 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboChemist: Long-Horizon and Safety-Compliant Robotic Chemical Experimentation
Sep 10, 2025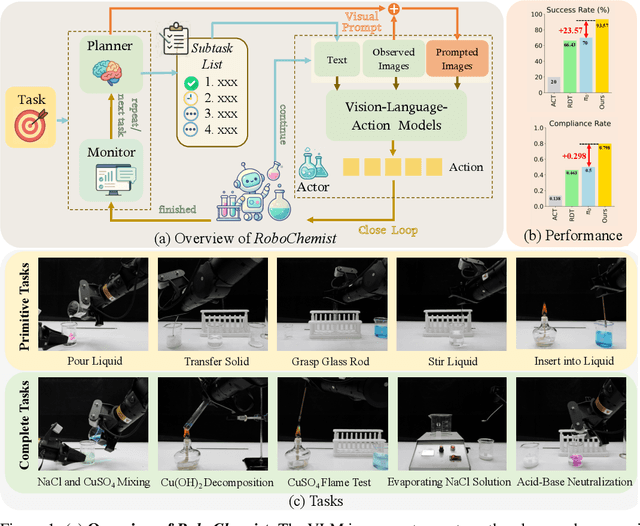



Robotic chemists promise to both liberate human experts from repetitive tasks and accelerate scientific discovery, yet remain in their infancy. Chemical experiments involve long-horizon procedures over hazardous and deformable substances, where success requires not only task completion but also strict compliance with experimental norms. To address these challenges, we propose \textit{RoboChemist}, a dual-loop framework that integrates Vision-Language Models (VLMs) with Vision-Language-Action (VLA) models. Unlike prior VLM-based systems (e.g., VoxPoser, ReKep) that rely on depth perception and struggle with transparent labware, and existing VLA systems (e.g., RDT, pi0) that lack semantic-level feedback for complex tasks, our method leverages a VLM to serve as (1) a planner to decompose tasks into primitive actions, (2) a visual prompt generator to guide VLA models, and (3) a monitor to assess task success and regulatory compliance. Notably, we introduce a VLA interface that accepts image-based visual targets from the VLM, enabling precise, goal-conditioned control. Our system successfully executes both primitive actions and complete multi-step chemistry protocols. Results show 23.57% higher average success rate and a 0.298 average increase in compliance rate over state-of-the-art VLA baselines, while also demonstrating strong generalization to objects and tasks.
TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models
Sep 09, 2025Many robotic manipulation tasks require sensing and responding to force signals such as torque to assess whether the task has been successfully completed and to enable closed-loop control. However, current Vision-Language-Action (VLA) models lack the ability to integrate such subtle physical feedback. In this work, we explore Torque-aware VLA models, aiming to bridge this gap by systematically studying the design space for incorporating torque signals into existing VLA architectures. We identify and evaluate several strategies, leading to three key findings. First, introducing torque adapters into the decoder consistently outperforms inserting them into the encoder.Third, inspired by joint prediction and planning paradigms in autonomous driving, we propose predicting torque as an auxiliary output, which further improves performance. This strategy encourages the model to build a physically grounded internal representation of interaction dynamics. Extensive quantitative and qualitative experiments across contact-rich manipulation benchmarks validate our findings.
GaussianArt: Unified Modeling of Geometry and Motion for Articulated Objects
Aug 20, 2025Reconstructing articulated objects is essential for building digital twins of interactive environments. However, prior methods typically decouple geometry and motion by first reconstructing object shape in distinct states and then estimating articulation through post-hoc alignment. This separation complicates the reconstruction pipeline and restricts scalability, especially for objects with complex, multi-part articulation. We introduce a unified representation that jointly models geometry and motion using articulated 3D Gaussians. This formulation improves robustness in motion decomposition and supports articulated objects with up to 20 parts, significantly outperforming prior approaches that often struggle beyond 2--3 parts due to brittle initialization. To systematically assess scalability and generalization, we propose MPArt-90, a new benchmark consisting of 90 articulated objects across 20 categories, each with diverse part counts and motion configurations. Extensive experiments show that our method consistently achieves superior accuracy in part-level geometry reconstruction and motion estimation across a broad range of object types. We further demonstrate applicability to downstream tasks such as robotic simulation and human-scene interaction modeling, highlighting the potential of unified articulated representations in scalable physical modeling.
Reusing Attention for One-stage Lane Topology Understanding
Jul 23, 2025Understanding lane toplogy relationships accurately is critical for safe autonomous driving. However, existing two-stage methods suffer from inefficiencies due to error propagations and increased computational overheads. To address these challenges, we propose a one-stage architecture that simultaneously predicts traffic elements, lane centerlines and topology relationship, improving both the accuracy and inference speed of lane topology understanding for autonomous driving. Our key innovation lies in reusing intermediate attention resources within distinct transformer decoders. This approach effectively leverages the inherent relational knowledge within the element detection module to enable the modeling of topology relationships among traffic elements and lanes without requiring additional computationally expensive graph networks. Furthermore, we are the first to demonstrate that knowledge can be distilled from models that utilize standard definition (SD) maps to those operates without using SD maps, enabling superior performance even in the absence of SD maps. Extensive experiments on the OpenLane-V2 dataset show that our approach outperforms baseline methods in both accuracy and efficiency, achieving superior results in lane detection, traffic element identification, and topology reasoning. Our code is available at https://github.com/Yang-Li-2000/one-stage.git.
Morpheus: A Neural-driven Animatronic Face with Hybrid Actuation and Diverse Emotion Control
Jul 22, 2025Previous animatronic faces struggle to express emotions effectively due to hardware and software limitations. On the hardware side, earlier approaches either use rigid-driven mechanisms, which provide precise control but are difficult to design within constrained spaces, or tendon-driven mechanisms, which are more space-efficient but challenging to control. In contrast, we propose a hybrid actuation approach that combines the best of both worlds. The eyes and mouth-key areas for emotional expression-are controlled using rigid mechanisms for precise movement, while the nose and cheek, which convey subtle facial microexpressions, are driven by strings. This design allows us to build a compact yet versatile hardware platform capable of expressing a wide range of emotions. On the algorithmic side, our method introduces a self-modeling network that maps motor actions to facial landmarks, allowing us to automatically establish the relationship between blendshape coefficients for different facial expressions and the corresponding motor control signals through gradient backpropagation. We then train a neural network to map speech input to corresponding blendshape controls. With our method, we can generate distinct emotional expressions such as happiness, fear, disgust, and anger, from any given sentence, each with nuanced, emotion-specific control signals-a feature that has not been demonstrated in earlier systems. We release the hardware design and code at https://github.com/ZZongzheng0918/Morpheus-Hardware and https://github.com/ZZongzheng0918/Morpheus-Software.
DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
May 26, 2025Research interest in end-to-end autonomous driving has surged owing to its fully differentiable design integrating modular tasks, i.e. perception, prediction and planing, which enables optimization in pursuit of the ultimate goal. Despite the great potential of the end-to-end paradigm, existing methods suffer from several aspects including expensive BEV (bird's eye view) computation, action diversity, and sub-optimal decision in complex real-world scenarios. To address these challenges, we propose a novel hybrid sparse-dense diffusion policy, empowered by a Vision-Language Model (VLM), called Diff-VLA. We explore the sparse diffusion representation for efficient multi-modal driving behavior. Moreover, we rethink the effectiveness of VLM driving decision and improve the trajectory generation guidance through deep interaction across agent, map instances and VLM output. Our method shows superior performance in Autonomous Grand Challenge 2025 which contains challenging real and reactive synthetic scenarios. Our methods achieves 45.0 PDMS.
FB-4D: Spatial-Temporal Coherent Dynamic 3D Content Generation with Feature Banks
Mar 26, 2025With the rapid advancements in diffusion models and 3D generation techniques, dynamic 3D content generation has become a crucial research area. However, achieving high-fidelity 4D (dynamic 3D) generation with strong spatial-temporal consistency remains a challenging task. Inspired by recent findings that pretrained diffusion features capture rich correspondences, we propose FB-4D, a novel 4D generation framework that integrates a Feature Bank mechanism to enhance both spatial and temporal consistency in generated frames. In FB-4D, we store features extracted from previous frames and fuse them into the process of generating subsequent frames, ensuring consistent characteristics across both time and multiple views. To ensure a compact representation, the Feature Bank is updated by a proposed dynamic merging mechanism. Leveraging this Feature Bank, we demonstrate for the first time that generating additional reference sequences through multiple autoregressive iterations can continuously improve generation performance. Experimental results show that FB-4D significantly outperforms existing methods in terms of rendering quality, spatial-temporal consistency, and robustness. It surpasses all multi-view generation tuning-free approaches by a large margin and achieves performance on par with training-based methods.
PartRM: Modeling Part-Level Dynamics with Large Cross-State Reconstruction Model
Mar 25, 2025As interest grows in world models that predict future states from current observations and actions, accurately modeling part-level dynamics has become increasingly relevant for various applications. Existing approaches, such as Puppet-Master, rely on fine-tuning large-scale pre-trained video diffusion models, which are impractical for real-world use due to the limitations of 2D video representation and slow processing times. To overcome these challenges, we present PartRM, a novel 4D reconstruction framework that simultaneously models appearance, geometry, and part-level motion from multi-view images of a static object. PartRM builds upon large 3D Gaussian reconstruction models, leveraging their extensive knowledge of appearance and geometry in static objects. To address data scarcity in 4D, we introduce the PartDrag-4D dataset, providing multi-view observations of part-level dynamics across over 20,000 states. We enhance the model's understanding of interaction conditions with a multi-scale drag embedding module that captures dynamics at varying granularities. To prevent catastrophic forgetting during fine-tuning, we implement a two-stage training process that focuses sequentially on motion and appearance learning. Experimental results show that PartRM establishes a new state-of-the-art in part-level motion learning and can be applied in manipulation tasks in robotics. Our code, data, and models are publicly available to facilitate future research.
Chameleon: Fast-slow Neuro-symbolic Lane Topology Extraction
Mar 10, 2025Lane topology extraction involves detecting lanes and traffic elements and determining their relationships, a key perception task for mapless autonomous driving. This task requires complex reasoning, such as determining whether it is possible to turn left into a specific lane. To address this challenge, we introduce neuro-symbolic methods powered by vision-language foundation models (VLMs). Existing approaches have notable limitations: (1) Dense visual prompting with VLMs can achieve strong performance but is costly in terms of both financial resources and carbon footprint, making it impractical for robotics applications. (2) Neuro-symbolic reasoning methods for 3D scene understanding fail to integrate visual inputs when synthesizing programs, making them ineffective in handling complex corner cases. To this end, we propose a fast-slow neuro-symbolic lane topology extraction algorithm, named Chameleon, which alternates between a fast system that directly reasons over detected instances using synthesized programs and a slow system that utilizes a VLM with a chain-of-thought design to handle corner cases. Chameleon leverages the strengths of both approaches, providing an affordable solution while maintaining high performance. We evaluate the method on the OpenLane-V2 dataset, showing consistent improvements across various baseline detectors. Our code, data, and models are publicly available at https://github.com/XR-Lee/neural-symbolic
Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty
Aug 27, 2024
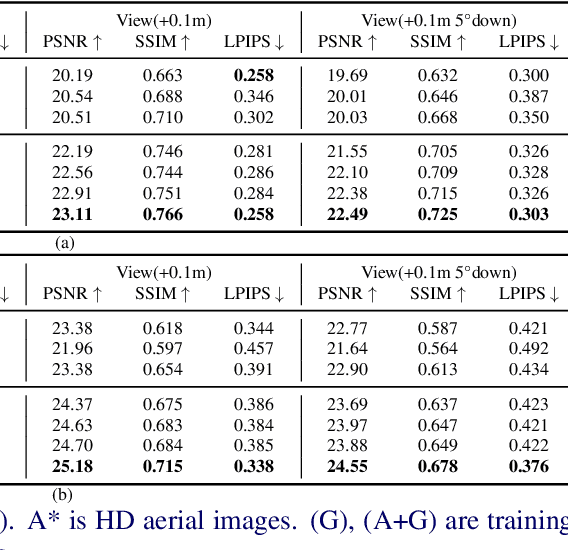
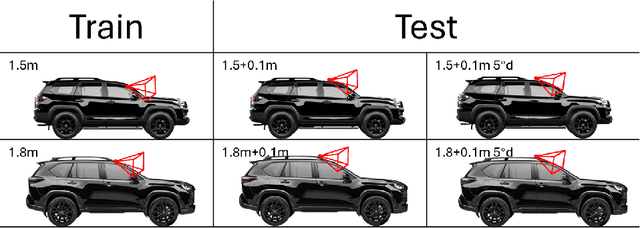
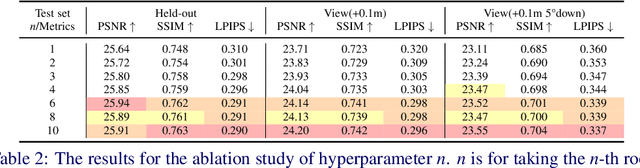
Robust and realistic rendering for large-scale road scenes is essential in autonomous driving simulation. Recently, 3D Gaussian Splatting (3D-GS) has made groundbreaking progress in neural rendering, but the general fidelity of large-scale road scene renderings is often limited by the input imagery, which usually has a narrow field of view and focuses mainly on the street-level local area. Intuitively, the data from the drone's perspective can provide a complementary viewpoint for the data from the ground vehicle's perspective, enhancing the completeness of scene reconstruction and rendering. However, training naively with aerial and ground images, which exhibit large view disparity, poses a significant convergence challenge for 3D-GS, and does not demonstrate remarkable improvements in performance on road views. In order to enhance the novel view synthesis of road views and to effectively use the aerial information, we design an uncertainty-aware training method that allows aerial images to assist in the synthesis of areas where ground images have poor learning outcomes instead of weighting all pixels equally in 3D-GS training like prior work did. We are the first to introduce the cross-view uncertainty to 3D-GS by matching the car-view ensemble-based rendering uncertainty to aerial images, weighting the contribution of each pixel to the training process. Additionally, to systematically quantify evaluation metrics, we assemble a high-quality synthesized dataset comprising both aerial and ground images for road scenes.