 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidget2Code: From Visual Widgets to UI Code via Multimodal LLMs
Dec 22, 2025User interface to code (UI2Code) aims to generate executable code that can faithfully reconstruct a given input UI. Prior work focuses largely on web pages and mobile screens, leaving app widgets underexplored. Unlike web or mobile UIs with rich hierarchical context, widgets are compact, context-free micro-interfaces that summarize key information through dense layouts and iconography under strict spatial constraints. Moreover, while (image, code) pairs are widely available for web or mobile UIs, widget designs are proprietary and lack accessible markup. We formalize this setting as the Widget-to-Code (Widget2Code) and introduce an image-only widget benchmark with fine-grained, multi-dimensional evaluation metrics. Benchmarking shows that although generalized multimodal large language models (MLLMs) outperform specialized UI2Code methods, they still produce unreliable and visually inconsistent code. To address these limitations, we develop a baseline that jointly advances perceptual understanding and structured code generation. At the perceptual level, we follow widget design principles to assemble atomic components into complete layouts, equipped with icon retrieval and reusable visualization modules. At the system level, we design an end-to-end infrastructure, WidgetFactory, which includes a framework-agnostic widget-tailored domain-specific language (WidgetDSL) and a compiler that translates it into multiple front-end implementations (e.g., React, HTML/CSS). An adaptive rendering module further refines spatial dimensions to satisfy compactness constraints. Together, these contributions substantially enhance visual fidelity, establishing a strong baseline and unified infrastructure for future Widget2Code research.
MetaWriter: Personalized Handwritten Text Recognition Using Meta-Learned Prompt Tuning
May 26, 2025
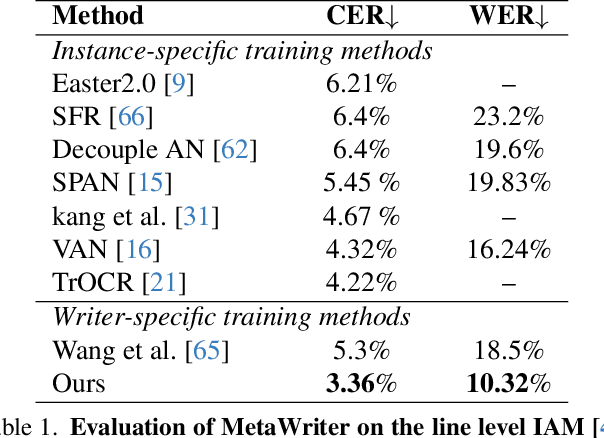
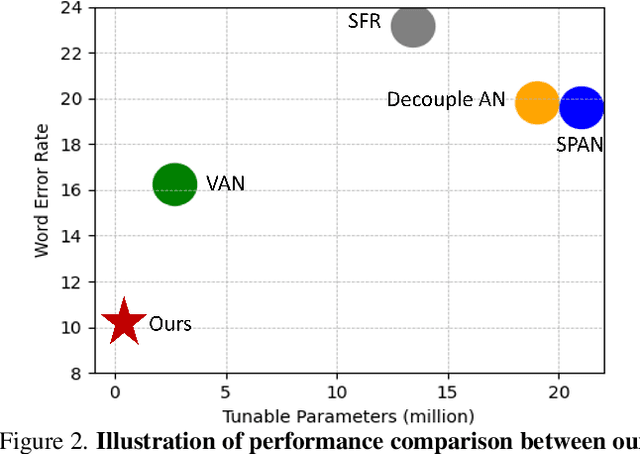

Recent advancements in handwritten text recognition (HTR) have enabled the effective conversion of handwritten text to digital formats. However, achieving robust recognition across diverse writing styles remains challenging. Traditional HTR methods lack writer-specific personalization at test time due to limitations in model architecture and training strategies. Existing attempts to bridge this gap, through gradient-based meta-learning, still require labeled examples and suffer from parameter-inefficient fine-tuning, leading to substantial computational and memory overhead. To overcome these challenges, we propose an efficient framework that formulates personalization as prompt tuning, incorporating an auxiliary image reconstruction task with a self-supervised loss to guide prompt adaptation with unlabeled test-time examples. To ensure self-supervised loss effectively minimizes text recognition error, we leverage meta-learning to learn the optimal initialization of the prompts. As a result, our method allows the model to efficiently capture unique writing styles by updating less than 1% of its parameters and eliminating the need for time-intensive annotation processes. We validate our approach on the RIMES and IAM Handwriting Database benchmarks, where it consistently outperforms previous state-of-the-art methods while using 20x fewer parameters. We believe this represents a significant advancement in personalized handwritten text recognition, paving the way for more reliable and practical deployment in resource-constrained scenarios.
Distribution Alignment for Fully Test-Time Adaptation with Dynamic Online Data Streams
Jul 16, 2024
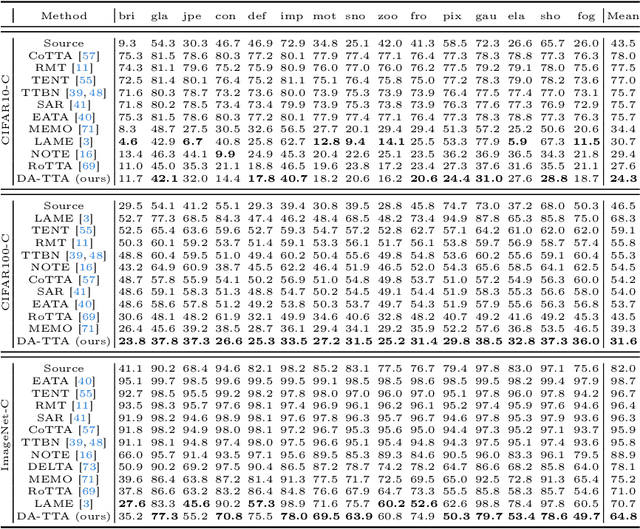

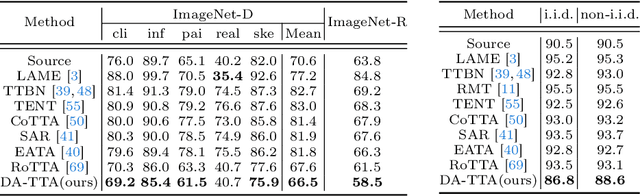
Given a model trained on source data, Test-Time Adaptation (TTA) enables adaptation and inference in test data streams with domain shifts from the source. Current methods predominantly optimize the model for each incoming test data batch using self-training loss. While these methods yield commendable results in ideal test data streams, where batches are independently and identically sampled from the target distribution, they falter under more practical test data streams that are not independent and identically distributed (non-i.i.d.). The data batches in a non-i.i.d. stream display prominent label shifts relative to each other. It leads to conflicting optimization objectives among batches during the TTA process. Given the inherent risks of adapting the source model to unpredictable test-time distributions, we reverse the adaptation process and propose a novel Distribution Alignment loss for TTA. This loss guides the distributions of test-time features back towards the source distributions, which ensures compatibility with the well-trained source model and eliminates the pitfalls associated with conflicting optimization objectives. Moreover, we devise a domain shift detection mechanism to extend the success of our proposed TTA method in the continual domain shift scenarios. Our extensive experiments validate the logic and efficacy of our method. On six benchmark datasets, we surpass existing methods in non-i.i.d. scenarios and maintain competitive performance under the ideal i.i.d. assumption.
Adapting to Distribution Shift by Visual Domain Prompt Generation
May 05, 2024



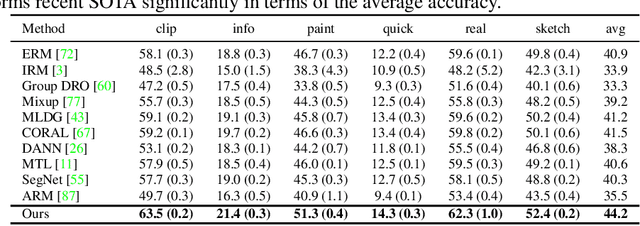
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Meta-DMoE: Adapting to Domain Shift by Meta-Distillation from Mixture-of-Experts
Oct 08, 2022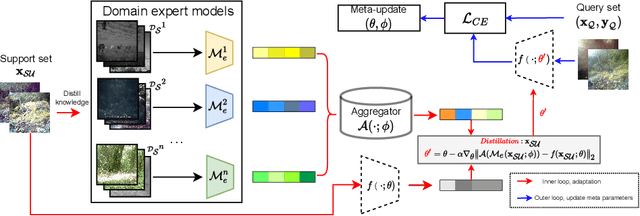
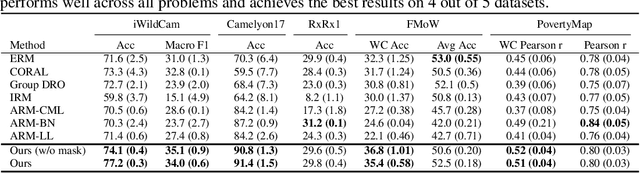

In this paper, we tackle the problem of domain shift. Most existing methods perform training on multiple source domains using a single model, and the same trained model is used on all unseen target domains. Such solutions are sub-optimal as each target domain exhibits its own speciality, which is not adapted. Furthermore, expecting the single-model training to learn extensive knowledge from the multiple source domains is counterintuitive. The model is more biased toward learning only domain-invariant features and may result in negative knowledge transfer. In this work, we propose a novel framework for unsupervised test-time adaptation, which is formulated as a knowledge distillation process to address domain shift. Specifically, we incorporate Mixture-of-Experts (MoE) as teachers, where each expert is separately trained on different source domains to maximize their speciality. Given a test-time target domain, a small set of unlabeled data is sampled to query the knowledge from MoE. As the source domains are correlated to the target domains, a transformer-based aggregator then combines the domain knowledge by examining the interconnection among them. The output is treated as a supervision signal to adapt a student prediction network toward the target domain. We further employ meta-learning to enforce the aggregator to distill positive knowledge and the student network to achieve fast adaptation. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art and validates the effectiveness of each proposed component. Our code is available at https://github.com/n3il666/Meta-DMoE.
Improving ProtoNet for Few-Shot Video Object Recognition: Winner of ORBIT Challenge 2022
Oct 01, 2022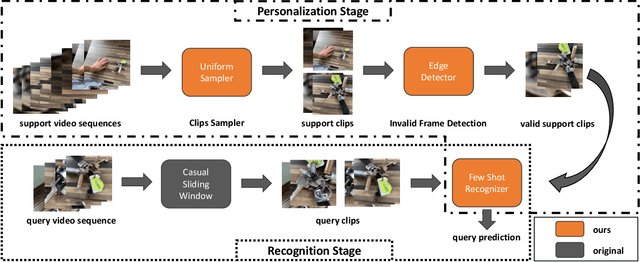
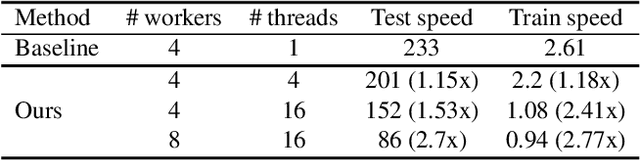
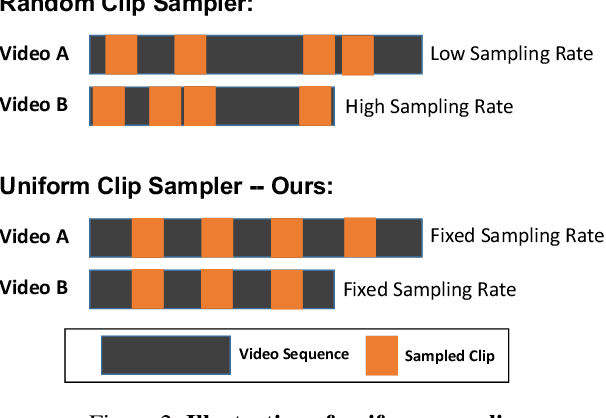
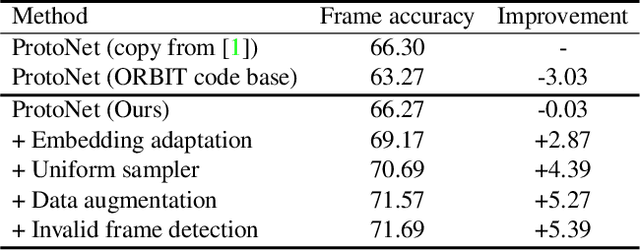
In this work, we present the winning solution for ORBIT Few-Shot Video Object Recognition Challenge 2022. Built upon the ProtoNet baseline, the performance of our method is improved with three effective techniques. These techniques include the embedding adaptation, the uniform video clip sampler and the invalid frame detection. In addition, we re-factor and re-implement the official codebase to encourage modularity, compatibility and improved performance. Our implementation accelerates the data loading in both training and testing.
Few-Shot Class-Incremental Learning via Entropy-Regularized Data-Free Replay
Jul 22, 2022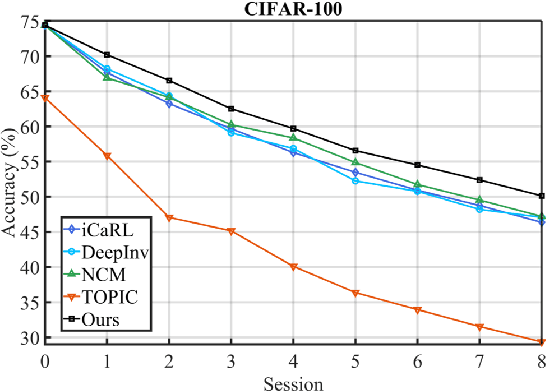
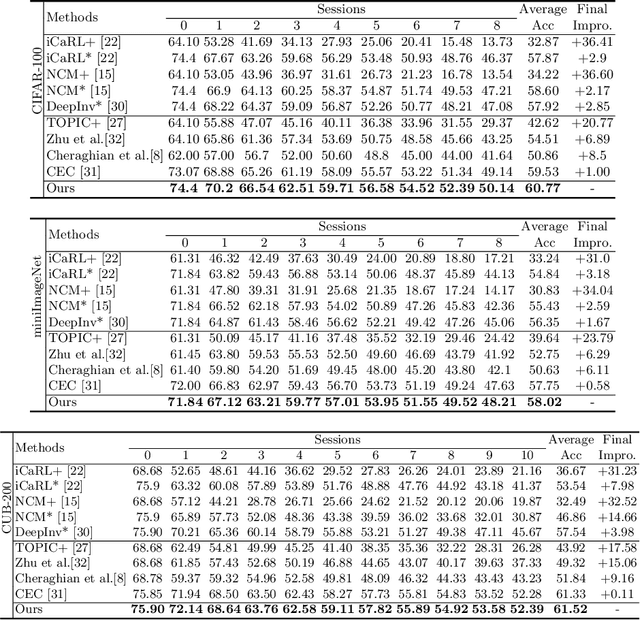

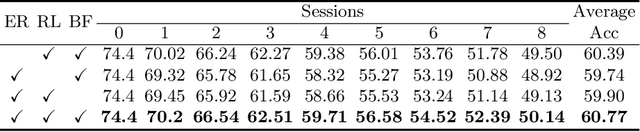
Few-shot class-incremental learning (FSCIL) has been proposed aiming to enable a deep learning system to incrementally learn new classes with limited data. Recently, a pioneer claims that the commonly used replay-based method in class-incremental learning (CIL) is ineffective and thus not preferred for FSCIL. This has, if truth, a significant influence on the fields of FSCIL. In this paper, we show through empirical results that adopting the data replay is surprisingly favorable. However, storing and replaying old data can lead to a privacy concern. To address this issue, we alternatively propose using data-free replay that can synthesize data by a generator without accessing real data. In observing the the effectiveness of uncertain data for knowledge distillation, we impose entropy regularization in the generator training to encourage more uncertain examples. Moreover, we propose to relabel the generated data with one-hot-like labels. This modification allows the network to learn by solely minimizing the cross-entropy loss, which mitigates the problem of balancing different objectives in the conventional knowledge distillation approach. Finally, we show extensive experimental results and analysis on CIFAR-100, miniImageNet and CUB-200 to demonstrate the effectiveness of our proposed one.
Estimating and Improving Fairness with Adversarial Learning
Mar 07, 2021



Fairness and accountability are two essential pillars for trustworthy Artificial Intelligence (AI) in healthcare. However, the existing AI model may be biased in its decision marking. To tackle this issue, we propose an adversarial multi-task training strategy to simultaneously mitigate and detect bias in the deep learning-based medical image analysis system. Specifically, we propose to add a discrimination module against bias and a critical module that predicts unfairness within the base classification model. We further impose an orthogonality regularization to force the two modules to be independent during training. Hence, we can keep these deep learning tasks distinct from one another, and avoid collapsing them into a singular point on the manifold. Through this adversarial training method, the data from the underprivileged group, which is vulnerable to bias because of attributes such as sex and skin tone, are transferred into a domain that is neutral relative to these attributes. Furthermore, the critical module can predict fairness scores for the data with unknown sensitive attributes. We evaluate our framework on a large-scale public-available skin lesion dataset under various fairness evaluation metrics. The experiments demonstrate the effectiveness of our proposed method for estimating and improving fairness in the deep learning-based medical image analysis system.
DMM-Net: Differentiable Mask-Matching Network for Video Object Segmentation
Sep 27, 2019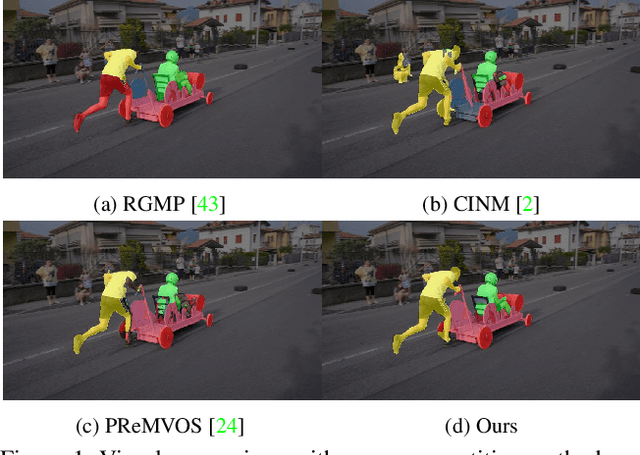



In this paper, we propose the differentiable mask-matching network (DMM-Net) for solving the video object segmentation problem where the initial object masks are provided. Relying on the Mask R-CNN backbone, we extract mask proposals per frame and formulate the matching between object templates and proposals at one time step as a linear assignment problem where the cost matrix is predicted by a CNN. We propose a differentiable matching layer by unrolling a projected gradient descent algorithm in which the projection exploits the Dykstra's algorithm. We prove that under mild conditions, the matching is guaranteed to converge to the optimum. In practice, it performs similarly to the Hungarian algorithm during inference. Meanwhile, we can back-propagate through it to learn the cost matrix. After matching, a refinement head is leveraged to improve the quality of the matched mask. Our DMM-Net achieves competitive results on the largest video object segmentation dataset YouTube-VOS. On DAVIS 2017, DMM-Net achieves the best performance without online learning on the first frames. Without any fine-tuning, DMM-Net performs comparably to state-of-the-art methods on SegTrack v2 dataset. At last, our matching layer is very simple to implement; we attach the PyTorch code ($<50$ lines) in the supplementary material. Our code is released at https://github.com/ZENGXH/DMM_Net.
Adversarial Distillation of Bayesian Neural Network Posteriors
Jun 27, 2018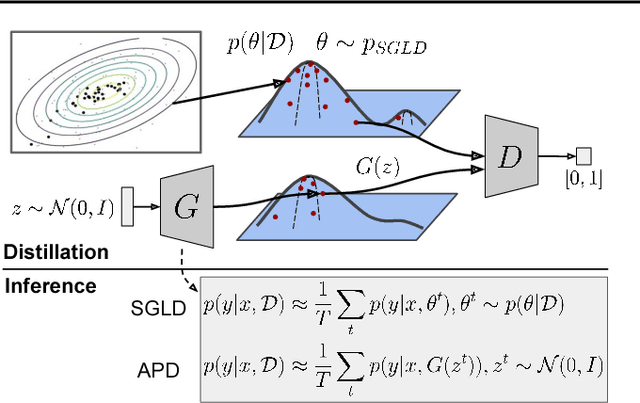



Bayesian neural networks (BNNs) allow us to reason about uncertainty in a principled way. Stochastic Gradient Langevin Dynamics (SGLD) enables efficient BNN learning by drawing samples from the BNN posterior using mini-batches. However, SGLD and its extensions require storage of many copies of the model parameters, a potentially prohibitive cost, especially for large neural networks. We propose a framework, Adversarial Posterior Distillation, to distill the SGLD samples using a Generative Adversarial Network (GAN). At test-time, samples are generated by the GAN. We show that this distillation framework incurs no loss in performance on recent BNN applications including anomaly detection, active learning, and defense against adversarial attacks. By construction, our framework not only distills the Bayesian predictive distribution, but the posterior itself. This allows one to compute quantities such as the approximate model variance, which is useful in downstream tasks. To our knowledge, these are the first results applying MCMC-based BNNs to the aforementioned downstream applications.