garments from conditionally encoded branches into the main network. Secondly, to significantly enhance the model's robustness and expressiveness in real-world scenarios, we evolve its potential across diverse settings by synthesizing the residuals of multiple models, as well as implementing a mask region boost strategy to overcome the instability caused by information leakage in existing models. Equipped with the above design, AnyFit surpasses all baselines on high-resolution benchmarks and real-world data by a large gap, excelling in producing well-fitting garments replete with photorealistic and rich details. Furthermore, AnyFit's impressive performance on high-fidelity virtual try-ons in any scenario from any image, paves a new path for future research within the fashion community.
Potential Paradigm Shift in Hazard Risk Management: AI-Based Weather Forecast for Tropical Cyclone Hazards
Apr 29, 2024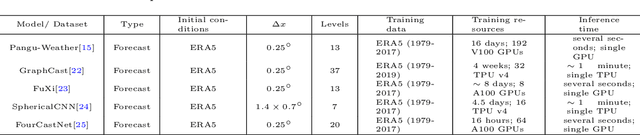
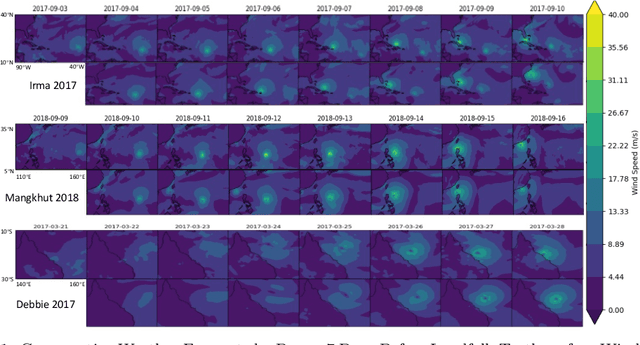
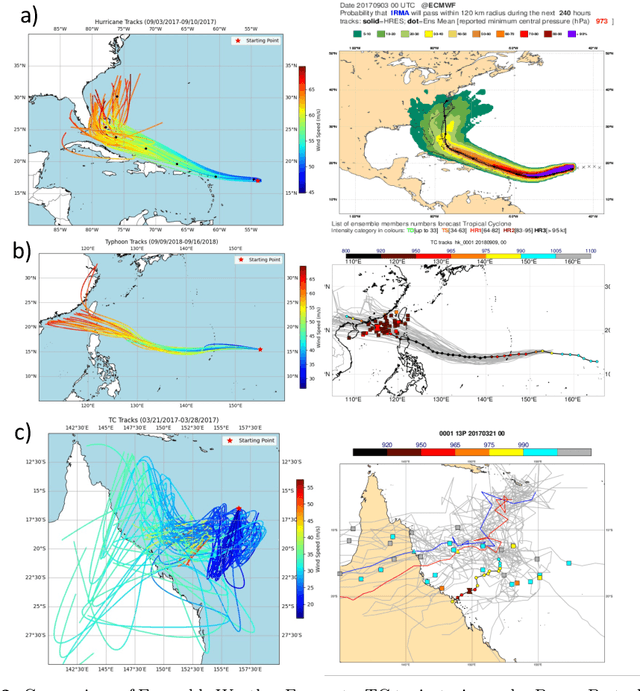
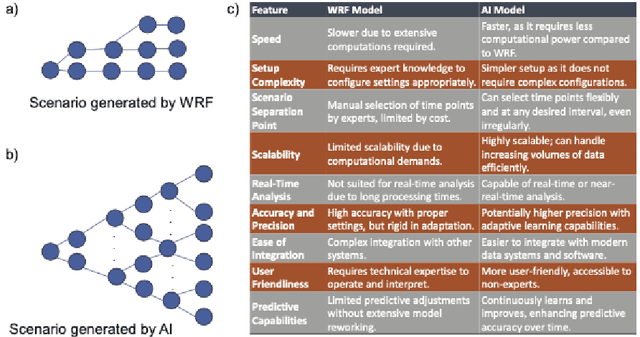
The advents of Artificial Intelligence (AI)-driven models marks a paradigm shift in risk management strategies for meteorological hazards. This study specifically employs tropical cyclones (TCs) as a focal example. We engineer a perturbation-based method to produce ensemble forecasts using the advanced Pangu AI weather model. Unlike traditional approaches that often generate fewer than 20 scenarios from Weather Research and Forecasting (WRF) simulations for one event, our method facilitates the rapid nature of AI-driven model to create thousands of scenarios. We offer open-source access to our model and evaluate its effectiveness through retrospective case studies of significant TC events: Hurricane Irma (2017), Typhoon Mangkhut (2018), and TC Debbie (2017), affecting regions across North America, East Asia, and Australia. Our findings indicate that the AI-generated ensemble forecasts align closely with the European Centre for Medium-Range Weather Forecasts (ECMWF) ensemble predictions up to seven days prior to landfall. This approach could substantially enhance the effectiveness of weather forecast-driven risk analysis and management, providing unprecedented operational speed, user-friendliness, and global applicability.
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Apr 09, 2024
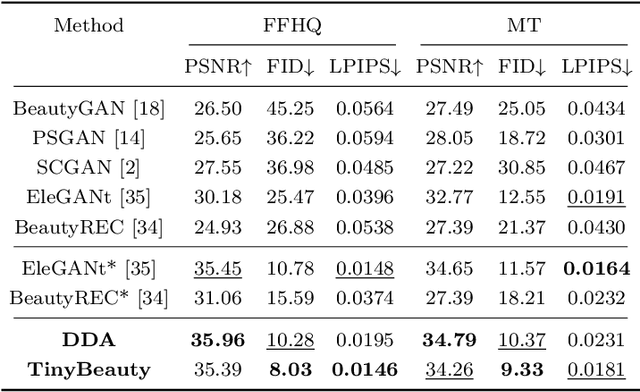

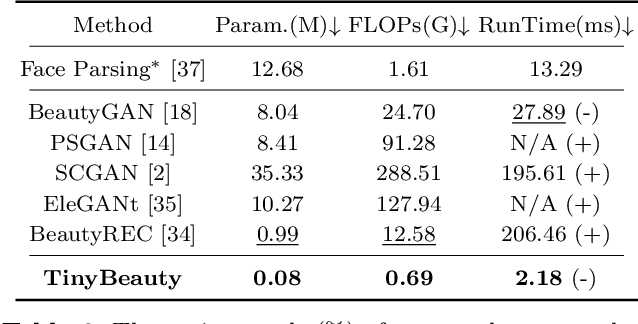
Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
FocalDreamer: Text-driven 3D Editing via Focal-fusion Assembly
Aug 22, 2023



While text-3D editing has made significant strides in leveraging score distillation sampling, emerging approaches still fall short in delivering separable, precise and consistent outcomes that are vital to content creation. In response, we introduce FocalDreamer, a framework that merges base shape with editable parts according to text prompts for fine-grained editing within desired regions. Specifically, equipped with geometry union and dual-path rendering, FocalDreamer assembles independent 3D parts into a complete object, tailored for convenient instance reuse and part-wise control. We propose geometric focal loss and style consistency regularization, which encourage focal fusion and congruent overall appearance. Furthermore, FocalDreamer generates high-fidelity geometry and PBR textures which are compatible with widely-used graphics engines. Extensive experiments have highlighted the superior editing capabilities of FocalDreamer in both quantitative and qualitative evaluations.
Omni Aggregation Networks for Lightweight Image Super-Resolution
Apr 24, 2023



While lightweight ViT framework has made tremendous progress in image super-resolution, its uni-dimensional self-attention modeling, as well as homogeneous aggregation scheme, limit its effective receptive field (ERF) to include more comprehensive interactions from both spatial and channel dimensions. To tackle these drawbacks, this work proposes two enhanced components under a new Omni-SR architecture. First, an Omni Self-Attention (OSA) block is proposed based on dense interaction principle, which can simultaneously model pixel-interaction from both spatial and channel dimensions, mining the potential correlations across omni-axis (i.e., spatial and channel). Coupling with mainstream window partitioning strategies, OSA can achieve superior performance with compelling computational budgets. Second, a multi-scale interaction scheme is proposed to mitigate sub-optimal ERF (i.e., premature saturation) in shallow models, which facilitates local propagation and meso-/global-scale interactions, rendering an omni-scale aggregation building block. Extensive experiments demonstrate that Omni-SR achieves record-high performance on lightweight super-resolution benchmarks (e.g., 26.95 dB@Urban100 $\times 4$ with only 792K parameters). Our code is available at \url{https://github.com/Francis0625/Omni-SR}.
3DQD: Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process
Mar 18, 2023


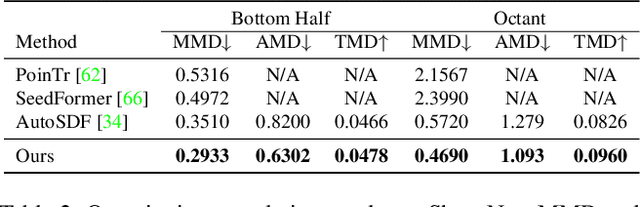
We develop a generalized 3D shape generation prior model, tailored for multiple 3D tasks including unconditional shape generation, point cloud completion, and cross-modality shape generation, etc. On one hand, to precisely capture local fine detailed shape information, a vector quantized variational autoencoder (VQ-VAE) is utilized to index local geometry from a compactly learned codebook based on a broad set of task training data. On the other hand, a discrete diffusion generator is introduced to model the inherent structural dependencies among different tokens. In the meantime, a multi-frequency fusion module (MFM) is developed to suppress high-frequency shape feature fluctuations, guided by multi-frequency contextual information. The above designs jointly equip our proposed 3D shape prior model with high-fidelity, diverse features as well as the capability of cross-modality alignment, and extensive experiments have demonstrated superior performances on various 3D shape generation tasks.
Learning Continuous Depth Representation via Geometric Spatial Aggregator
Dec 07, 2022Depth map super-resolution (DSR) has been a fundamental task for 3D computer vision. While arbitrary scale DSR is a more realistic setting in this scenario, previous approaches predominantly suffer from the issue of inefficient real-numbered scale upsampling. To explicitly address this issue, we propose a novel continuous depth representation for DSR. The heart of this representation is our proposed Geometric Spatial Aggregator (GSA), which exploits a distance field modulated by arbitrarily upsampled target gridding, through which the geometric information is explicitly introduced into feature aggregation and target generation. Furthermore, bricking with GSA, we present a transformer-style backbone named GeoDSR, which possesses a principled way to construct the functional mapping between local coordinates and the high-resolution output results, empowering our model with the advantage of arbitrary shape transformation ready to help diverse zooming demand. Extensive experimental results on standard depth map benchmarks, e.g., NYU v2, have demonstrated that the proposed framework achieves significant restoration gain in arbitrary scale depth map super-resolution compared with the prior art. Our codes are available at https://github.com/nana01219/GeoDSR.