 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
LoRAP: Low-Rank Aggregation Prompting for Quantized Graph Neural Networks Training
Jan 21, 2026Graph Neural Networks (GNNs) are neural networks that aim to process graph data, capturing the relationships and interactions between nodes using the message-passing mechanism. GNN quantization has emerged as a promising approach for reducing model size and accelerating inference in resource-constrained environments. Compared to quantization in LLMs, quantizing graph features is more emphasized in GNNs. Inspired by the above, we propose to leverage prompt learning, which manipulates the input data, to improve the performance of quantization-aware training (QAT) for GNNs. To mitigate the issue that prompting the node features alone can only make part of the quantized aggregation result optimal, we introduce Low-Rank Aggregation Prompting (LoRAP), which injects lightweight, input-dependent prompts into each aggregated feature to optimize the results of quantized aggregations. Extensive evaluations on 4 leading QAT frameworks over 9 graph datasets demonstrate that LoRAP consistently enhances the performance of low-bit quantized GNNs while introducing a minimal computational overhead.
Deep Learning for Semantic Segmentation of 3D Ultrasound Data
Jan 19, 2026Developing cost-efficient and reliable perception systems remains a central challenge for automated vehicles. LiDAR and camera-based systems dominate, yet they present trade-offs in cost, robustness and performance under adverse conditions. This work introduces a novel framework for learning-based 3D semantic segmentation using Calyo Pulse, a modular, solid-state 3D ultrasound sensor system for use in harsh and cluttered environments. A 3D U-Net architecture is introduced and trained on the spatial ultrasound data for volumetric segmentation. Results demonstrate robust segmentation performance from Calyo Pulse sensors, with potential for further improvement through larger datasets, refined ground truth, and weighted loss functions. Importantly, this study highlights 3D ultrasound sensing as a promising complementary modality for reliable autonomy.
AppellateGen: A Benchmark for Appellate Legal Judgment Generation
Jan 08, 2026Legal judgment generation is a critical task in legal intelligence. However, existing research in legal judgment generation has predominantly focused on first-instance trials, relying on static fact-to-verdict mappings while neglecting the dialectical nature of appellate (second-instance) review. To address this, we introduce AppellateGen, a benchmark for second-instance legal judgment generation comprising 7,351 case pairs. The task requires models to draft legally binding judgments by reasoning over the initial verdict and evidentiary updates, thereby modeling the causal dependency between trial stages. We further propose a judicial Standard Operating Procedure (SOP)-based Legal Multi-Agent System (SLMAS) to simulate judicial workflows, which decomposes the generation process into discrete stages of issue identification, retrieval, and drafting. Experimental results indicate that while SLMAS improves logical consistency, the complexity of appellate reasoning remains a substantial challenge for current LLMs. The dataset and code are publicly available at: https://anonymous.4open.science/r/AppellateGen-5763.
Chinese Morph Resolution in E-commerce Live Streaming Scenarios
Dec 29, 2025E-commerce live streaming in China, particularly on platforms like Douyin, has become a major sales channel, but hosts often use morphs to evade scrutiny and engage in false advertising. This study introduces the Live Auditory Morph Resolution (LiveAMR) task to detect such violations. Unlike previous morph research focused on text-based evasion in social media and underground industries, LiveAMR targets pronunciation-based evasion in health and medical live streams. We constructed the first LiveAMR dataset with 86,790 samples and developed a method to transform the task into a text-to-text generation problem. By leveraging large language models (LLMs) to generate additional training data, we improved performance and demonstrated that morph resolution significantly enhances live streaming regulation.
EEG-DLite: Dataset Distillation for Efficient Large EEG Model Training
Dec 13, 2025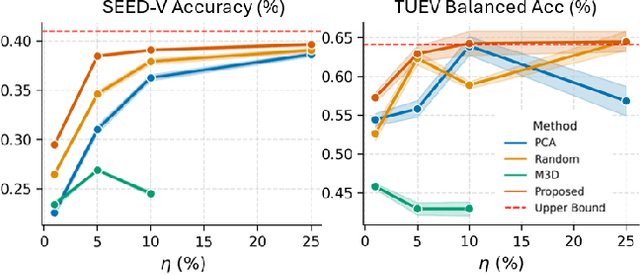
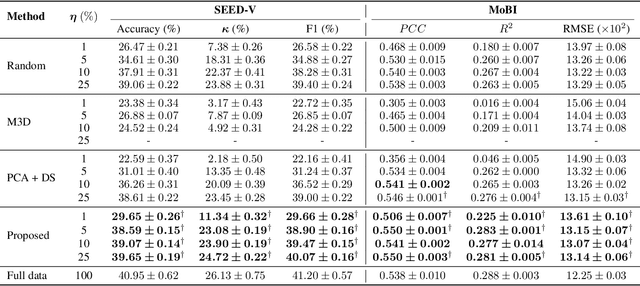
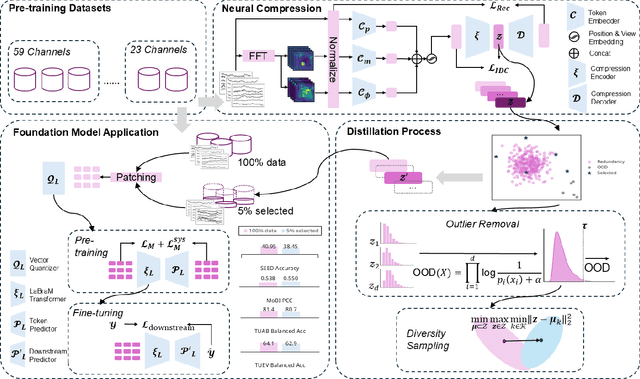
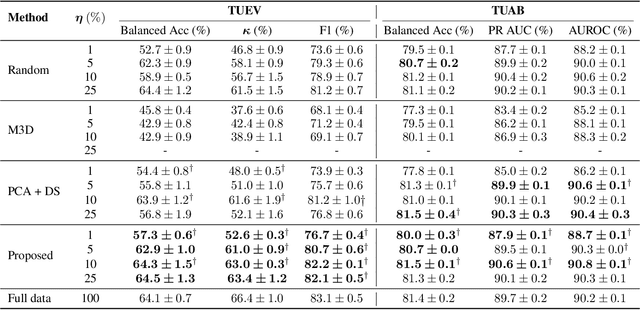
Large-scale EEG foundation models have shown strong generalization across a range of downstream tasks, but their training remains resource-intensive due to the volume and variable quality of EEG data. In this work, we introduce EEG-DLite, a data distillation framework that enables more efficient pre-training by selectively removing noisy and redundant samples from large EEG datasets. EEG-DLite begins by encoding EEG segments into compact latent representations using a self-supervised autoencoder, allowing sample selection to be performed efficiently and with reduced sensitivity to noise. Based on these representations, EEG-DLite filters out outliers and minimizes redundancy, resulting in a smaller yet informative subset that retains the diversity essential for effective foundation model training. Through extensive experiments, we demonstrate that training on only 5 percent of a 2,500-hour dataset curated with EEG-DLite yields performance comparable to, and in some cases better than, training on the full dataset across multiple downstream tasks. To our knowledge, this is the first systematic study of pre-training data distillation in the context of EEG foundation models. EEG-DLite provides a scalable and practical path toward more effective and efficient physiological foundation modeling. The code is available at https://github.com/t170815518/EEG-DLite.
ECHO: Toward Contextual Seq2Seq Paradigms in Large EEG Models
Sep 26, 2025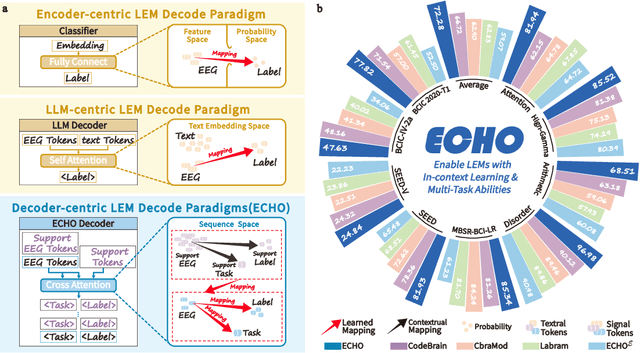
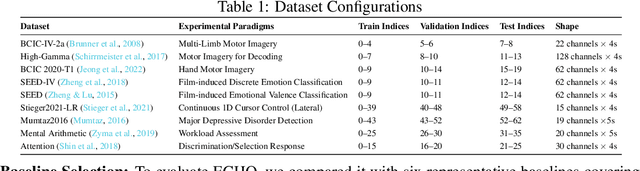
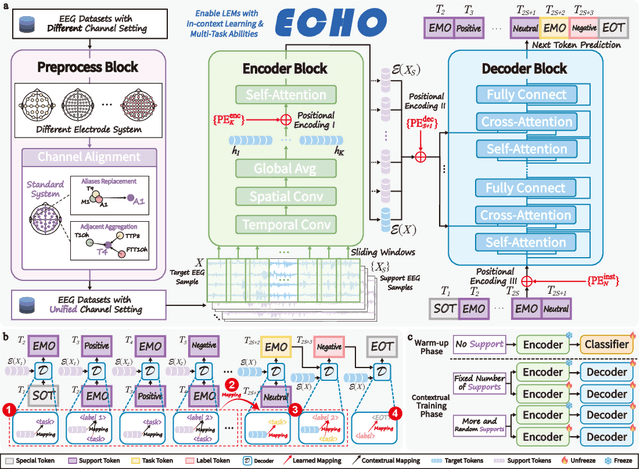
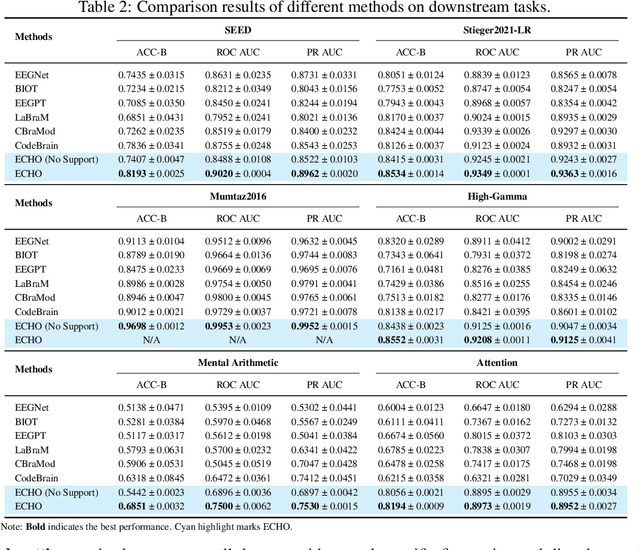
Electroencephalography (EEG), with its broad range of applications, necessitates models that can generalize effectively across various tasks and datasets. Large EEG Models (LEMs) address this by pretraining encoder-centric architectures on large-scale unlabeled data to extract universal representations. While effective, these models lack decoders of comparable capacity, limiting the full utilization of the learned features. To address this issue, we introduce ECHO, a novel decoder-centric LEM paradigm that reformulates EEG modeling as sequence-to-sequence learning. ECHO captures layered relationships among signals, labels, and tasks within sequence space, while incorporating discrete support samples to construct contextual cues. This design equips ECHO with in-context learning, enabling dynamic adaptation to heterogeneous tasks without parameter updates. Extensive experiments across multiple datasets demonstrate that, even with basic model components, ECHO consistently outperforms state-of-the-art single-task LEMs in multi-task settings, showing superior generalization and adaptability.
BrainPro: Towards Large-scale Brain State-aware EEG Representation Learning
Sep 26, 2025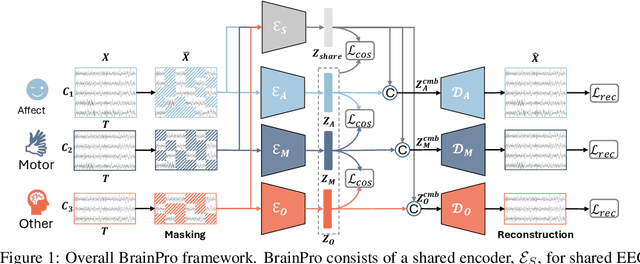
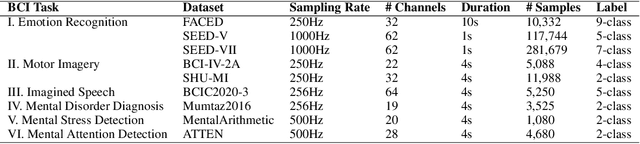
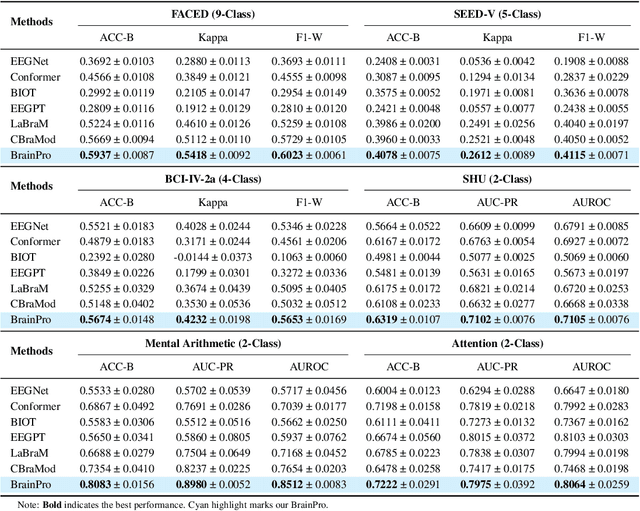
Electroencephalography (EEG) is a non-invasive technique for recording brain electrical activity, widely used in brain-computer interface (BCI) and healthcare. Recent EEG foundation models trained on large-scale datasets have shown improved performance and generalizability over traditional decoding methods, yet significant challenges remain. Existing models often fail to explicitly capture channel-to-channel and region-to-region interactions, which are critical sources of information inherently encoded in EEG signals. Due to varying channel configurations across datasets, they either approximate spatial structure with self-attention or restrict training to a limited set of common channels, sacrificing flexibility and effectiveness. Moreover, although EEG datasets reflect diverse brain states such as emotion, motor, and others, current models rarely learn state-aware representations during self-supervised pre-training. To address these gaps, we propose BrainPro, a large EEG model that introduces a retrieval-based spatial learning block to flexibly capture channel- and region-level interactions across varying electrode layouts, and a brain state-decoupling block that enables state-aware representation learning through parallel encoders with decoupling and region-aware reconstruction losses. This design allows BrainPro to adapt seamlessly to diverse tasks and hardware settings. Pre-trained on an extensive EEG corpus, BrainPro achieves state-of-the-art performance and robust generalization across nine public BCI datasets. Our codes and the pre-trained weights will be released.
Design and Control of a Perching Drone Inspired by the Prey-Capturing Mechanism of Venus Flytrap
Sep 16, 2025



The endurance and energy efficiency of drones remain critical challenges in their design and operation. To extend mission duration, numerous studies explored perching mechanisms that enable drones to conserve energy by temporarily suspending flight. This paper presents a new perching drone that utilizes an active flexible perching mechanism inspired by the rapid predation mechanism of the Venus flytrap, achieving perching in less than 100 ms. The proposed system is designed for high-speed adaptability to the perching targets. The overall drone design is outlined, followed by the development and validation of the biomimetic perching structure. To enhance the system stability, a cascade extended high-gain observer (EHGO) based control method is developed, which can estimate and compensate for the external disturbance in real time. The experimental results demonstrate the adaptability of the perching structure and the superiority of the cascaded EHGO in resisting wind and perching disturbances.
DocR1: Evidence Page-Guided GRPO for Multi-Page Document Understanding
Aug 10, 2025Understanding multi-page documents poses a significant challenge for multimodal large language models (MLLMs), as it requires fine-grained visual comprehension and multi-hop reasoning across pages. While prior work has explored reinforcement learning (RL) for enhancing advanced reasoning in MLLMs, its application to multi-page document understanding remains underexplored. In this paper, we introduce DocR1, an MLLM trained with a novel RL framework, Evidence Page-Guided GRPO (EviGRPO). EviGRPO incorporates an evidence-aware reward mechanism that promotes a coarse-to-fine reasoning strategy, guiding the model to first retrieve relevant pages before generating answers. This training paradigm enables us to build high-quality models with limited supervision. To support this, we design a two-stage annotation pipeline and a curriculum learning strategy, based on which we construct two datasets: EviBench, a high-quality training set with 4.8k examples, and ArxivFullQA, an evaluation benchmark with 8.6k QA pairs based on scientific papers. Extensive experiments across a wide range of benchmarks demonstrate that DocR1 achieves state-of-the-art performance on multi-page tasks, while consistently maintaining strong results on single-page benchmarks.