 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmphasizing Discriminative Features for Dataset Distillation in Complex Scenarios
Oct 22, 2024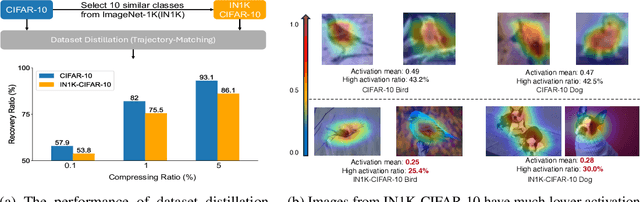
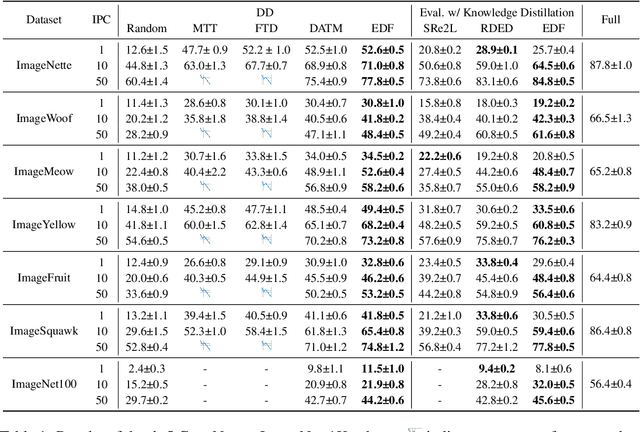

Dataset distillation has demonstrated strong performance on simple datasets like CIFAR, MNIST, and TinyImageNet but struggles to achieve similar results in more complex scenarios. In this paper, we propose EDF (emphasizes the discriminative features), a dataset distillation method that enhances key discriminative regions in synthetic images using Grad-CAM activation maps. Our approach is inspired by a key observation: in simple datasets, high-activation areas typically occupy most of the image, whereas in complex scenarios, the size of these areas is much smaller. Unlike previous methods that treat all pixels equally when synthesizing images, EDF uses Grad-CAM activation maps to enhance high-activation areas. From a supervision perspective, we downplay supervision signals that have lower losses, as they contain common patterns. Additionally, to help the DD community better explore complex scenarios, we build the Complex Dataset Distillation (Comp-DD) benchmark by meticulously selecting sixteen subsets, eight easy and eight hard, from ImageNet-1K. In particular, EDF consistently outperforms SOTA results in complex scenarios, such as ImageNet-1K subsets. Hopefully, more researchers will be inspired and encouraged to improve the practicality and efficacy of DD. Our code and benchmark will be made public at https://github.com/NUS-HPC-AI-Lab/EDF.
Prioritize Alignment in Dataset Distillation
Aug 06, 2024
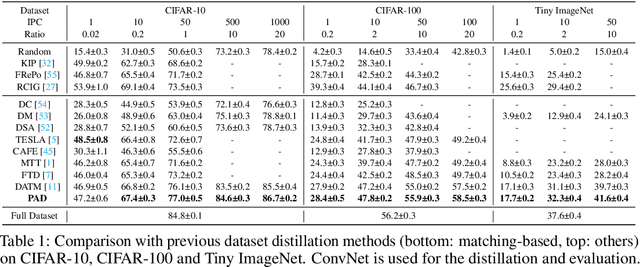
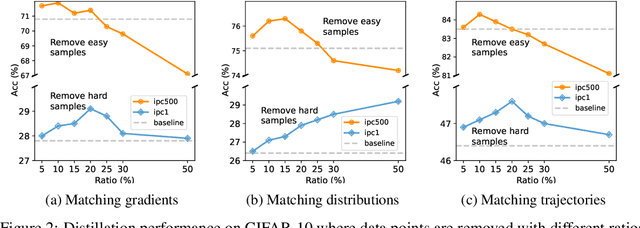
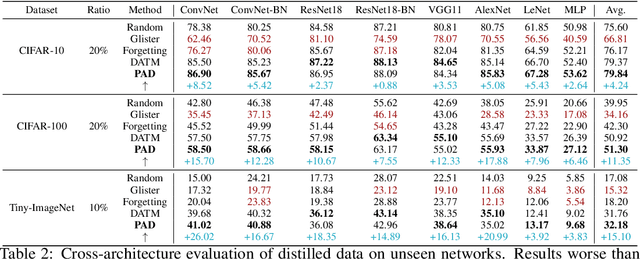
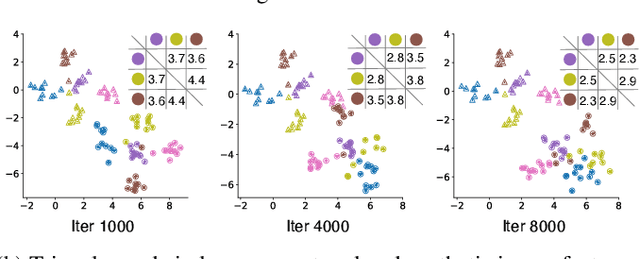
Dataset Distillation aims to compress a large dataset into a significantly more compact, synthetic one without compromising the performance of the trained models. To achieve this, existing methods use the agent model to extract information from the target dataset and embed it into the distilled dataset. Consequently, the quality of extracted and embedded information determines the quality of the distilled dataset. In this work, we find that existing methods introduce misaligned information in both information extraction and embedding stages. To alleviate this, we propose Prioritize Alignment in Dataset Distillation (PAD), which aligns information from the following two perspectives. 1) We prune the target dataset according to the compressing ratio to filter the information that can be extracted by the agent model. 2) We use only deep layers of the agent model to perform the distillation to avoid excessively introducing low-level information. This simple strategy effectively filters out misaligned information and brings non-trivial improvement for mainstream matching-based distillation algorithms. Furthermore, built on trajectory matching, \textbf{PAD} achieves remarkable improvements on various benchmarks, achieving state-of-the-art performance.
Adapting to Distribution Shift by Visual Domain Prompt Generation
May 05, 2024



In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Error-Aware Spatial Ensembles for Video Frame Interpolation
Jul 25, 2022
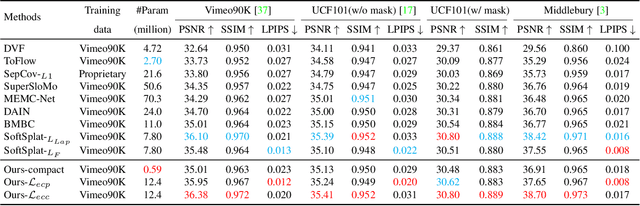
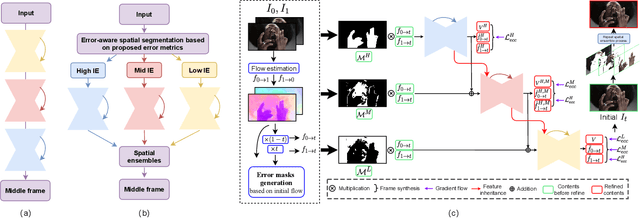
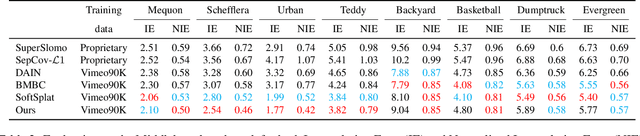
Video frame interpolation~(VFI) algorithms have improved considerably in recent years due to unprecedented progress in both data-driven algorithms and their implementations. Recent research has introduced advanced motion estimation or novel warping methods as the means to address challenging VFI scenarios. However, none of the published VFI works considers the spatially non-uniform characteristics of the interpolation error (IE). This work introduces such a solution. By closely examining the correlation between optical flow and IE, the paper proposes novel error prediction metrics that partition the middle frame into distinct regions corresponding to different IE levels. Building upon this IE-driven segmentation, and through the use of novel error-controlled loss functions, it introduces an ensemble of spatially adaptive interpolation units that progressively processes and integrates the segmented regions. This spatial ensemble results in an effective and computationally attractive VFI solution. Extensive experimentation on popular video interpolation benchmarks indicates that the proposed solution outperforms the current state-of-the-art (SOTA) in applications of current interest.
All at Once: Temporally Adaptive Multi-Frame Interpolation with Advanced Motion Modeling
Jul 23, 2020
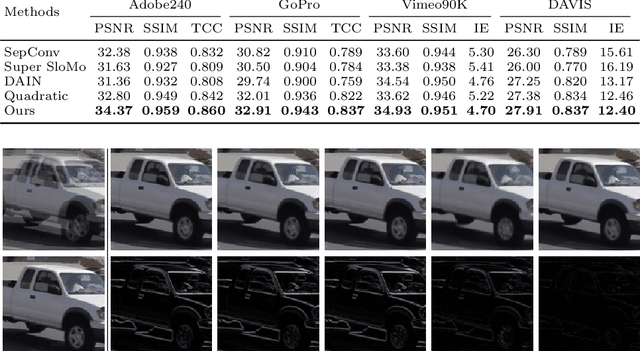

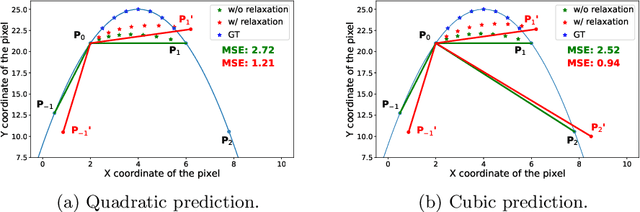
Recent advances in high refresh rate displays as well as the increased interest in high rate of slow motion and frame up-conversion fuel the demand for efficient and cost-effective multi-frame video interpolation solutions. To that regard, inserting multiple frames between consecutive video frames are of paramount importance for the consumer electronics industry. State-of-the-art methods are iterative solutions interpolating one frame at the time. They introduce temporal inconsistencies and clearly noticeable visual artifacts. Departing from the state-of-the-art, this work introduces a true multi-frame interpolator. It utilizes a pyramidal style network in the temporal domain to complete the multi-frame interpolation task in one-shot. A novel flow estimation procedure using a relaxed loss function, and an advanced, cubic-based, motion model is also used to further boost interpolation accuracy when complex motion segments are encountered. Results on the Adobe240 dataset show that the proposed method generates visually pleasing, temporally consistent frames, outperforms the current best off-the-shelf method by 1.57db in PSNR with 8 times smaller model and 7.7 times faster. The proposed method can be easily extended to interpolate a large number of new frames while remaining efficient because of the one-shot mechanism.