 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition
Jun 04, 2026Large language models (LLMs) drive significant financial innovations, yet their high-concurrency deployment is severely bottlenecked by KV cache memory overhead, which inflates infrastructure costs and throttles scalability. To address this, we propose YouZhi-LLM, a highly efficient financial LLM empowered by a comprehensive structural transition and training pipeline natively built on the Huawei Ascend ecosystem. At its algorithmic core, YouZhi-LLM features a layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes, maximizing KV-cache compression while minimizing perplexity degradation. To recover representation capacity and inject domain expertise, the Ascend-based training pipeline seamlessly integrates generalized knowledge distillation with financial-specific supervised fine-tuning. Evaluations demonstrate the superiority of this systematic approach, with the adaptive transition reducing perplexity degradation by up to 35% over uniform baselines. Crucially, when evaluated on Ascend NPUs via vLLM-Ascend, the massive KV-cache reduction translates directly into deployment efficiency. Compared to their respective base models, YouZhi-7B yields a 12.3% improvement in average financial benchmark score alongside a 2.69$\times$ increase in maximum concurrency; similarly, YouZhi-14B achieves a 7.0% accuracy gain and a 2.43$\times$ concurrency boost, establishing a new paradigm for cost-effective, high-throughput financial inference.
CFSR: Geometry-Conditioned Shadow Removal via Physical Disentanglement
Apr 20, 2026Traditional shadow removal networks often treat image restoration as an unconstrained mapping, lacking the physical interpretability required to balance localized texture recovery with global illumination consistency. To address this, we propose CFSR, a multi-modal prior-driven framework that reframes shadow removal as a physics-constrained restoration process. By seamlessly integrating 3D geometric cues with large-scale foundation model semantics, CFSR effectively bridges the 2D-3D domain gap. Specifically, we first map observations into a custom HVI color space to suppress shadow-induced noise and robustly fuse RGB data with estimated depth priors. At its core, our Geometric & Semantic Dual Explicit Guided Attention mechanism utilizes DINO features and 3D surface normals to directly modulate the attention affinity matrix, structurally enforcing physical lighting constraints. To recover severely degraded regions, we inject holistic priors via a frozen CLIP encoder. Finally, our Frequency Collaborative Reconstruction Module (FCRM) achieves an optimal synthesis by decoupling the decoding process. Conditioned on geometric priors, FCRM seamlessly harmonizes the reconstruction of sharp high-frequency occlusion boundaries with the restoration of low-frequency global illumination. Extensive experiments demonstrate that CFSR achieves state-of-the-art performance across multiple challenging benchmarks.
ATSS: Detecting AI-Generated Videos via Anomalous Temporal Self-Similarity
Apr 05, 2026AI-generated videos (AIGVs) have achieved unprecedented photorealism, posing severe threats to digital forensics. Existing AIGV detectors focus mainly on localized artifacts or short-term temporal inconsistencies, thus often fail to capture the underlying generative logic governing global temporal evolution, limiting AIGV detection performance. In this paper, we identify a distinctive fingerprint in AIGVs, termed anomalous temporal self-similarity (ATSS). Unlike real videos that exhibit stochastic natural dynamics, AIGVs follow deterministic anchor-driven trajectories (e.g., text or image prompts), inducing unnaturally repetitive correlations across visual and semantic domains. To exploit this, we propose the ATSS method, a multimodal detection framework that exploits this insight via a triple-similarity representation and a cross-attentive fusion mechanism. Specifically, ATSS reconstructs semantic trajectories by leveraging frame-wise descriptions to construct visual, textual, and cross-modal similarity matrices, which jointly quantify the inherent temporal anomalies. These matrices are encoded by dedicated Transformer encoders and integrated via a bidirectional cross-attentive fusion module to effectively model intra- and inter-modal dynamics. Extensive experiments on four large-scale benchmarks, including GenVideo, EvalCrafter, VideoPhy, and VidProM, demonstrate that ATSS significantly outperforms state-of-the-art methods in terms of AP, AUC, and ACC metrics, exhibiting superior generalization across diverse video generation models. Code and models of ATSS will be released at https://github.com/hwang-cs-ime/ATSS.
A Machine Learning-Based Study on the Synergistic Optimization of Supply Chain Management and Financial Supply Chains from an Economic Perspective
Sep 03, 2025Based on economic theories and integrated with machine learning technology, this study explores a collaborative Supply Chain Management and Financial Supply Chain Management (SCM - FSCM) model to solve issues like efficiency loss, financing constraints, and risk transmission. We combine Transaction Cost and Information Asymmetry theories and use algorithms such as random forests to process multi-dimensional data and build a data-driven, three-dimensional (cost-efficiency-risk) analysis framework. We then apply an FSCM model of "core enterprise credit empowerment plus dynamic pledge financing." We use Long Short-Term Memory (LSTM) networks for demand forecasting and clustering/regression algorithms for benefit allocation. The study also combines Game Theory and reinforcement learning to optimize the inventory-procurement mechanism and uses eXtreme Gradient Boosting (XGBoost) for credit assessment to enable rapid monetization of inventory. Verified with 20 core and 100 supporting enterprises, the results show a 30\% increase in inventory turnover, an 18\%-22\% decrease in SME financing costs, a stable order fulfillment rate above 95\%, and excellent model performance (demand forecasting error <= 8\%, credit assessment accuracy >= 90\%). This SCM-FSCM model effectively reduces operating costs, alleviates financing constraints, and supports high-quality supply chain development.
VITA: Vision-to-Action Flow Matching Policy
Jul 17, 2025We present VITA, a Vision-To-Action flow matching policy that evolves latent visual representations into latent actions for visuomotor control. Traditional flow matching and diffusion policies sample from standard source distributions (e.g., Gaussian noise) and require additional conditioning mechanisms like cross-attention to condition action generation on visual information, creating time and space overheads. VITA proposes a novel paradigm that treats latent images as the flow source, learning an inherent mapping from vision to action while eliminating separate conditioning modules and preserving generative modeling capabilities. Learning flows between fundamentally different modalities like vision and action is challenging due to sparse action data lacking semantic structures and dimensional mismatches between high-dimensional visual representations and raw actions. We address this by creating a structured action latent space via an autoencoder as the flow matching target, up-sampling raw actions to match visual representation shapes. Crucially, we supervise flow matching with both encoder targets and final action outputs through flow latent decoding, which backpropagates action reconstruction loss through sequential flow matching ODE solving steps for effective end-to-end learning. Implemented as simple MLP layers, VITA is evaluated on challenging bi-manual manipulation tasks on the ALOHA platform, including 5 simulation and 2 real-world tasks. Despite its simplicity, MLP-only VITA outperforms or matches state-of-the-art generative policies while reducing inference latency by 50-130% compared to conventional flow matching policies requiring different conditioning mechanisms or complex architectures. To our knowledge, VITA is the first MLP-only flow matching policy capable of solving complex bi-manual manipulation tasks like those in ALOHA benchmarks.
Ego-centric Learning of Communicative World Models for Autonomous Driving
Jun 09, 2025



We study multi-agent reinforcement learning (MARL) for tasks in complex high-dimensional environments, such as autonomous driving. MARL is known to suffer from the \textit{partial observability} and \textit{non-stationarity} issues. To tackle these challenges, information sharing is often employed, which however faces major hurdles in practice, including overwhelming communication overhead and scalability concerns. By making use of generative AI embodied in world model together with its latent representation, we develop {\it CALL}, \underline{C}ommunic\underline{a}tive Wor\underline{l}d Mode\underline{l}, for MARL, where 1) each agent first learns its world model that encodes its state and intention into low-dimensional latent representation with smaller memory footprint, which can be shared with other agents of interest via lightweight communication; and 2) each agent carries out ego-centric learning while exploiting lightweight information sharing to enrich her world model, and then exploits its generalization capacity to improve prediction for better planning. We characterize the gain on the prediction accuracy from the information sharing and its impact on performance gap. Extensive experiments are carried out on the challenging local trajectory planning tasks in the CARLA platform to demonstrate the performance gains of using \textit{CALL}.
GeoMM: On Geodesic Perspective for Multi-modal Learning
May 16, 2025Geodesic distance serves as a reliable means of measuring distance in nonlinear spaces, and such nonlinear manifolds are prevalent in the current multimodal learning. In these scenarios, some samples may exhibit high similarity, yet they convey different semantics, making traditional distance metrics inadequate for distinguishing between positive and negative samples. This paper introduces geodesic distance as a novel distance metric in multi-modal learning for the first time, to mine correlations between samples, aiming to address the limitations of common distance metric. Our approach incorporates a comprehensive series of strategies to adapt geodesic distance for the current multimodal learning. Specifically, we construct a graph structure to represent the adjacency relationships among samples by thresholding distances between them and then apply the shortest-path algorithm to obtain geodesic distance within this graph. To facilitate efficient computation, we further propose a hierarchical graph structure through clustering and combined with incremental update strategies for dynamic status updates. Extensive experiments across various downstream tasks validate the effectiveness of our proposed method, demonstrating its capability to capture complex relationships between samples and improve the performance of multimodal learning models.
HCMA: Hierarchical Cross-model Alignment for Grounded Text-to-Image Generation
May 15, 2025
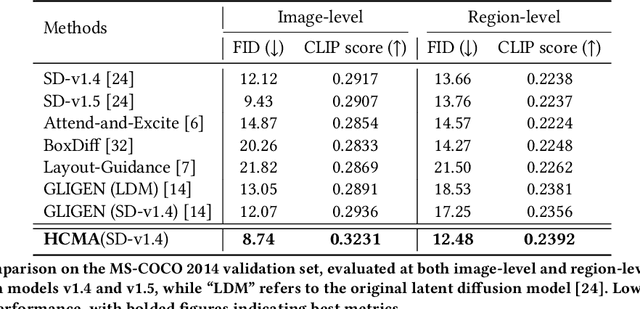
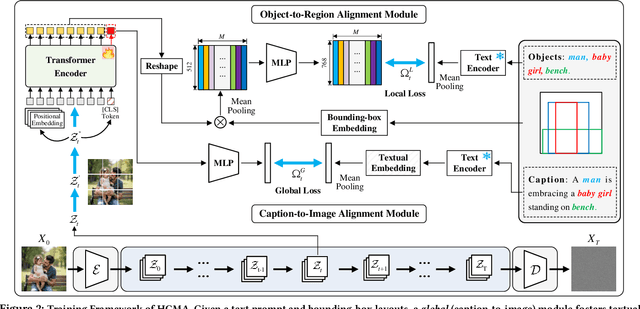
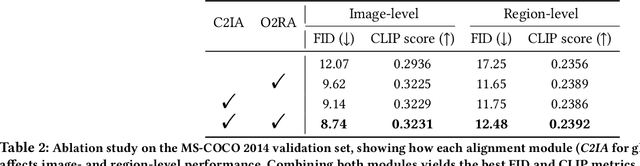
Text-to-image synthesis has progressed to the point where models can generate visually compelling images from natural language prompts. Yet, existing methods often fail to reconcile high-level semantic fidelity with explicit spatial control, particularly in scenes involving multiple objects, nuanced relations, or complex layouts. To bridge this gap, we propose a Hierarchical Cross-Modal Alignment (HCMA) framework for grounded text-to-image generation. HCMA integrates two alignment modules into each diffusion sampling step: a global module that continuously aligns latent representations with textual descriptions to ensure scene-level coherence, and a local module that employs bounding-box layouts to anchor objects at specified locations, enabling fine-grained spatial control. Extensive experiments on the MS-COCO 2014 validation set show that HCMA surpasses state-of-the-art baselines, achieving a 0.69 improvement in Frechet Inception Distance (FID) and a 0.0295 gain in CLIP Score. These results demonstrate HCMA's effectiveness in faithfully capturing intricate textual semantics while adhering to user-defined spatial constraints, offering a robust solution for semantically grounded image generation. Our code is available at https://github.com/hwang-cs-ime/HCMA.
IN-RIL: Interleaved Reinforcement and Imitation Learning for Policy Fine-Tuning
May 15, 2025Imitation learning (IL) and reinforcement learning (RL) each offer distinct advantages for robotics policy learning: IL provides stable learning from demonstrations, and RL promotes generalization through exploration. While existing robot learning approaches using IL-based pre-training followed by RL-based fine-tuning are promising, this two-step learning paradigm often suffers from instability and poor sample efficiency during the RL fine-tuning phase. In this work, we introduce IN-RIL, INterleaved Reinforcement learning and Imitation Learning, for policy fine-tuning, which periodically injects IL updates after multiple RL updates and hence can benefit from the stability of IL and the guidance of expert data for more efficient exploration throughout the entire fine-tuning process. Since IL and RL involve different optimization objectives, we develop gradient separation mechanisms to prevent destructive interference during \ABBR fine-tuning, by separating possibly conflicting gradient updates in orthogonal subspaces. Furthermore, we conduct rigorous analysis, and our findings shed light on why interleaving IL with RL stabilizes learning and improves sample-efficiency. Extensive experiments on 14 robot manipulation and locomotion tasks across 3 benchmarks, including FurnitureBench, OpenAI Gym, and Robomimic, demonstrate that \ABBR can significantly improve sample efficiency and mitigate performance collapse during online finetuning in both long- and short-horizon tasks with either sparse or dense rewards. IN-RIL, as a general plug-in compatible with various state-of-the-art RL algorithms, can significantly improve RL fine-tuning, e.g., from 12\% to 88\% with 6.3x improvement in the success rate on Robomimic Transport. Project page: https://github.com/ucd-dare/IN-RIL.
Heterogeneous Decision Making in Mixed Traffic: Uncertainty-aware Planning and Bounded Rationality
Feb 25, 2025The past few years have witnessed a rapid growth of the deployment of automated vehicles (AVs). Clearly, AVs and human-driven vehicles (HVs) will co-exist for many years, and AVs will have to operate around HVs, pedestrians, cyclists, and more, calling for fundamental breakthroughs in AI designed for mixed traffic to achieve mixed autonomy. Thus motivated, we study heterogeneous decision making by AVs and HVs in a mixed traffic environment, aiming to capture the interactions between human and machine decision-making and develop an AI foundation that enables vehicles to operate safely and efficiently. There are a number of challenges to achieve mixed autonomy, including 1) humans drivers make driving decisions with bounded rationality, and it remains open to develop accurate models for HVs' decision making; and 2) uncertainty-aware planning plays a critical role for AVs to take safety maneuvers in response to the human behavior. In this paper, we introduce a formulation of AV-HV interaction, where the HV makes decisions with bounded rationality and the AV employs uncertainty-aware planning based on the prediction on HV's future actions. We conduct a comprehensive analysis on AV and HV's learning regret to answer the questions: 1) {How does the learning performance depend on HV's bounded rationality and AV's planning}; 2) {How do different decision making strategies impact the overall learning performance}? Our findings reveal some intriguing phenomena, such as Goodhart's Law in AV's learning performance and compounding effects in HV's decision making process. By examining the dynamics of the regrets, we gain insights into the interplay between human and machine decision making.