 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Vector Field Generation via Score-based Diffusion Model
Apr 27, 2026Guiding Vector Fields (GVFs) are a powerful tool for robotic path following. However, classical methods assume smooth, ordered curves and fail when paths are unordered, multi-branch, or generated by probabilistic models. We propose a unified framework, termed the Score-Induced Guiding Vector Field (SGVF), which leverages score-based generative modeling to construct vector fields directly from data distributions. SGVF learns tangent fields from point clouds with unit-norm, orthogonality, and directional-consistency losses, ensuring geometric fidelity and control feasibility. This approach removes the reliance on ad-hoc path segmentation and enables guidance along complex topologies such as branching and pseudo-manifolds. The study establishes a correspondence between score vanishing in diffusion models and GVF singularities and highlights representational capacity near sharp path curvatures. Experiments on robotic navigation in planar environments demonstrate that SGVF achieves reliable path following in scenarios where classical GVFs fail, underscoring its potential as a bridge between generative modeling and geometric control. Code and experiment video are available at https://github.com/czr-gif/Guiding-Vector-Field-Generation-via-Score-based-Diffusion-Model.
Ontology-Enhanced Knowledge Graph Completion using Large Language Models
Jul 28, 2025Large Language Models (LLMs) have been extensively adopted in Knowledge Graph Completion (KGC), showcasing significant research advancements. However, as black-box models driven by deep neural architectures, current LLM-based KGC methods rely on implicit knowledge representation with parallel propagation of erroneous knowledge, thereby hindering their ability to produce conclusive and decisive reasoning outcomes. We aim to integrate neural-perceptual structural information with ontological knowledge, leveraging the powerful capabilities of LLMs to achieve a deeper understanding of the intrinsic logic of the knowledge. We propose an ontology enhanced KGC method using LLMs -- OL-KGC. It first leverages neural perceptual mechanisms to effectively embed structural information into the textual space, and then uses an automated extraction algorithm to retrieve ontological knowledge from the knowledge graphs (KGs) that needs to be completed, which is further transformed into a textual format comprehensible to LLMs for providing logic guidance. We conducted extensive experiments on three widely-used benchmarks -- FB15K-237, UMLS and WN18RR. The experimental results demonstrate that OL-KGC significantly outperforms existing mainstream KGC methods across multiple evaluation metrics, achieving state-of-the-art performance.
Multi-View Wireless Sensing via Conditional Generative Learning: Framework and Model Design
May 19, 2025In this paper, we incorporate physical knowledge into learning-based high-precision target sensing using the multi-view channel state information (CSI) between multiple base stations (BSs) and user equipment (UEs). Such kind of multi-view sensing problem can be naturally cast into a conditional generation framework. To this end, we design a bipartite neural network architecture, the first part of which uses an elaborately designed encoder to fuse the latent target features embedded in the multi-view CSI, and then the second uses them as conditioning inputs of a powerful generative model to guide the target's reconstruction. Specifically, the encoder is designed to capture the physical correlation between the CSI and the target, and also be adaptive to the numbers and positions of BS-UE pairs. Therein the view-specific nature of CSI is assimilated by introducing a spatial positional embedding scheme, which exploits the structure of electromagnetic(EM)-wave propagation channels. Finally, a conditional diffusion model with a weighted loss is employed to generate the target's point cloud from the fused features. Extensive numerical results demonstrate that the proposed generative multi-view (Gen-MV) sensing framework exhibits excellent flexibility and significant performance improvement on the reconstruction quality of target's shape and EM properties.
Analogical Learning for Cross-Scenario Generalization: Framework and Application to Intelligent Localization
Apr 09, 2025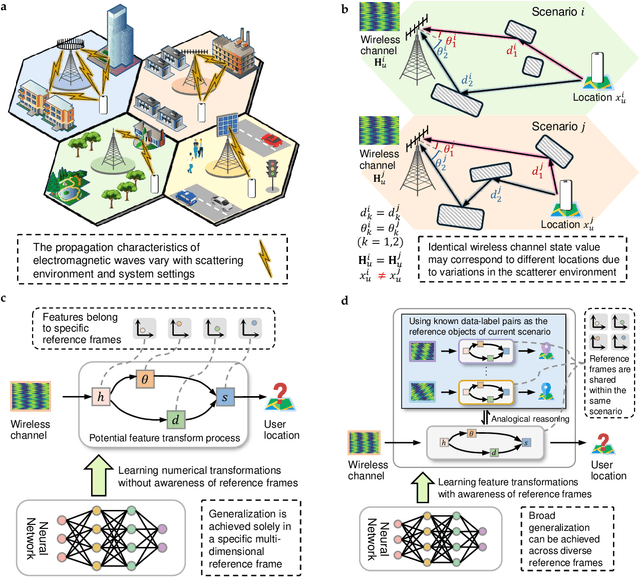
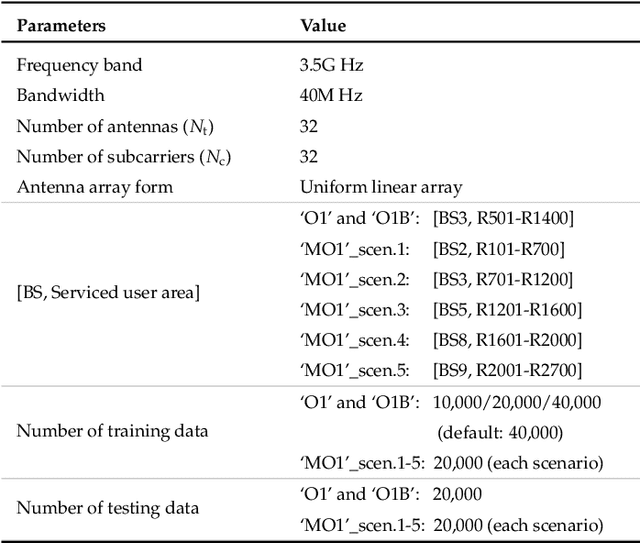
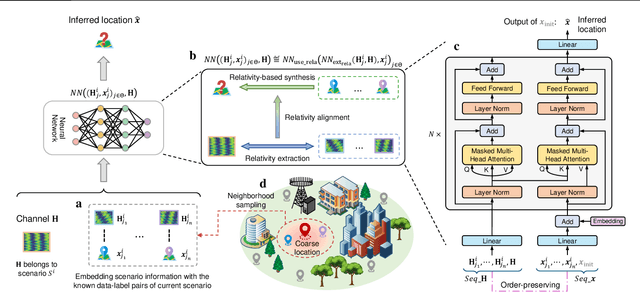

Existing learning models often exhibit poor generalization when deployed across diverse scenarios. It is mainly due to that the underlying reference frame of the data varies with the deployment environment and settings. However, despite the data of each scenario has its distinct reference frame, its generation generally follows the same underlying physical rule. Based on these findings, this article proposes a brand-new universal deep learning framework named analogical learning (AL), which provides a highly efficient way to implicitly retrieve the reference frame information associated with a scenario and then to make accurate prediction by relative analogy across scenarios. Specifically, an elegant bipartite neural network architecture called Mateformer is designed, the first part of which calculates the relativity within multiple feature spaces between the input data and a small amount of embedded data from the current scenario, while the second part uses these relativity to guide the nonlinear analogy. We apply AL to the typical multi-scenario learning problem of intelligent wireless localization in cellular networks. Extensive experiments show that AL achieves state-of-the-art accuracy, stable transferability and robust adaptation to new scenarios without any tuning, and outperforming conventional methods with a precision improvement of nearly two orders of magnitude. All data and code are available at https://github.com/ziruichen-research/ALLoc.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Paleoinspired Vision: From Exploring Colour Vision Evolution to Inspiring Camera Design
Dec 27, 2024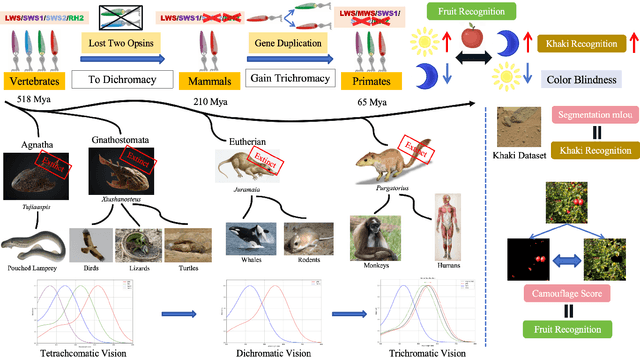
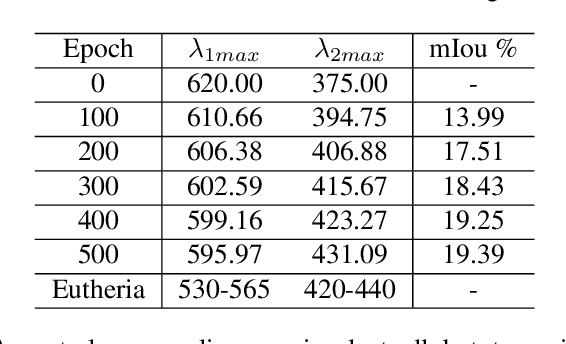
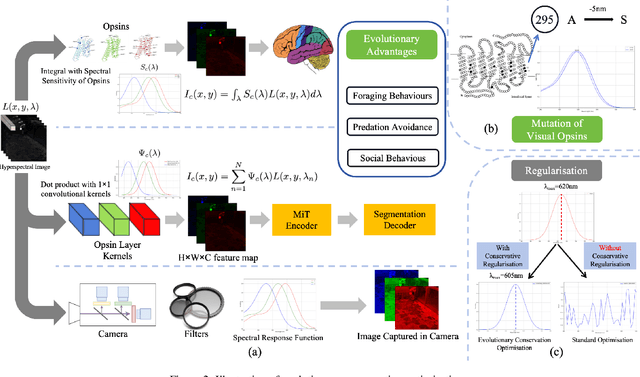

The evolution of colour vision is captivating, as it reveals the adaptive strategies of extinct species while simultaneously inspiring innovations in modern imaging technology. In this study, we present a simplified model of visual transduction in the retina, introducing a novel opsin layer. We quantify evolutionary pressures by measuring machine vision recognition accuracy on colour images shaped by specific opsins. Building on this, we develop an evolutionary conservation optimisation algorithm to reconstruct the spectral sensitivity of opsins, enabling mutation-driven adaptations to to more effectively spot fruits or predators. This model condenses millions of years of evolution within seconds on GPU, providing an experimental framework to test long-standing hypotheses in evolutionary biology , such as vision of early mammals, primate trichromacy from gene duplication, retention of colour blindness, blue-shift of fish rod and multiple rod opsins with bioluminescence. Moreover, the model enables speculative explorations of hypothetical species, such as organisms with eyes adapted to the conditions on Mars. Our findings suggest a minimalist yet effective approach to task-specific camera filter design, optimising the spectral response function to meet application-driven demands. The code will be made publicly available upon acceptance.
Towards Wireless-Native Big AI Model: Insights into Its Ambitions, Peculiarities and Methodologies
Dec 12, 2024Researches on leveraging big artificial intelligence model (BAIM) technology to drive the intelligent evolution of wireless networks are emerging. However, since the breakthrough in generalization brought about by BAIM techniques mainly occurs in natural language processing, there is still a lack of a clear technical roadmap on how to efficiently apply BAIM techniques to wireless systems with many additional peculiarities. To this end, this paper first reviews recent research works on BAIM for wireless and assesses the current research situation. Then, this paper analyzes and compares the differences between language intelligence and wireless intelligence on multiple levels, including scientific foundations, core usages, and technical details. It highlights the necessity and scientific significance of developing BAIM technology in a wireless-native way, as well as new issues that need to be considered in specific technical implementation. Finally, by synthesizing the evolutionary laws of language models with the particularities of wireless system, this paper provides several instructive methodologies for how to develop wireless-native BAIM.
Universal dimensions of visual representation
Aug 23, 2024
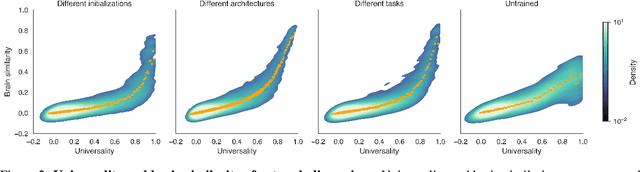
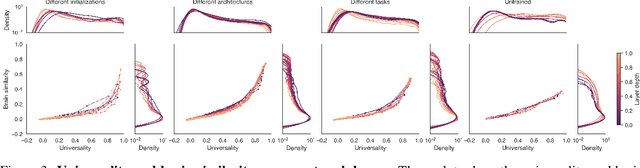
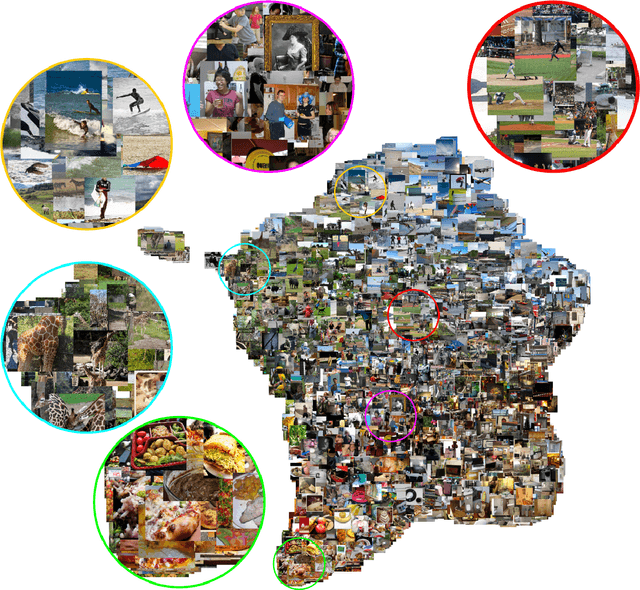
Do neural network models of vision learn brain-aligned representations because they share architectural constraints and task objectives with biological vision or because they learn universal features of natural image processing? We characterized the universality of hundreds of thousands of representational dimensions from visual neural networks with varied construction. We found that networks with varied architectures and task objectives learn to represent natural images using a shared set of latent dimensions, despite appearing highly distinct at a surface level. Next, by comparing these networks with human brain representations measured with fMRI, we found that the most brain-aligned representations in neural networks are those that are universal and independent of a network's specific characteristics. Remarkably, each network can be reduced to fewer than ten of its most universal dimensions with little impact on its representational similarity to the human brain. These results suggest that the underlying similarities between artificial and biological vision are primarily governed by a core set of universal image representations that are convergently learned by diverse systems.
Large Language Model Enhanced Knowledge Representation Learning: A Survey
Jul 01, 2024



The integration of Large Language Models (LLMs) with Knowledge Representation Learning (KRL) signifies a pivotal advancement in the field of artificial intelligence, enhancing the ability to capture and utilize complex knowledge structures. This synergy leverages the advanced linguistic and contextual understanding capabilities of LLMs to improve the accuracy, adaptability, and efficacy of KRL, thereby expanding its applications and potential. Despite the increasing volume of research focused on embedding LLMs within the domain of knowledge representation, a thorough review that examines the fundamental components and processes of these enhanced models is conspicuously absent. Our survey addresses this by categorizing these models based on three distinct Transformer architectures, and by analyzing experimental data from various KRL downstream tasks to evaluate the strengths and weaknesses of each approach. Finally, we identify and explore potential future research directions in this emerging yet underexplored domain, proposing pathways for continued progress.
VBIM-Net: Variational Born Iterative Network for Inverse Scattering Problems
May 29, 2024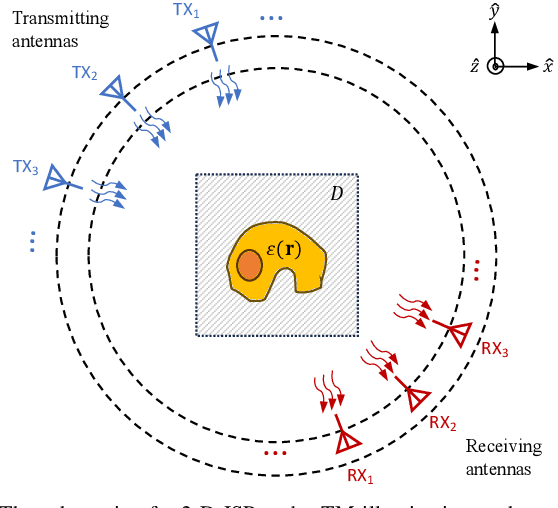



Recently, studies have shown the potential of integrating field-type iterative methods with deep learning (DL) techniques in solving inverse scattering problems (ISPs). In this article, we propose a novel Variational Born Iterative Network, namely, VBIM-Net, to solve the full-wave ISPs with significantly improved flexibility and inversion quality. The proposed VBIM-Net emulates the alternating updates of the total electric field and the contrast in the variational Born iterative method (VBIM) by multiple layers of subnetworks. We embed the calculation of the contrast variation into each of the subnetworks, converting the scattered field residual into an approximate contrast variation and then enhancing it by a U-Net, thus avoiding the requirement of matched measurement dimension and grid resolution as in existing approaches. The total field and contrast of each layer's output is supervised in the loss function of VBIM-Net, which guarantees the physical interpretability of variables of the subnetworks. In addition, we design a training scheme with extra noise to enhance the model's stability. Extensive numerical results on synthetic and experimental data both verify the inversion quality, generalization ability, and robustness of the proposed VBIM-Net. This work may provide some new inspiration for the design of efficient field-type DL schemes.