 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
ATSS: Detecting AI-Generated Videos via Anomalous Temporal Self-Similarity
Apr 05, 2026AI-generated videos (AIGVs) have achieved unprecedented photorealism, posing severe threats to digital forensics. Existing AIGV detectors focus mainly on localized artifacts or short-term temporal inconsistencies, thus often fail to capture the underlying generative logic governing global temporal evolution, limiting AIGV detection performance. In this paper, we identify a distinctive fingerprint in AIGVs, termed anomalous temporal self-similarity (ATSS). Unlike real videos that exhibit stochastic natural dynamics, AIGVs follow deterministic anchor-driven trajectories (e.g., text or image prompts), inducing unnaturally repetitive correlations across visual and semantic domains. To exploit this, we propose the ATSS method, a multimodal detection framework that exploits this insight via a triple-similarity representation and a cross-attentive fusion mechanism. Specifically, ATSS reconstructs semantic trajectories by leveraging frame-wise descriptions to construct visual, textual, and cross-modal similarity matrices, which jointly quantify the inherent temporal anomalies. These matrices are encoded by dedicated Transformer encoders and integrated via a bidirectional cross-attentive fusion module to effectively model intra- and inter-modal dynamics. Extensive experiments on four large-scale benchmarks, including GenVideo, EvalCrafter, VideoPhy, and VidProM, demonstrate that ATSS significantly outperforms state-of-the-art methods in terms of AP, AUC, and ACC metrics, exhibiting superior generalization across diverse video generation models. Code and models of ATSS will be released at https://github.com/hwang-cs-ime/ATSS.
FlexMap: Generalized HD Map Construction from Flexible Camera Configurations
Jan 29, 2026High-definition (HD) maps provide essential semantic information of road structures for autonomous driving systems, yet current HD map construction methods require calibrated multi-camera setups and either implicit or explicit 2D-to-BEV transformations, making them fragile when sensors fail or camera configurations vary across vehicle fleets. We introduce FlexMap, unlike prior methods that are fixed to a specific N-camera rig, our approach adapts to variable camera configurations without any architectural changes or per-configuration retraining. Our key innovation eliminates explicit geometric projections by using a geometry-aware foundation model with cross-frame attention to implicitly encode 3D scene understanding in feature space. FlexMap features two core components: a spatial-temporal enhancement module that separates cross-view spatial reasoning from temporal dynamics, and a camera-aware decoder with latent camera tokens, enabling view-adaptive attention without the need for projection matrices. Experiments demonstrate that FlexMap outperforms existing methods across multiple configurations while maintaining robustness to missing views and sensor variations, enabling more practical real-world deployment.
Emotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
Jan 23, 2026Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.
Cell Behavior Video Classification Challenge, a benchmark for computer vision methods in time-lapse microscopy
Jan 15, 2026The classification of microscopy videos capturing complex cellular behaviors is crucial for understanding and quantifying the dynamics of biological processes over time. However, it remains a frontier in computer vision, requiring approaches that effectively model the shape and motion of objects without rigid boundaries, extract hierarchical spatiotemporal features from entire image sequences rather than static frames, and account for multiple objects within the field of view. To this end, we organized the Cell Behavior Video Classification Challenge (CBVCC), benchmarking 35 methods based on three approaches: classification of tracking-derived features, end-to-end deep learning architectures to directly learn spatiotemporal features from the entire video sequence without explicit cell tracking, or ensembling tracking-derived with image-derived features. We discuss the results achieved by the participants and compare the potential and limitations of each approach, serving as a basis to foster the development of computer vision methods for studying cellular dynamics.
Overcoming Joint Intractability with Lossless Hierarchical Speculative Decoding
Jan 09, 2026Verification is a key bottleneck in improving inference speed while maintaining distribution fidelity in Speculative Decoding. Recent work has shown that sequence-level verification leads to a higher number of accepted tokens compared to token-wise verification. However, existing solutions often rely on surrogate approximations or are constrained by partial information, struggling with joint intractability. In this work, we propose Hierarchical Speculative Decoding (HSD), a provably lossless verification method that significantly boosts the expected number of accepted tokens and overcomes joint intractability by balancing excess and deficient probability mass across accessible branches. Our extensive large-scale experiments demonstrate that HSD yields consistent improvements in acceptance rates across diverse model families and benchmarks. Moreover, its strong explainability and generality make it readily integrable into a wide range of speculative decoding frameworks. Notably, integrating HSD into EAGLE-3 yields over a 12% performance gain, establishing state-of-the-art decoding efficiency without compromising distribution fidelity. Code is available at https://github.com/ZhouYuxuanYX/Hierarchical-Speculative-Decoding.
HCMA: Hierarchical Cross-model Alignment for Grounded Text-to-Image Generation
May 15, 2025
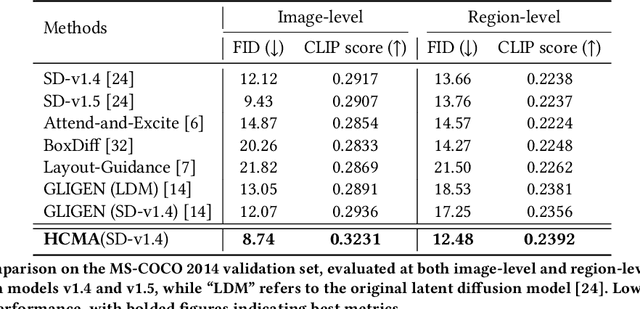
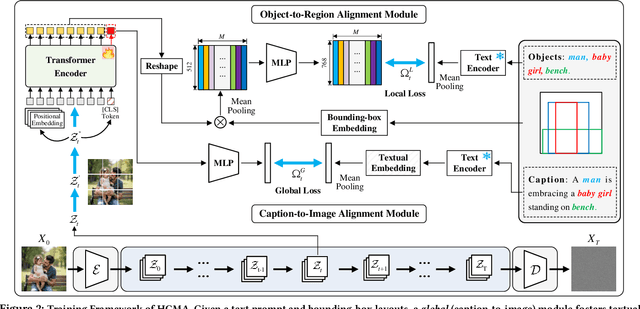
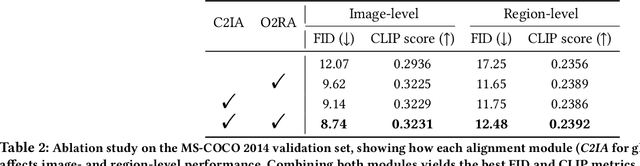
Text-to-image synthesis has progressed to the point where models can generate visually compelling images from natural language prompts. Yet, existing methods often fail to reconcile high-level semantic fidelity with explicit spatial control, particularly in scenes involving multiple objects, nuanced relations, or complex layouts. To bridge this gap, we propose a Hierarchical Cross-Modal Alignment (HCMA) framework for grounded text-to-image generation. HCMA integrates two alignment modules into each diffusion sampling step: a global module that continuously aligns latent representations with textual descriptions to ensure scene-level coherence, and a local module that employs bounding-box layouts to anchor objects at specified locations, enabling fine-grained spatial control. Extensive experiments on the MS-COCO 2014 validation set show that HCMA surpasses state-of-the-art baselines, achieving a 0.69 improvement in Frechet Inception Distance (FID) and a 0.0295 gain in CLIP Score. These results demonstrate HCMA's effectiveness in faithfully capturing intricate textual semantics while adhering to user-defined spatial constraints, offering a robust solution for semantically grounded image generation. Our code is available at https://github.com/hwang-cs-ime/HCMA.
Securing the Skies: A Comprehensive Survey on Anti-UAV Methods, Benchmarking, and Future Directions
Apr 16, 2025Unmanned Aerial Vehicles (UAVs) are indispensable for infrastructure inspection, surveillance, and related tasks, yet they also introduce critical security challenges. This survey provides a wide-ranging examination of the anti-UAV domain, centering on three core objectives-classification, detection, and tracking-while detailing emerging methodologies such as diffusion-based data synthesis, multi-modal fusion, vision-language modeling, self-supervised learning, and reinforcement learning. We systematically evaluate state-of-the-art solutions across both single-modality and multi-sensor pipelines (spanning RGB, infrared, audio, radar, and RF) and discuss large-scale as well as adversarially oriented benchmarks. Our analysis reveals persistent gaps in real-time performance, stealth detection, and swarm-based scenarios, underscoring pressing needs for robust, adaptive anti-UAV systems. By highlighting open research directions, we aim to foster innovation and guide the development of next-generation defense strategies in an era marked by the extensive use of UAVs.
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Apr 10, 2025Most existing emotion analysis emphasizes which emotion arises (e.g., happy, sad, angry) but neglects the deeper why. We propose Emotion Interpretation (EI), focusing on causal factors-whether explicit (e.g., observable objects, interpersonal interactions) or implicit (e.g., cultural context, off-screen events)-that drive emotional responses. Unlike traditional emotion recognition, EI tasks require reasoning about triggers instead of mere labeling. To facilitate EI research, we present EIBench, a large-scale benchmark encompassing 1,615 basic EI samples and 50 complex EI samples featuring multifaceted emotions. Each instance demands rationale-based explanations rather than straightforward categorization. We further propose a Coarse-to-Fine Self-Ask (CFSA) annotation pipeline, which guides Vision-Language Models (VLLMs) through iterative question-answer rounds to yield high-quality labels at scale. Extensive evaluations on open-source and proprietary large language models under four experimental settings reveal consistent performance gaps-especially for more intricate scenarios-underscoring EI's potential to enrich empathetic, context-aware AI applications. Our benchmark and methods are publicly available at: https://github.com/Lum1104/EIBench, offering a foundation for advanced multimodal causal analysis and next-generation affective computing.
HA-VLN: A Benchmark for Human-Aware Navigation in Discrete-Continuous Environments with Dynamic Multi-Human Interactions, Real-World Validation, and an Open Leaderboard
Mar 18, 2025
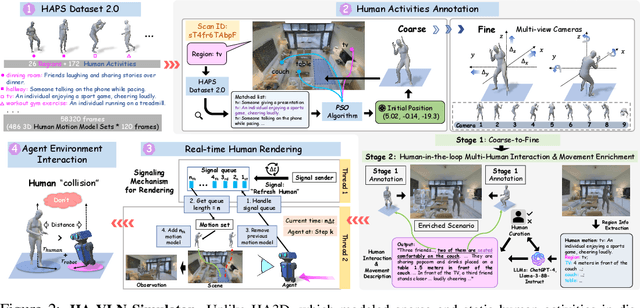
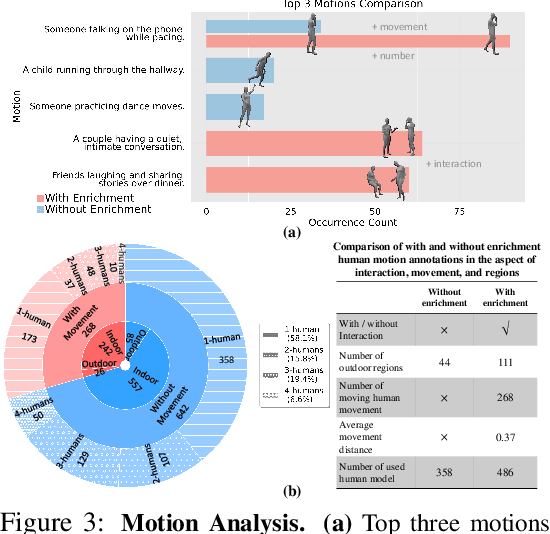

Vision-and-Language Navigation (VLN) systems often focus on either discrete (panoramic) or continuous (free-motion) paradigms alone, overlooking the complexities of human-populated, dynamic environments. We introduce a unified Human-Aware VLN (HA-VLN) benchmark that merges these paradigms under explicit social-awareness constraints. Our contributions include: 1. A standardized task definition that balances discrete-continuous navigation with personal-space requirements; 2. An enhanced human motion dataset (HAPS 2.0) and upgraded simulators capturing realistic multi-human interactions, outdoor contexts, and refined motion-language alignment; 3. Extensive benchmarking on 16,844 human-centric instructions, revealing how multi-human dynamics and partial observability pose substantial challenges for leading VLN agents; 4. Real-world robot tests validating sim-to-real transfer in crowded indoor spaces; and 5. A public leaderboard supporting transparent comparisons across discrete and continuous tasks. Empirical results show improved navigation success and fewer collisions when social context is integrated, underscoring the need for human-centric design. By releasing all datasets, simulators, agent code, and evaluation tools, we aim to advance safer, more capable, and socially responsible VLN research.