 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking PhD-Level Coding in 3D Geometric Computer Vision
Mar 31, 2026AI-assisted coding has rapidly reshaped software practice and research workflows, yet today's models still struggle to produce correct code for complex 3D geometric vision. If models could reliably write such code, the research of our community would change substantially. To measure progress toward that goal, we introduce GeoCodeBench, a PhD-level benchmark that evaluates coding for 3D vision. Each problem is a fill-in-the-function implementation task curated from representative papers at recent venues: we first let a tool propose candidate functions from official repositories, then perform careful human screening to select core 3D geometric components. For every target, we generate diverse, edge-case unit tests, enabling fully automatic, reproducible scoring. We evaluate eight representative open- and closed-source models to reflect the current ecosystem. The best model, GPT-5, attains only 36.6% pass rate, revealing a large gap between current capabilities and dependable 3D scientific coding. GeoCodeBench organizes tasks into a two-level hierarchy: General 3D capability (geometric transformations and mechanics/optics formulation) and Research capability (novel algorithm implementation and geometric logic routing). Scores are positively correlated across these axes, but research-oriented tasks are markedly harder. Context ablations further show that "more paper text" is not always better: cutting off at the Method section statistically outperforms full-paper inputs, highlighting unresolved challenges in long-context scientific comprehension. Together, these findings position GeoCodeBench as a rigorous testbed for advancing from generic coding to trustworthy 3D geometric vision coding.
PAM: A Pose-Appearance-Motion Engine for Sim-to-Real HOI Video Generation
Mar 23, 2026Hand-object interaction (HOI) reconstruction and synthesis are becoming central to embodied AI and AR/VR. Yet, despite rapid progress, existing HOI generation research remains fragmented across three disjoint tracks: (1) pose-only synthesis that predicts MANO trajectories without producing pixels; (2) single-image HOI generation that hallucinates appearance from masks or 2D cues but lacks dynamics; and (3) video generation methods that require both the entire pose sequence and the ground-truth first frame as inputs, preventing true sim-to-real deployment. Inspired by the philosophy of Joo et al. (2018), we think that HOI generation requires a unified engine that brings together pose, appearance, and motion within one coherent framework. Thus we introduce PAM: a Pose-Appearance-Motion Engine for controllable HOI video generation. The performance of our engine is validated by: (1) On DexYCB, we obtain an FVD of 29.13 (vs. 38.83 for InterDyn), and MPJPE of 19.37 mm (vs. 30.05 mm for CosHand), while generating higher-resolution 480x720 videos compared to 256x256 and 256x384 baselines. (2) On OAKINK2, our full multi-condition model improves FVD from 68.76 to 46.31. (3) An ablation over input conditions on DexYCB shows that combining depth, segmentation, and keypoints consistently yields the best results. (4) For a downstream hand pose estimation task using SimpleHand, augmenting training with 3,400 synthetic videos (207k frames) allows a model trained on only 50% of the real data plus our synthetic data to match the 100% real baseline.
TwinAligner: Visual-Dynamic Alignment Empowers Physics-aware Real2Sim2Real for Robotic Manipulation
Dec 22, 2025The robotics field is evolving towards data-driven, end-to-end learning, inspired by multimodal large models. However, reliance on expensive real-world data limits progress. Simulators offer cost-effective alternatives, but the gap between simulation and reality challenges effective policy transfer. This paper introduces TwinAligner, a novel Real2Sim2Real system that addresses both visual and dynamic gaps. The visual alignment module achieves pixel-level alignment through SDF reconstruction and editable 3DGS rendering, while the dynamic alignment module ensures dynamic consistency by identifying rigid physics from robot-object interaction. TwinAligner improves robot learning by providing scalable data collection and establishing a trustworthy iterative cycle, accelerating algorithm development. Quantitative evaluations highlight TwinAligner's strong capabilities in visual and dynamic real-to-sim alignment. This system enables policies trained in simulation to achieve strong zero-shot generalization to the real world. The high consistency between real-world and simulated policy performance underscores TwinAligner's potential to advance scalable robot learning. Code and data will be released on https://twin-aligner.github.io
Challenger: Affordable Adversarial Driving Video Generation
May 21, 2025



Generating photorealistic driving videos has seen significant progress recently, but current methods largely focus on ordinary, non-adversarial scenarios. Meanwhile, efforts to generate adversarial driving scenarios often operate on abstract trajectory or BEV representations, falling short of delivering realistic sensor data that can truly stress-test autonomous driving (AD) systems. In this work, we introduce Challenger, a framework that produces physically plausible yet photorealistic adversarial driving videos. Generating such videos poses a fundamental challenge: it requires jointly optimizing over the space of traffic interactions and high-fidelity sensor observations. Challenger makes this affordable through two techniques: (1) a physics-aware multi-round trajectory refinement process that narrows down candidate adversarial maneuvers, and (2) a tailored trajectory scoring function that encourages realistic yet adversarial behavior while maintaining compatibility with downstream video synthesis. As tested on the nuScenes dataset, Challenger generates a diverse range of aggressive driving scenarios-including cut-ins, sudden lane changes, tailgating, and blind spot intrusions-and renders them into multiview photorealistic videos. Extensive evaluations show that these scenarios significantly increase the collision rate of state-of-the-art end-to-end AD models (UniAD, VAD, SparseDrive, and DiffusionDrive), and importantly, adversarial behaviors discovered for one model often transfer to others.
FB-4D: Spatial-Temporal Coherent Dynamic 3D Content Generation with Feature Banks
Mar 26, 2025With the rapid advancements in diffusion models and 3D generation techniques, dynamic 3D content generation has become a crucial research area. However, achieving high-fidelity 4D (dynamic 3D) generation with strong spatial-temporal consistency remains a challenging task. Inspired by recent findings that pretrained diffusion features capture rich correspondences, we propose FB-4D, a novel 4D generation framework that integrates a Feature Bank mechanism to enhance both spatial and temporal consistency in generated frames. In FB-4D, we store features extracted from previous frames and fuse them into the process of generating subsequent frames, ensuring consistent characteristics across both time and multiple views. To ensure a compact representation, the Feature Bank is updated by a proposed dynamic merging mechanism. Leveraging this Feature Bank, we demonstrate for the first time that generating additional reference sequences through multiple autoregressive iterations can continuously improve generation performance. Experimental results show that FB-4D significantly outperforms existing methods in terms of rendering quality, spatial-temporal consistency, and robustness. It surpasses all multi-view generation tuning-free approaches by a large margin and achieves performance on par with training-based methods.
PartRM: Modeling Part-Level Dynamics with Large Cross-State Reconstruction Model
Mar 25, 2025As interest grows in world models that predict future states from current observations and actions, accurately modeling part-level dynamics has become increasingly relevant for various applications. Existing approaches, such as Puppet-Master, rely on fine-tuning large-scale pre-trained video diffusion models, which are impractical for real-world use due to the limitations of 2D video representation and slow processing times. To overcome these challenges, we present PartRM, a novel 4D reconstruction framework that simultaneously models appearance, geometry, and part-level motion from multi-view images of a static object. PartRM builds upon large 3D Gaussian reconstruction models, leveraging their extensive knowledge of appearance and geometry in static objects. To address data scarcity in 4D, we introduce the PartDrag-4D dataset, providing multi-view observations of part-level dynamics across over 20,000 states. We enhance the model's understanding of interaction conditions with a multi-scale drag embedding module that captures dynamics at varying granularities. To prevent catastrophic forgetting during fine-tuning, we implement a two-stage training process that focuses sequentially on motion and appearance learning. Experimental results show that PartRM establishes a new state-of-the-art in part-level motion learning and can be applied in manipulation tasks in robotics. Our code, data, and models are publicly available to facilitate future research.
Training-Free Model Merging for Multi-target Domain Adaptation
Jul 18, 2024



In this paper, we study multi-target domain adaptation of scene understanding models. While previous methods achieved commendable results through inter-domain consistency losses, they often assumed unrealistic simultaneous access to images from all target domains, overlooking constraints such as data transfer bandwidth limitations and data privacy concerns. Given these challenges, we pose the question: How to merge models adapted independently on distinct domains while bypassing the need for direct access to training data? Our solution to this problem involves two components, merging model parameters and merging model buffers (i.e., normalization layer statistics). For merging model parameters, empirical analyses of mode connectivity surprisingly reveal that linear merging suffices when employing the same pretrained backbone weights for adapting separate models. For merging model buffers, we model the real-world distribution with a Gaussian prior and estimate new statistics from the buffers of separately trained models. Our method is simple yet effective, achieving comparable performance with data combination training baselines, while eliminating the need for accessing training data. Project page: https://air-discover.github.io/ModelMerging
FairDiff: Fair Segmentation with Point-Image Diffusion
Jul 08, 2024

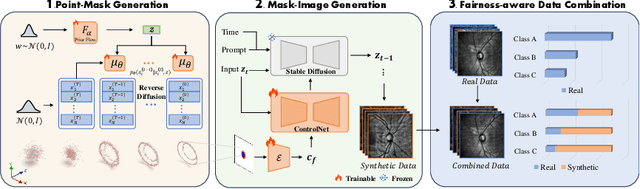

Fairness is an important topic for medical image analysis, driven by the challenge of unbalanced training data among diverse target groups and the societal demand for equitable medical quality. In response to this issue, our research adopts a data-driven strategy-enhancing data balance by integrating synthetic images. However, in terms of generating synthetic images, previous works either lack paired labels or fail to precisely control the boundaries of synthetic images to be aligned with those labels. To address this, we formulate the problem in a joint optimization manner, in which three networks are optimized towards the goal of empirical risk minimization and fairness maximization. On the implementation side, our solution features an innovative Point-Image Diffusion architecture, which leverages 3D point clouds for improved control over mask boundaries through a point-mask-image synthesis pipeline. This method outperforms significantly existing techniques in synthesizing scanning laser ophthalmoscopy (SLO) fundus images. By combining synthetic data with real data during the training phase using a proposed Equal Scale approach, our model achieves superior fairness segmentation performance compared to the state-of-the-art fairness learning models. Code is available at https://github.com/wenyi-li/FairDiff.
Luban: Building Open-Ended Creative Agents via Autonomous Embodied Verification
May 24, 2024Building open agents has always been the ultimate goal in AI research, and creative agents are the more enticing. Existing LLM agents excel at long-horizon tasks with well-defined goals (e.g., `mine diamonds' in Minecraft). However, they encounter difficulties on creative tasks with open goals and abstract criteria due to the inability to bridge the gap between them, thus lacking feedback for self-improvement in solving the task. In this work, we introduce autonomous embodied verification techniques for agents to fill the gap, laying the groundwork for creative tasks. Specifically, we propose the Luban agent target creative building tasks in Minecraft, which equips with two-level autonomous embodied verification inspired by human design practices: (1) visual verification of 3D structural speculates, which comes from agent synthesized CAD modeling programs; (2) pragmatic verification of the creation by generating and verifying environment-relevant functionality programs based on the abstract criteria. Extensive multi-dimensional human studies and Elo ratings show that the Luban completes diverse creative building tasks in our proposed benchmark and outperforms other baselines ($33\%$ to $100\%$) in both visualization and pragmatism. Additional demos on the real-world robotic arm show the creation potential of the Luban in the physical world.
SCP-Diff: Photo-Realistic Semantic Image Synthesis with Spatial-Categorical Joint Prior
Mar 14, 2024



Semantic image synthesis (SIS) shows good promises for sensor simulation. However, current best practices in this field, based on GANs, have not yet reached the desired level of quality. As latent diffusion models make significant strides in image generation, we are prompted to evaluate ControlNet, a notable method for its dense control capabilities. Our investigation uncovered two primary issues with its results: the presence of weird sub-structures within large semantic areas and the misalignment of content with the semantic mask. Through empirical study, we pinpointed the cause of these problems as a mismatch between the noised training data distribution and the standard normal prior applied at the inference stage. To address this challenge, we developed specific noise priors for SIS, encompassing spatial, categorical, and a novel spatial-categorical joint prior for inference. This approach, which we have named SCP-Diff, has yielded exceptional results, achieving an FID of 10.53 on Cityscapes and 12.66 on ADE20K.The code and models can be accessed via the project page.