 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapTalk: Text-Guided Stylization and Speech-Driven 3D Head Animation
May 28, 2026Audio-driven 3D facial animation aims to generate synchronized lip movements and vivid facial expressions from arbitrary audio clips. While existing methods can produce synchronized lip motions, they often rely on predefined identity or style latent features, which limits users' ability to freely control speaking styles. Moreover, applying a fixed style or identity to an entire audio segment typically results in facial animation styles that do not adapt to the emotional content of the audio. To address these challenges, we revisit the entanglement between style and emotion, construct a large-scale dataset with textual descriptions of both style and emotion, and propose a novel talking head generation framework that enables separate control over style and emotion. Our model takes as input both textual descriptions of speaking style and character emotion, as well as the driving audio stream, enabling real-time generation of highly synchronized lip movements and facial expressions that match the provided descriptions. Furthermore, our model supports dynamic emotion control during inference, allowing it to handle scenarios where the target emotion changes throughout the speech.
RAWild: Sensor-Agnostic RAW Object Detection via Physics-Guided Curve and Grid Modeling
May 07, 2026Camera sensor RAW data offers intrinsic advantages for object detection, including deeper bit depth, preserved physical information, and freedom from image signal processor (ISP) distortions. However, varying exposure conditions, spectral sensitivities, and bit depths across devices introduce substantially larger domain gaps than sRGB, making sensor-agnostic generalization a fundamental challenge. In this study, we present \textbf{RAWild}, a physics-guided global-local tone mapping framework for sensor-agnostic RAW object detection. By factoring sensor-induced variations into a global tonal correction and a spatially adaptive local color adjustment, both driven by RAW distribution priors, our framework enables a single network to train jointly across heterogeneous sensors. To further support cross-sensor generalization, we construct a physics-based RAW simulation pipeline that synthesizes realistic sensor outputs spanning diverse spectral sensitivities, illuminants, and sensor non-idealities. Extensive experiments across multiple RAW benchmarks covering bit depths from 10 to 24 demonstrate state-of-the-art (SOTA) performance under single-dataset, mixed-dataset, and challenging robustness settings.
FluxFlow: Conservative Flow-Matching for Astronomical Image Super-Resolution
May 05, 2026Ground-to-space astronomical super-resolution requires recovering space-quality images from ground-based observations that are simultaneously limited by pixel sampling resolution and atmospheric seeing, which imposes a stochastic, spatially varying PSF that cannot be resolved through upsampling alone. Existing methods rely on synthetic training pairs that fail to capture real atmospheric statistics and are prone to either over-smoothed reconstructions or hallucination sources with no physical counterpart in the observed sky. We propose FluxFlow, a conservative pixel-space flow-matching framework that incorporates observation uncertainty and source-region importance weights during training, and a training-free Wiener-regularized test-time correction to suppress hallucination sources while preserving recovered detail. We further construct the DESI--HST Dataset, the large-scale real-world benchmark comprising 19,500 real co-registered ground-to-space image pairs with real atmospheric PSF variation. Experiments demonstrate that FluxFlow consistently outperforms existing baseline methods in both photometric and scientific accuracy.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
MERIT: Multi-domain Efficient RAW Image Translation
Mar 21, 2026RAW images captured by different camera sensors exhibit substantial domain shifts due to varying spectral responses, noise characteristics, and tone behaviors, complicating their direct use in downstream computer vision tasks. Prior methods address this problem by training domain-specific RAW-to-RAW translators for each source-target pair, but such approaches do not scale to real-world scenarios involving multiple types of commercial cameras. In this work, we introduce MERIT, the first unified framework for multi-domain RAW image translation, which leverages a single model to perform translations across arbitrary camera domains. To address domain-specific noise discrepancies, we propose a sensor-aware noise modeling loss that explicitly aligns the signal-dependent noise statistics of the generated images with those of the target domain. We further enhance the generator with a conditional multi-scale large kernel attention module for improved context and sensor-aware feature modeling. To facilitate standardized evaluation, we introduce MDRAW, the first dataset tailored for multi-domain RAW image translation, comprising both paired and unpaired RAW captures from five diverse camera sensors across a wide range of scenes. Extensive experiments demonstrate that MERIT outperforms prior models in both quality (5.56 dB improvement) and scalability (80% reduction in training iterations).
Denoising the Deep Sky: Physics-Based CCD Noise Formation for Astronomical Imaging
Jan 30, 2026Astronomical imaging remains noise-limited under practical observing constraints, while standard calibration pipelines mainly remove structured artifacts and leave stochastic noise largely unresolved. Learning-based denoising is promising, yet progress is hindered by scarce paired training data and the need for physically interpretable and reproducible models in scientific workflows. We propose a physics-based noise synthesis framework tailored to CCD noise formation. The pipeline models photon shot noise, photo-response non-uniformity, dark-current noise, readout effects, and localized outliers arising from cosmic-ray hits and hot pixels. To obtain low-noise inputs for synthesis, we average multiple unregistered exposures to produce high-SNR bases. Realistic noisy counterparts synthesized from these bases using our noise model enable the construction of abundant paired datasets for supervised learning. We further introduce a real-world dataset across multi-bands acquired with two twin ground-based telescopes, providing paired raw frames and instrument-pipeline calibrated frames, together with calibration data and stacked high-SNR bases for real-world evaluation.
RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and Reconstruction
Dec 29, 2025We introduce RealX3D, a real-capture benchmark for multi-view visual restoration and 3D reconstruction under diverse physical degradations. RealX3D groups corruptions into four families, including illumination, scattering, occlusion, and blurring, and captures each at multiple severity levels using a unified acquisition protocol that yields pixel-aligned LQ/GT views. Each scene includes high-resolution capture, RAW images, and dense laser scans, from which we derive world-scale meshes and metric depth. Benchmarking a broad range of optimization-based and feed-forward methods shows substantial degradation in reconstruction quality under physical corruptions, underscoring the fragility of current multi-view pipelines in real-world challenging environments.
Perception-Inspired Color Space Design for Photo White Balance Editing
Dec 11, 2025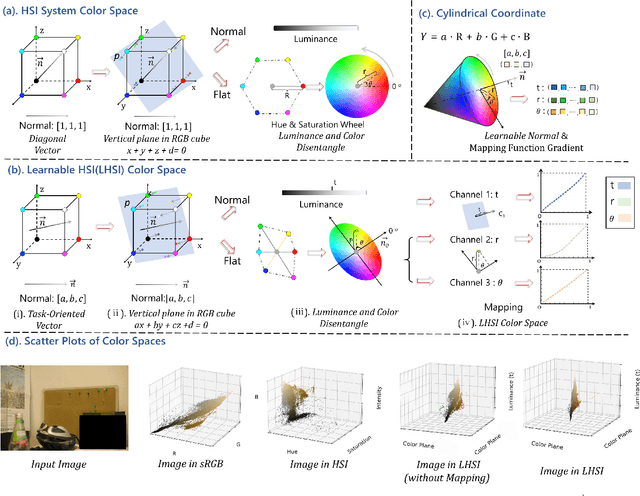
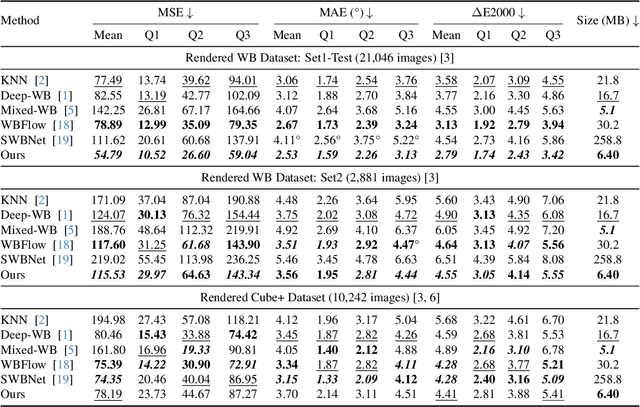
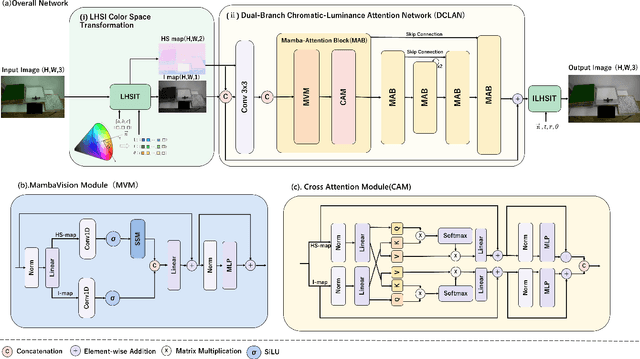
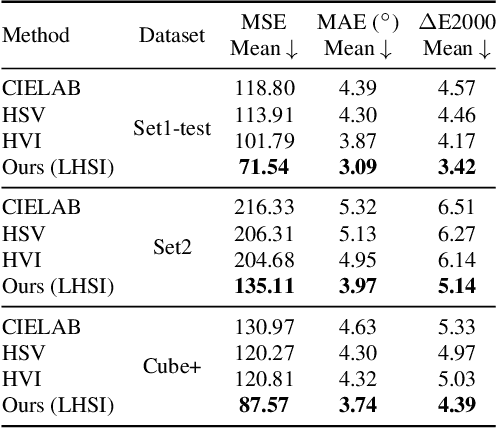
White balance (WB) is a key step in the image signal processor (ISP) pipeline that mitigates color casts caused by varying illumination and restores the scene's true colors. Currently, sRGB-based WB editing for post-ISP WB correction is widely used to address color constancy failures in the ISP pipeline when the original camera RAW is unavailable. However, additive color models (e.g., sRGB) are inherently limited by fixed nonlinear transformations and entangled color channels, which often impede their generalization to complex lighting conditions. To address these challenges, we propose a novel framework for WB correction that leverages a perception-inspired Learnable HSI (LHSI) color space. Built upon a cylindrical color model that naturally separates luminance from chromatic components, our framework further introduces dedicated parameters to enhance this disentanglement and learnable mapping to adaptively refine the flexibility. Moreover, a new Mamba-based network is introduced, which is tailored to the characteristics of the proposed LHSI color space. Experimental results on benchmark datasets demonstrate the superiority of our method, highlighting the potential of perception-inspired color space design in computational photography. The source code is available at https://github.com/YangCheng58/WB_Color_Space.
Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Apr 02, 2025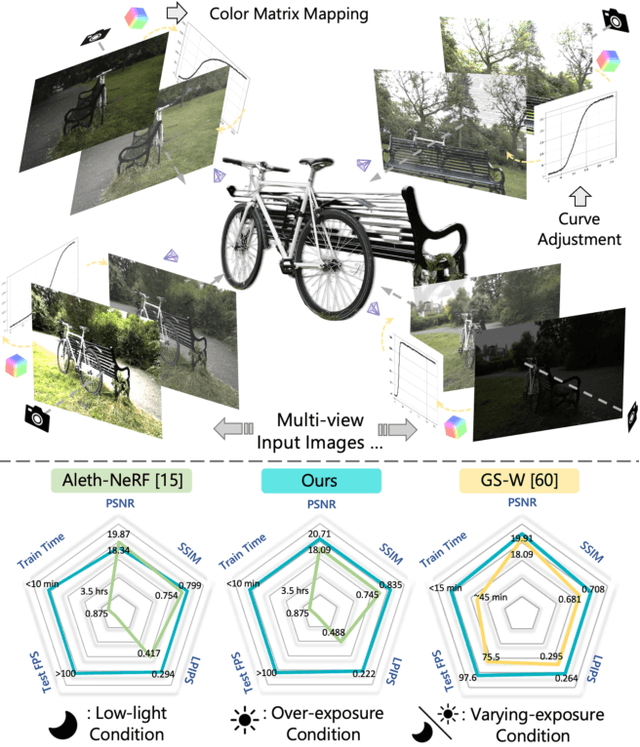
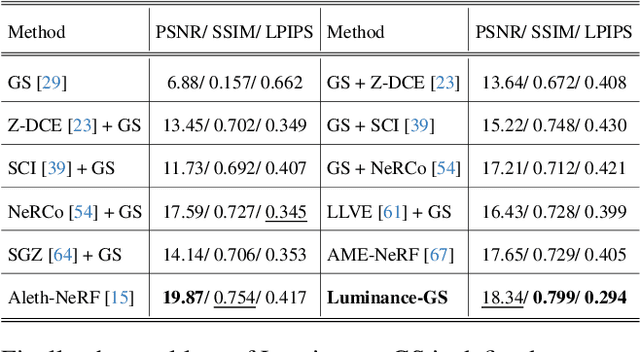
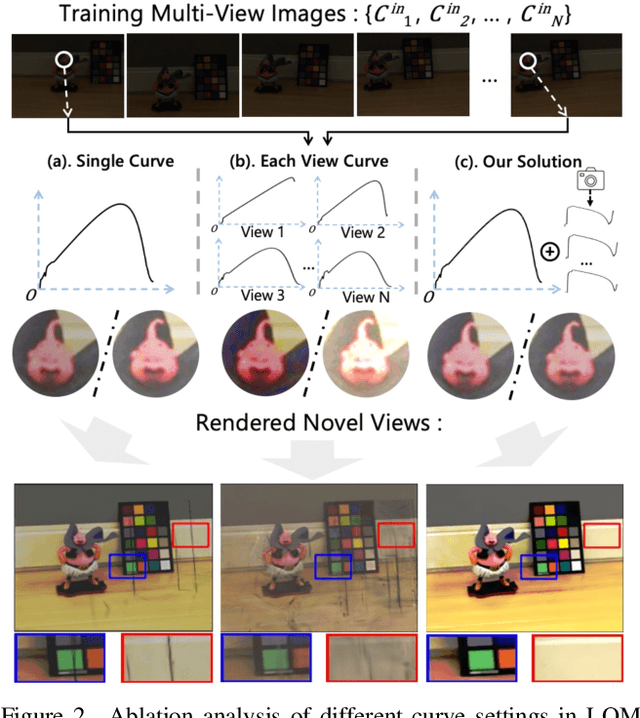
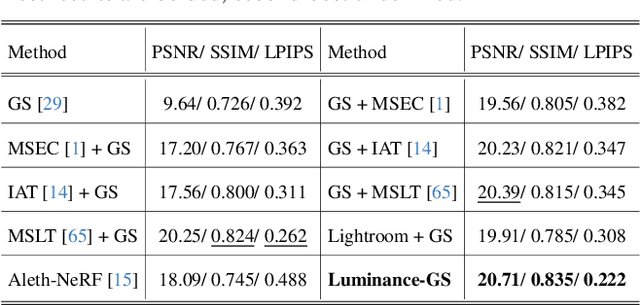
Capturing high-quality photographs under diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) significantly impact image quality. This challenge becomes more pronounced in multi-view scenarios, where variations in lighting and image signal processor (ISP) settings across viewpoints introduce photometric inconsistencies. Such lighting degradations and view-dependent variations pose substantial challenges to novel view synthesis (NVS) frameworks based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). To address this, we introduce Luminance-GS, a novel approach to achieving high-quality novel view synthesis results under diverse challenging lighting conditions using 3DGS. By adopting per-view color matrix mapping and view-adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions -- including low-light, overexposure, and varying exposure -- while not altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality.